编辑导读:数据挖掘是指从大量的、不完全的、有噪声的、模糊的、随机的数据中通过算法搜索隐藏于其中信息的过程。本文作者围绕数据挖掘展开分析,希望对你有帮助。

文章插图
豆豆和花花开了一家鲜花店。豆豆跟花花说:“情人节快到了,咱店都需要准备哪类情人节花束?每类花束需要准备多少?……” 花花回答道,“根据顾客分类,大致分为自信示爱、甜蜜上心、星河挚爱等共8类。前三类去年卖地特别好,今年需要提供比上年多30%的花束……”。豆豆说:“鲜花的保质期特别短,所以,多购买的鲜花只能从30%降至10%,既可以控制成本,又可以积攒口碑……”
在上面案例中,花花制定采购方案首先进行顾客分类,在数据挖掘领域,可以使用无监督模型(例如k-means),也可以使用分类模型(例如KNN、决策树、逻辑回归等)将用户分群。花花预估“今年需要提供比上一年高30%的花束”,在数据挖掘领域,可以使用回归模型进行预测。
接下来,笔者就跟你浅谈一下数据挖掘。
01 机器学习与数据挖掘的区别与联系1.1 概念首先,我们对机器学习和数据挖掘的定义做一下总结:数据挖掘是指从大量的、不完全的、有噪声的、模糊的、随机的数据中通过算法搜索隐藏于其中信息的过程。换句话说,数据挖掘试图从海量数据中找到有用的信息。
机器学习是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。也就是说,机器学习就是将现实生活中的问题抽象成数学模型,利用数学方法对这个数学模型进行求解,从而解决现实生活中的问题。
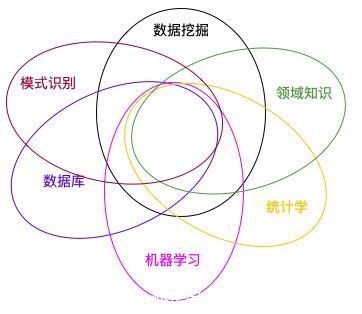
1.2 联系与区别1.2.1 联系数据挖掘受到很多学科领域的影响,其中包括数据库、机器学习、统计学、领域知识及模式识别等领域。简而言之,对于数据挖掘,数据库提供数据存储技术,机器学习和统计学提供数据分析技术。
文章插图
统计学经常忽视实际的效用醉心于理论的优美,因此,统计学提供的大部分技术都要在机器学习领域进一步研究,变成机器学习算法后才能进入数据挖掘领域。从这方面来讲,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑。简言之,机器学习为数据挖掘提供解决实际问题的方法,数据挖掘中算法的成功应用,说明了机器学习对算法的研究具有实际运用价值。
1.2.2 区别
从数据分析来讲,大多数数据挖掘技术都是来自于机器学习,但是机器学习研究不把海量数据作为处理对象,因此,数据挖掘需要对算法进行改造,使得算法性能和空间占用达到实用的地步。同时,数据挖掘还有自身独特的内容——关联分析。
至于,数据挖掘和模式识别,从概念上区分,数据挖掘重在发现知识,模式识别重在认识事物。
简言之,机器学习注重相关机器学习算法的理论研究和算法提升,更偏向理论和学术;数据挖掘注重运用算法或者其他某种模式解决实际问题,更偏向实践和运用。
02 机器学习的分类机器学习的方法是基于数据产生的“模型”的算法,也称为“学习算法”。机器学习方法包括有监督学习、无监督学习、半监督学习和强化学习。
文章插图
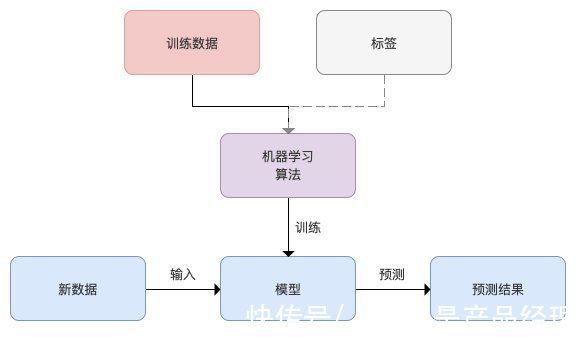
2.1 有监督学习有监督学习指对数据的若干特征与标签之间的关联性进行建模的过程。它的主要目标是从有标签的训练数据中学习模型,以便对未知或未来的数据做出预测。以用户是否会复购鲜花为例,可以采用监督学习算法在打过标签的(正确标识是与否)数据上训练模型,然后用该模型来预测新用户是否属于粘性用户。
- 带货|揭秘爆款带货短视频的套路|超干货,值得收藏
- 2月10日|《极限竞速:地平线5》国内玩家分享游戏中出现的各式涂装
- 干货在这里!荆州公安纪律作风专项整治动员会精神
- MySQL|策划经理都在用的神器,一次分享出来了!
- 客单价|占豪干货:付费和收费,才是最好链接人脉的方式
- 自媒体|自媒体公众号写作注意事项(干货)(我自己的实战经验)
- 高颜小巧充电快!南卡C2双口快充头分享体验
- 阿迪达斯|阿迪达斯因在Twitter上分享露骨图片以推广运动胸罩而受到批评
- 微信|培训机构类微信公众号变现的七大手段(实战干货)
- 工业互联网|阿迪达斯因在Twitter上分享露骨图片以推广运动胸罩而受到批评