https|陈丹琦带着清华特奖学弟发布新成果:打破谷歌BERT提出的训练规律
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
新晋斯隆奖得主如何庆祝?
公开最新研究成果算不算?
就在斯隆奖宣布当天,陈丹琦团队展示了最新的研究成果。
团队发现,经典NLP模型BERT提出的预训练“15%掩蔽率”法则,是可以被打破的!
“15%掩蔽率”,指在一项预训练任务中,随机遮住15%的单词,并通过训练让AI学会预测遮住的单词。
陈丹琦团队认为,如果将掩蔽率提升到40%,性能甚至比15%的时候还要更好:

文章插图
不仅如此,这篇文章还提出了一种新的方法,来更好地提升40%掩蔽率下NLP模型训练的效果。
一位抱抱脸(Hugging Face)工程师对此表示:
关于BERT有个很有意思的事情,它虽然是一项开创性的研究,然而它的那些训练方式都是错误或不必要的。
文章插图
这篇论文的共同一作高天宇,也是清华特奖获得者,本科期间曾发表过四篇顶会论文。
那么,论文究竟是怎么得出这一结论的呢?
“大模型更适合高掩蔽率”陈丹琦团队先是从掩蔽率、迭代次数和模型大小三个方向,验证了这一结论。
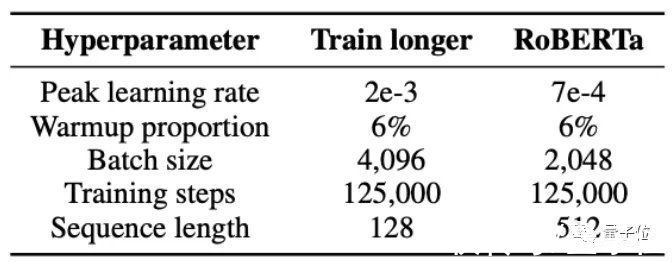
他们先是用了一系列不同的掩蔽率来训练NLP模型,参数如下:
文章插图
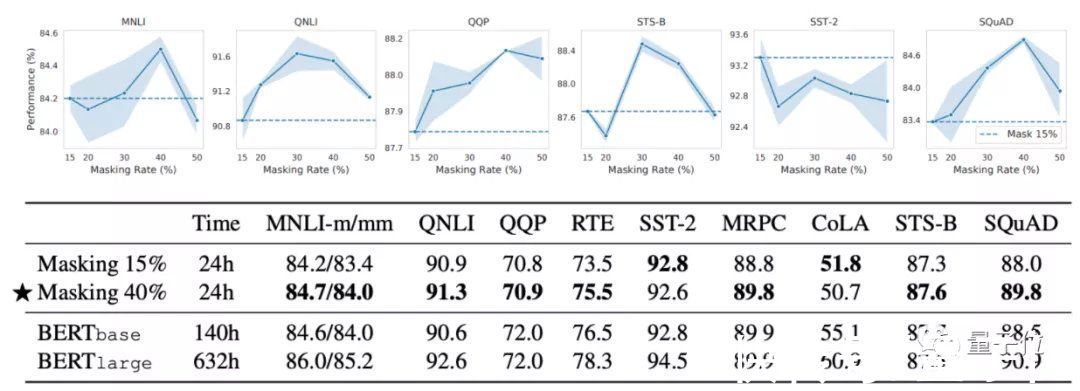
结果发现,除了小部分数据集以外,模型在包括MNLI、QNLI、QQP、STS-B、SQuAD等数据集上的训练效果,40%掩蔽率都比15%都要更好。
文章插图
为了进一步迭代次数 (training step)受掩蔽率的影响效果,作者们同样记录了不同迭代率下模型的效果。
结果显示,随着迭代次数的增加,40%掩蔽率基本都表现出了比15%更好的性能:

文章插图
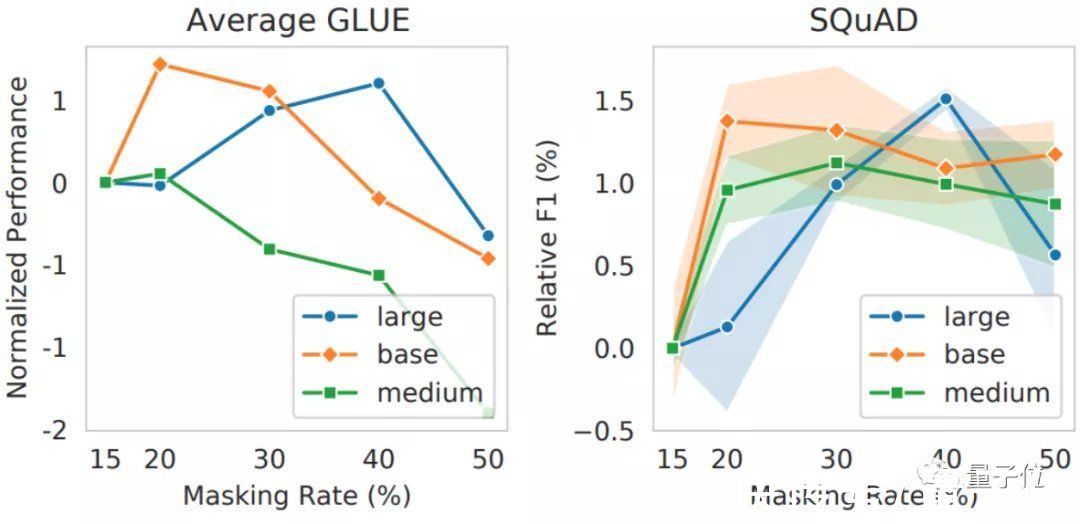
不仅如此,作者们还发现,更大的模型,更适合用40%掩蔽率去训练。
结果显示,大模型在40%掩蔽率的情况下,性能比中等NLP模型要更好:
文章插图
