为迎接超大模型时代,Meta 想要打造“全球最快 AI 超算”( 二 )

文章插图
2020年初,Facebook 团队认为当时公司的超算集群难以跟上未来大模型训练的需要,决定“重新出发”,采用最顶尖的 GPU 和数据传输网络技术,打造一个全新的集群。
这台新的超算,必须能够在大小以 EB(超过10亿GB)为单位的数据集上,训练具有超过万亿参数量的超大神经网络模型。
(例如,中国科研机构智源 BAAI 开发的“悟道”,以及谷歌去年用 Switch Transformer 技术训练的混合专家系统模型,都是参数量达到万亿级别的大模型;相比来看,此前在业界非常著名的 OpenAI GPT-3 语言模型,性能和泛用性已经非常令人惊讶,参数量为1750亿左右。)
Meta 团队选择了三家在 AI 计算和数据中心组件方面最知名的公司:英伟达、Penguin Computing,和 Pure Storage。
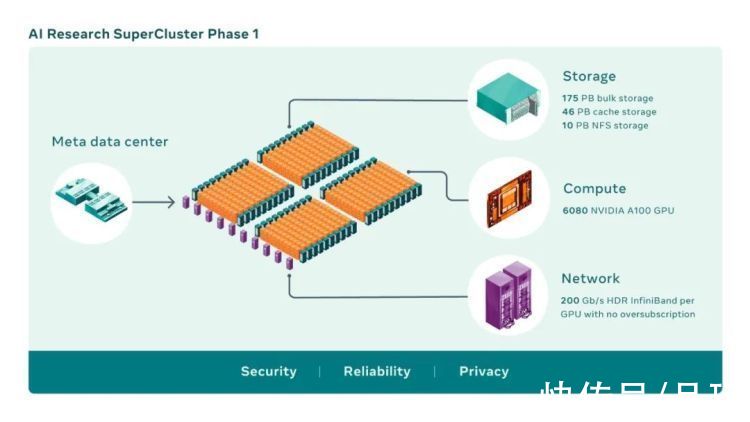
具体来说,Meta 直接从英伟达采购了760台 DGX 通用训练系统。这些系统包含共计6080块 Ampere 架构 Tesla A100 Tensor 核心 GPU,在当时,乃至今天,都是最顶级的 AI 训练、推理、分析三合一系统。中间的网络通信则采用了英伟达 InfiniBand,数据传输速度高达200GB每秒。
存储方面,Meta 从 Pure Storage 采购了共计 231PB 的闪存阵列、模块和缓存容量;而所有的机架搭建、设备安装和数据中心的后续管理工作,则由从 Facebook 时代就在服务该公司的 Penguin Computing 负责。
这样组建出来的新超算集群,Meta 将其正式命名为 AI RSC:
文章插图
相较于之前 FAIR 采用 V100 显卡搭建的计算集群,初代 RSC 对于生产级别的计算机视觉类算法带来了20倍的性能提升,运行英伟达多卡通讯框架的速度提升了超过9倍,对于大规模自然语言处理类 workflow 的训练速度也提升了3倍——节约的训练时间以周为单位。
值得一提的是,在 Meta 刚刚做好 RSC 升级计划的时候,新冠疫情突然袭来了。所有实体建造的工期都遇到了极大的不确定性,RSC 能否成功升级换代,打上了一个巨大的问号。
然而,公司业务发展和 AI 科研的需要,无法等待新冠疫情。负责 RSC 升级和建造的团队,以及包括英伟达、Penguin Computing、Pure Storage 等三家硅谷公司在内的技术合作方,不得不在极大的工期压力下,完成数据中心的装修建设、设备的生产和运输、现场装机、布线、调试等一系列非常繁琐和技术要求极高的工作。
【 为迎接超大模型时代,Meta 想要打造“全球最快 AI 超算”】更夸张的是由于当时全美各地都有居家隔离令,整个 RSC 项目团队的多位负责人,都不得不在家中远程工作……团队里的研究员 Shubho Sengupta 表示,“最让我感到骄傲的是,我们在完全远程办公的条件下完成了(RSC 的升级工作)。考虑到项目的复杂性,完全没有和其它团队成员见面就能把这些事都办了,简直太疯狂了”
文章插图
就目前来看,RSC 已经是世界上运行速度最快的 AI 超级计算机之一了。
但是 Meta 仍不满足。
打造全球最快、最安全的 AI 超算为了满足 Meta 在生产环境和 AI 研究这两大方面日益增长的算力需求,RSC 必须持续升级扩容。
按照 Meta 的 RSC 第二阶段(P2)计划,到今年7月,也即半年之内,整个计算集群的 A100 GPU 总数提升到惊人的1.6万块……
初代 RSC 采用的 DGX A100 单机数量是760台,折合6,080张显卡——这样计算的话,也就是说 RSC 将在 P2 再增加9,920张显卡,即 Meta 需要再从英伟达采购1,240台 DGX A100 超级计算机……
- 华为p50|被袁咏仪的新年礼物酸到了 华为P50 Pocket到底有什么魔力
- 京东超市发布“2021中国十大老字号”榜单 稻香村、同仁堂、五
- 本文转自:北方网1月24日|天津联通开通首批超千兆FTTR全光组网服务
- fMeta 为开发中地区提供的“免费”互联网服务被发现持续向用户收费
- 防御能力|什么样的WAF,才有可能成为用户的最佳选择?
- 华为|中国手机市场份额排名:vivo第一、OPPO第二
- QQ内测超级QQ秀:人物变3D形象 可DIY外形
- 天玑1200|超越神U骁龙870!联发科天玑1300首度曝光
- 管理|北森纪伟国:HR软件从为"HR管理而设计"走向“为员工而设计”|探路2022
- 攻击|华为云春节前夕遭连续偷袭!密谋3个月,专挑凌晨断网