自2012年以来,人工智能训练任务所需求的算力每3.43个月就会翻倍,大大超越了芯片产业长期存在的摩尔定律(每 18个月芯片的性能翻一倍)。
深度学习需要处理海量数据,并进行大量简单运算,对于并行计算有较高的要求。而GPU的优势就在于,第一核数较多,可以执行海量数据的并行计算;第二,有更高的访存速度;第三,有更高的浮点运算能力。
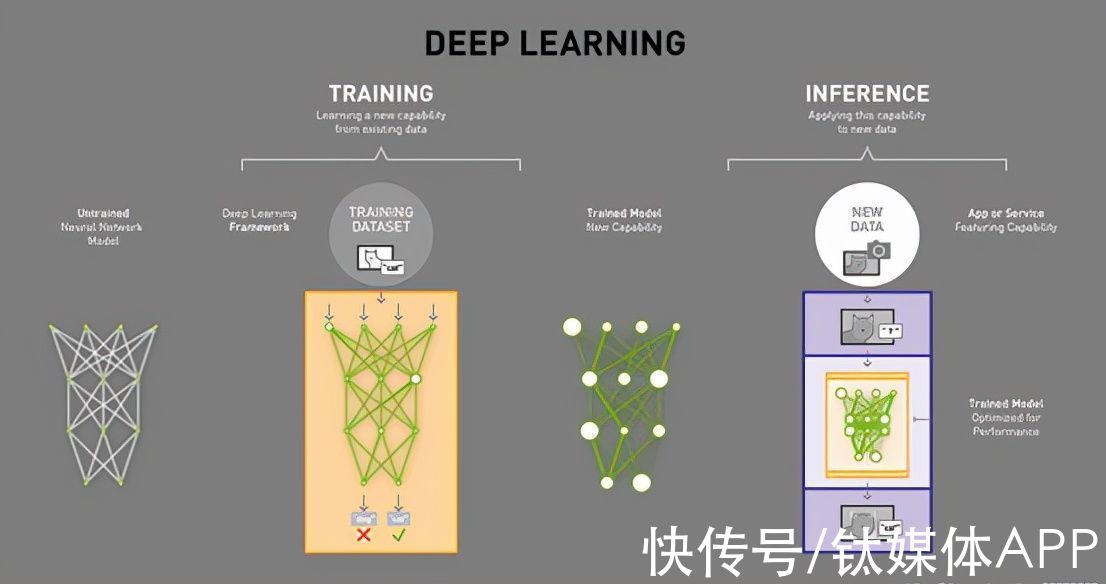
人工智能运行过程中有两部分:训练与推理。
文章插图
深度学习模型的训练与推理
训练(Training)可以看作是“教育”的过程,通过大数据训练出一个复杂的神经网络模型。推理(inference)可以看作是算法应用的过程,利用训练好的模型,使用新数据推理出各种结论。
GPU是AI“训练”阶段比较合适的芯片,在云端训练芯片中占据较大份额,达到64%,2019年-2021年年复合增长率达到40%。
3.光线追踪
IDC认为,2019年第二季度全球游戏PC和游戏显示器出货量同比增长16.5%,其原因在于“支持光线追踪游戏机型的大量推出”。
光线追踪与光栅化的实现原理不同,最早由IBM于1969年在“SomeTechniques for Shading Machine Renderings of Solids”中提出,光追技术能够完美地计算光线反射、折射、散射等路线,渲染的画面较为逼真,几乎与真实世界真假莫辨。
但该技术的计算量非常大,在过去实时光线追踪技术只在影视作品中出现,并且仅限于高成本的电影制作中。
2018年NVIDIA发布的RTX 2080 GPU,采用Turing架构,在GPU中集成了 68个独立的 RT(ray tracing) Core ,用于光线追踪,光线处理能力达到了10 Giga/S,1080P@60Hz需要处理的光线约为6Giga/S,实测基于光线追踪的应用其帧率大致在50FPS左右,基于RTX 2080的光线追踪达到了可用的程度。