这么看来,只将掩蔽率设置为15%,确实没有40%的训练效果更好,而且,更大的NLP模型还更适合用40%的掩蔽率来训练。
团队猜测,任务难一些能促使模型学到更多特征,而大模型正是有这种余裕。
为了探究其中的原理,作者们又提出了一个新的评估方法。
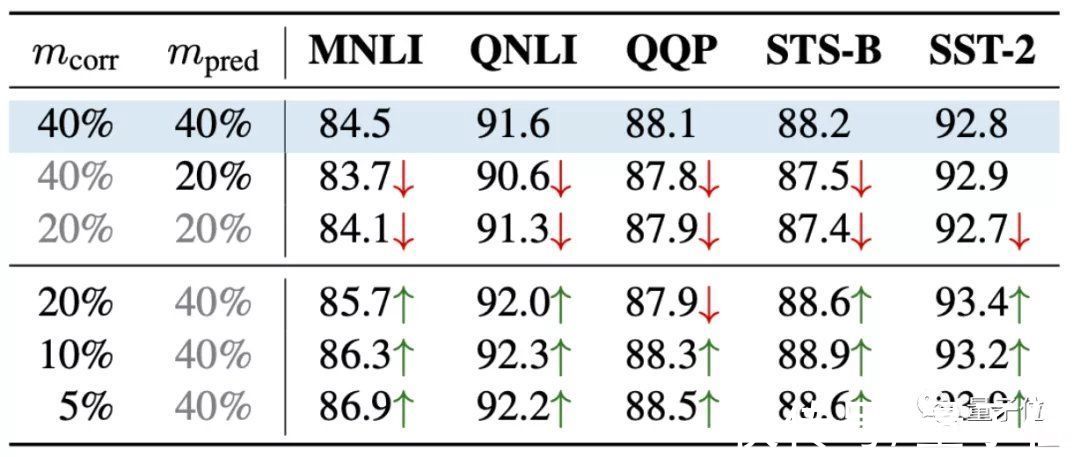
将掩蔽率拆分为2个指标具体来说,就是将掩蔽率拆分为破坏率 (corruption rate)和预测率 (prediction rate)2个指标。
其中,破坏率是句子被破坏的比例,预测率是模型预测的比例。
例如,“我喜欢打篮球”语料可能被破坏成“我[MASK][MASK][MASK]”提供给模型,但模型却只需要预测第一个[MASK]是不是“喜欢”。
这样一来,就可以用破坏率来控制预训练任务的难度,用预测率来控制模型的优化效果。
论文进一步针对破坏率(mcorr)和预测率(mpred)进行了研究,发现了一个新规律:
预测率高,模型效果更好;但破坏率更高,模型效果更差:
文章插图
这样就能用更精准的方式来评估各种预训练任务了。
最后,作者们在这种指标下,测试了多种掩码,观察在更高掩蔽率的情况下,哪些掩码的效果更好。
结果显示,随着掩蔽率的提升,随机均匀掩码的效果(Uniform)的表现还会比Span Masking、相关区间原则性掩码(PMI-Masking)更好。
- https|9个压箱底的宝藏网站,个个都是黑科技的代表,请悄悄地收藏
- JK少女:带着那份甜蜜奔向你
- 带着Z 6Ⅱ和Z 28mm f/2.8捕捉街头精彩瞬间
- 显卡|我第一台电脑的显卡是,FX5200,它带着我踏上泰达希尔
- 原创|老师带着七台电脑来维修,结账时却只付一台钱,气得我扣下两台!
- 显示器|Doomscroll 永远带着超高 5: 16 便携式显示器
- 如果被鲸鱼吞下,身上恰好带着一把刀,可以划开肚子逃生吗?
- 带着“技术人员”跑了?挑选人才移民美国,拜登到底在怕啥?
- https|机器人首次独立手术!最快55分钟缝合肠道,“结果优于外科医生”
- https|Waymo起诉加州车管所,要求对无人车事故数据保密