指数|智源NLP重大研究方向发布“智源指数”,全面系统评测机器中文语言能力

文章插图
智东西(公众号:zhidxcom)
作者 | ZeR0
编辑 | 漠影
智东西1月4日报道,上周四(12月30日),在北京智源人工智能研究院自然语言处理重大研究方向前沿技术开放日上,北京智源人工智能研究院(以下简称“智源研究院”)发布大模型评测的“命题”新方案——智源指数。
NLP是智源重大学术研究方向之一,由清华大学孙茂松教授任该方向首席科学家,北京语言大学杨尔弘教授任项目经理,学者包括李涓子、穗志方、刘洋、万小军、何晓冬,青年科学家包括刘知远、韩先培、孙栩、严睿、张家俊、赵鑫、杨植麟、李纪为等。
除了发布智源指数外,本次技术开放日期间,24位自然语言处理(NLP)学术专家,20多项前沿报告、10余项最新研究成果“组团”亮相。
一、智源指数CUGE:面向大模型的多层次、多维度评测方案据清华大学副教授、智源青年科学家、智源指数建设骨干成员刘知远介绍,智源指数CUGE(全称为Chinese Language Enderstanding and Generation Evaluation)是一个全面均衡的机器中文语言能力评测基准,在全面系统的评测体系基础上建立了多层次、多维度的评测方案。

文章插图
CUGE网站链接:cuge.baai.ac.cn
技术报告链接:arxiv.org/pdf/2112.13610.pdf
代码链接:github.com/TsinghuaAI/CUGE
在基准框架上,不同于传统将常用数据集扁平组织的方式,智源指数根据人类语言考试大纲和当前NLP研究现状,以语言能力-任务-数据集的分层框架来选择和组织数据集,涵盖7种重要语言能力、17个主流NLP任务和19个代表性数据集,全面均衡,避免“偏科选拔”。

文章插图
智源指数CUGE框架
在评分策略上,参考现有评测方案优缺点,智源指数构建了一个多层次的评测方案,能更好展现模型不同维度的模型语言智能差异:依托能力-任务-数据集层次性基准框架,提供不同层次的模型性能评分,系统性大大加强。
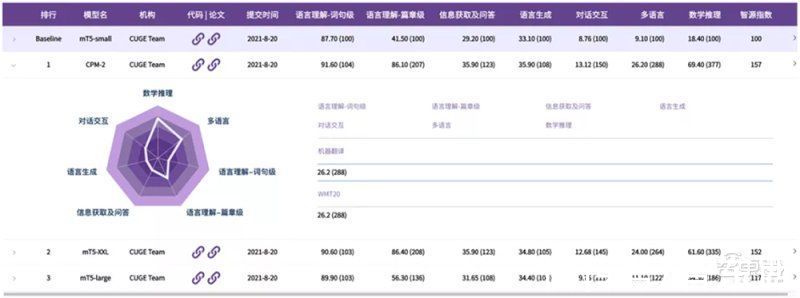
智源指数会提供一个参与者模型的性能排行榜,该排行榜充分吸收了国内外相关评测基准的特点,构建出了一个具有相应特色。
第一,排行榜基于能力-任务-数据集体系,会给每一个数据集所对应的标签,方便参与者筛选出感兴趣的能力或角度,进行相应的评测。
【 指数|智源NLP重大研究方向发布“智源指数”,全面系统评测机器中文语言能力】第二,基于标签体系,支持参与者通过标签筛选的方式定制排行榜。同时官方也会提供若干代表推荐套餐,如精简榜等,更加方便地让参与者利用其平台开展有针对性的能力评测。
第三,根据7种重要语言能力呈现雷达图,直观反映不同模型在不同能力上提升的效果。
第四,平台同时会支持单数据集的排行榜和评测,更加有利于参与者去追踪数据集研究的进展和动态。也就是说,任何一个单个数据集,都可以看到相关评测效果的榜单。
文章插图
“我们希望以学术的视角构建智源指数,让它回归我们本身构造这种评测基准的初心,不是变成刷榜的行为。”刘知远认为,专门针对榜做优化,并不意味着大模型在应用场景中获得很好的效果,这种行为没有意义,反而会浪费非常大的算力和时间。
智源指数会每年定期吸纳新的优秀数据集加入到智源指数的计算中来,同时所有的提交者必须填写Honor Code并展示,不人工干预数据预训练和测试过程。未来智源也计划依托智源研究院、智源社区的力量,提供用户面向数据集和评测结果的反馈意见、讨论机制,通过交互交流来去构建起中文高质量数据集社区的机制,来推动中文的自然语言处理的发展。
- 租车行业中国顾客推荐指数(C-NPS)发布 神州租车排名第一
- 指数|恒生科技指数跌超1%,京东、B站跌超3%
- 恒生科技|恒生科技指数涨幅扩大至5%,京东集团涨超10%
- 微软|京东探索研究院NLP水平超越微软 织女Vega v1模型位居GLUE榜首
- 1月7日-1月9日成都体育锻炼适宜指数预报来了
- 指数|恒生科技指数跌超4%,B站、美团跌超9%
- 未来一周天气情况1月3日-1月9日未来一周天象信息新月 0.|星星故乡 | 本周星空指数发布(1月3日-1月9日)
- 京东探索研究院NLP水平超越微软 织女Vega v1模型位居GLUE榜首
- 语言能力|中文语言能力评测基准「智源指数」问世:覆盖17种主流任务,19个代表性数据集,更全面、更均衡
- 指标体系|长沙高新区布局数字产业 首发先进计算产业发展指数