标签为离散值的监督学习任务称为「分类任务」,例如上述的用户是否会复购鲜花示例。常用的分类模型包括KNN、决策树、逻辑回归等。
标签为连续值的监督学习任务称为「回归任务」,例如根据历史数据预测未来的销售额。常用的回归模型为线性回归、非线性回归和岭回归等。
注意:机器学习领域的预测变量通常称为特征,而响应变量通常称为目标变量或标签。
2.2 无监督学习无监督学习指对不带任何标签的数据特征进行建模,通常被看成是一种“让数据自己介绍自己”的过程。也就是说,用无监督学习,可以在没有目标变量或奖励函数的指导下,探索数据结构来提取有意义的信息。这类模型包括「聚类任务」和「降维任务」。其中,聚类算法可以将数据分成不同的组别,而降维算法追求用更简洁的方式表现数据。
2.3 半监督学习半监督学习方法介于有监督学习和无监督学习之间,通常在数据不完整时使用。
2.4 强化学习强化学习不同于监督学习,它将学习看作是试探评价过程,以“试错”的方式进行学习,并与环境交互已获得奖惩指导行为,以其作为评价。也就是说,强调如何基于环境而行动,以取得最大化的预期利益。此时,系统靠自身的状态和动作进行学习,从而改进行动方案以适应环境。
03 数据挖掘建模过程从数据本身来考虑,数据挖掘建模过程通常需要有理解商业、理解数据、准备数据、建模型、评估模型和部署模型6个步骤。
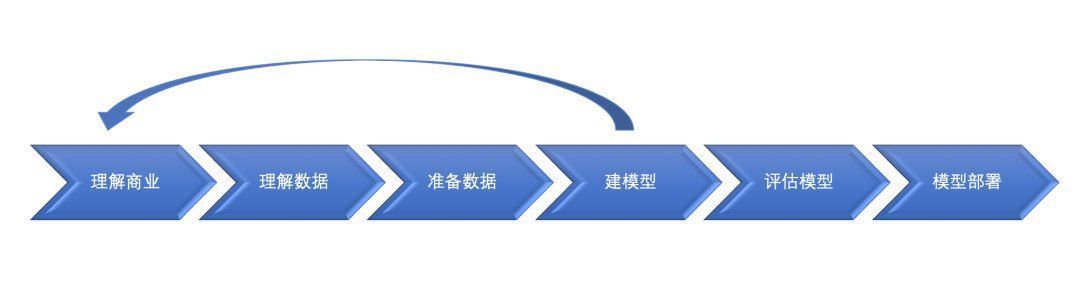
文章插图
3.1 理解商业理解商业算是数据挖掘中最重要的一部分,在这个阶段我们需要明确商业目标、评估商业环境、确定挖掘目标以及产生一个项目计划。简单地说,就是针对不同的业务场景,需要明白挖掘的目标是什么,需要达到什么样的效果。用大白话讲,就是你到底想干啥。
仍以鲜花店为例,为了提高销售额,店员可以帮助客户快速找到他感兴趣的花束,同时在保证用户体验的情况下,为其附加一个可接受的小饰品,比如花瓶、零食、香水等。
3.2 理解数据数据是挖掘过程的“原材料”,在数据理解过程中我们需要了解都有哪些数据,这些数据的特征是什么,可以通过对数据进行描述分析得到数据的特点。其中,了解有哪些数据尤为重要,其决定了后期工作进展的顺利程度。比如和花店有关的数据:
1)鲜花数据:鲜花名称、鲜花品类、采购时间、采购数量、采购金额等。
2)经营数据:经营时间、预定时间、预定品类、预定人数等。
3)其他数据:是否为节假日、用户口碑、竞争对手动向、天气情况等。
3.3 准备数据【 花束|干货分享:数据挖掘浅谈】在数据准备阶段我们需要对数据作出清洗、重建、合并等操作。选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作。主要是为建模准备数据,可以从数据预处理、特征提取、特征选择等几方面出发,整理如下:1)缺失值:由于个人隐私或设备故障导致某些观测值在某些纬度上的漏缺,通常称为缺失值。缺失值存在可能会导致模型结果的错误,所以针对缺失值可以考虑删除、众数或均值填充等解决。
2)异常值:由于远离正常样本的观测点,它们的存在同样会对模型的准确型造成影响。可以通过象限图或3sigma(正态分布)进行判断,如果是,可以考虑删除或单独处理。
3)量纲不一致:模型容易受到不同量纲的影响,因此需要通过标准化方法(通常采用归一化、Normalization之类的方法)将数据进行转换。
- 带货|揭秘爆款带货短视频的套路|超干货,值得收藏
- 2月10日|《极限竞速:地平线5》国内玩家分享游戏中出现的各式涂装
- 干货在这里!荆州公安纪律作风专项整治动员会精神
- MySQL|策划经理都在用的神器,一次分享出来了!
- 客单价|占豪干货:付费和收费,才是最好链接人脉的方式
- 自媒体|自媒体公众号写作注意事项(干货)(我自己的实战经验)
- 高颜小巧充电快!南卡C2双口快充头分享体验
- 阿迪达斯|阿迪达斯因在Twitter上分享露骨图片以推广运动胸罩而受到批评
- 微信|培训机构类微信公众号变现的七大手段(实战干货)
- 工业互联网|阿迪达斯因在Twitter上分享露骨图片以推广运动胸罩而受到批评