指数|智源NLP重大研究方向发布“智源指数”,全面系统评测机器中文语言能力( 二 )
为了更好地去支持智源指数的发展,智源研究院搭建了「智源指数工作委员会」,由孙茂松担任主任,穗志方和杨尔弘担任副主任。目前,委员会单位已经吸纳了国内在自然语言处理方面10余家优势单位,接近20个相关优势研究组,去针对智源指数不断进行改进,力求更加科学、规范、高质量地推进中文自然语言处理技术的标准评测。
对此,清华大学教授、中国人工智能学会理事长戴琼海院士评价说:“祝贺孙茂松教授带领智源NLP学者共同建立了机器中文语言能力评测基准智源指数,这对中文信息处理乃至我国人工智能的发展具有重要的里程碑意义。”
二、穗志方:NLP评测中的问题与对策在智源学者成果报告会环节,北京大学穗志方教授分享了NLP评测中的问题与对策。
他谈到NLP评测中存在的问题涉及评测的规范性、效率、指标、周期、数据集及任务等。
首先,评测缺乏一定规范性。这致使评测的准入门槛非常低,评测数量过多而质量参差不齐,研究者们往往采用对自己的模型最有利的数据集,并声称达到了最好结果,这导致后续研究者难以客观地比较和超越,使得公众难以把握当前领域的真实研究水平。
第二,评测效率衰退。面对参数量越来越大的模型,大部分现有评测任务已经无法明显区分人类水平和机器表现。大部分评测在短时间内失去了效力,这被称之为评测效力衰退。
第三,评测生命周期非常短。部分评测数据集提出后不久,最好的机器模型得分就超过了人类基准。评测系统过快失去效力,缺少生命力。
NLP评测的是语言能力还是语言表现,这是一个比较深刻的问题。周期短、效力衰退仅仅是语言上的一种表现,语言能力如何去真正评估机器的语言能力,我们需要评测的是机器的语言能力,而不仅仅是表层的一种行为临时的呈现。
另一个问题是通用的NLP评测。通用的NLP评测是否能够完整、综合、系统的考察机器理解与语言处理的综合能力?我们看到的是综合性汇总,综合性评测可能并不是综合,只是简单的数据聚合,各任务之间缺乏有机关联,各个任务没有真正结合成一个系统,缺乏一个系统性的体系。
评测技术单一,为什么机器模型在短期内可以达到比较高的水平?有一部分原因是因为评测技术,仅仅依托于固定的训练集、测试集和开发集,一成不变的数据集很容易被机器模型学会、突破,导致评测的生命周期非常短。所以,评测技术方面还有待进一步突破。
三、10余项丰硕成果,智源NLP研究方向探索与落地并重本次技术开放日中还进行了“自然语言处理评测中的问题与对策”、“迈向通用连续型知识库”、“文本复述生成”等研究成果的阶段性汇报,内容涵盖预训练模型、知识计算、人机对话、文本生成等10余项重点NLP科研问题。
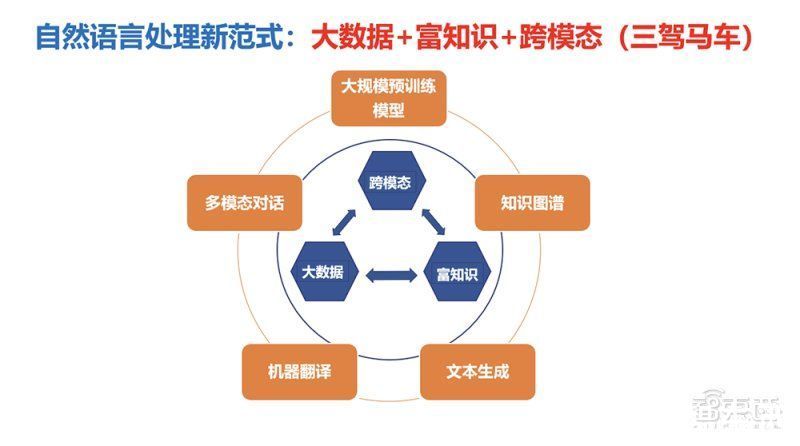
在智源研究院的支持下,自然语言处理重大研究方向学者团队积极探索自然语言处理新格局,通过大数据与富知识双轮驱动,并通过与跨模态信息进行交互,显著提升以自然语言为核心的中文语义理解与生成能力。
文章插图
落地应用方面,清华大学教授、智源研究员李涓子团队构建的“多模态北京旅游知识图谱”可以为路径规划和景点信息查询等功能提供数据支持,为游客进行旅游行程的规划。
京东集团副总裁、智源研究员何晓冬博士团队针对大规模与训练语言模型在长文本理解任务上的不足,通过从局部视角到全局视角的重复阅读方法(Read-over-Read,RoR),提出了一种基于多视角的机器阅读理解模型,显著地提高了针对长文本的阅读理解能力。
- 租车行业中国顾客推荐指数(C-NPS)发布 神州租车排名第一
- 指数|恒生科技指数跌超1%,京东、B站跌超3%
- 恒生科技|恒生科技指数涨幅扩大至5%,京东集团涨超10%
- 微软|京东探索研究院NLP水平超越微软 织女Vega v1模型位居GLUE榜首
- 1月7日-1月9日成都体育锻炼适宜指数预报来了
- 指数|恒生科技指数跌超4%,B站、美团跌超9%
- 未来一周天气情况1月3日-1月9日未来一周天象信息新月 0.|星星故乡 | 本周星空指数发布(1月3日-1月9日)
- 京东探索研究院NLP水平超越微软 织女Vega v1模型位居GLUE榜首
- 语言能力|中文语言能力评测基准「智源指数」问世:覆盖17种主流任务,19个代表性数据集,更全面、更均衡
- 指标体系|长沙高新区布局数字产业 首发先进计算产业发展指数