GPU未来何解?前文我们曾提到过,GPU中高精度与低精度数学运算吞吐量具有很大差异。
文章插图
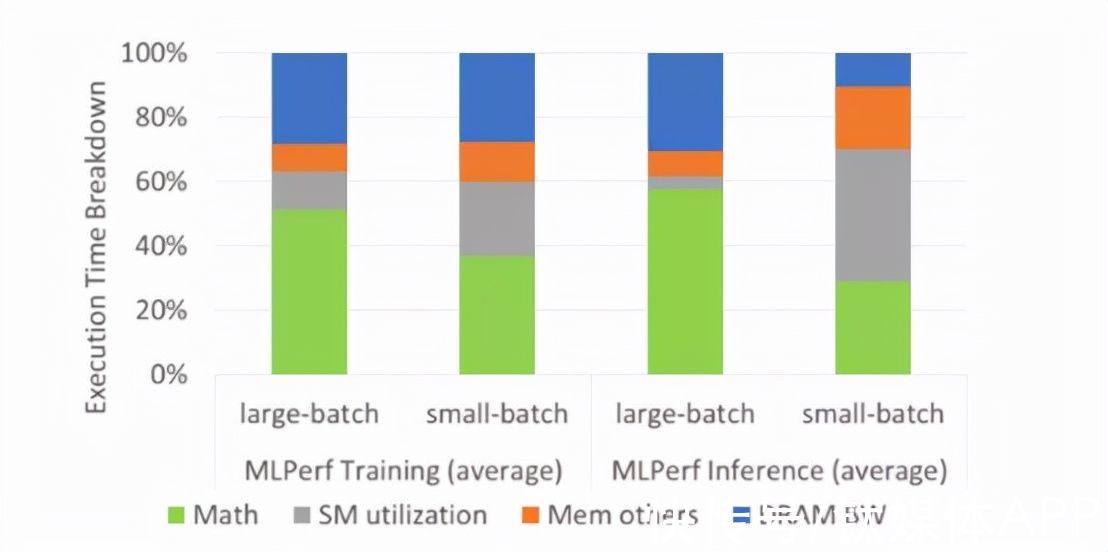
图一 同时设置大批量和小批量,利用MLPerf深度学习训练和推理方法分析GPU-N的性能瓶颈
当同时设置大批量和小批量的MLPerf套件进行深度学习工作负载的模拟性能瓶颈分析,其结果如图一所示。内存带宽是深度学习的主要限制,在大批量和小批量的情况下贡献了28%的执行时间,DRAM带宽则是大批量深度学习推理的主要瓶颈,占有30%的执行时间。
文章插图
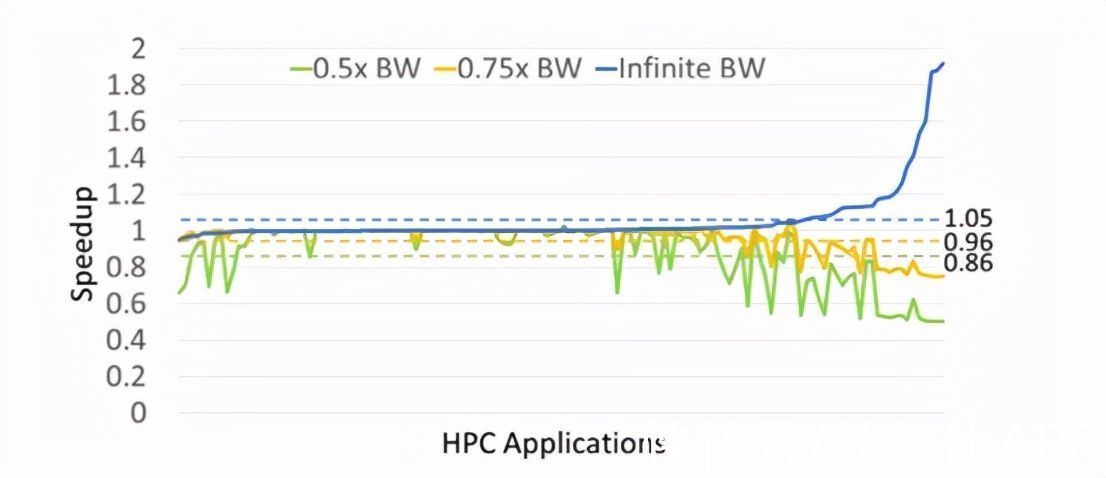
图二 不同DRAM带宽下,高性能计算应用的性能加速,虚线代表对应配置的几何加速
再来看高性能计算,与深度学习应用相反,大多数高性能计算对于DRAM带宽的变换并不敏感,当DRAM带宽增加到无限大的时候,几何平均加速只有5%。当DRAM带宽减小时,0.75倍带宽和0.5倍带宽只让性能减小了4%和14%。
因此,GPU的内存带宽会成为限制基于GPU的深度学习训练与推理的主要瓶颈,但这一限制在高性能计算中一般不会遇到。这就意味着,如果未来面向深度学习和高性能计算领域的融合GPU仍然是实际标准的话,未来DRAM带宽的增大很大程度上不会被高性能计算的应用利用到。
COPA-GPU英伟达提出了COPA-GPA架构,提供面向高性能计算和深度学习两类不同应用的GPU高层次设计,其特定的COPA-GPU设计,将每个GPU的训练和推理性能分别提高了31%和35%,同时显著降低了数据中心拓展GPU训练的成本。
【 gtc|设计困境,GPU未来何解?】COPA-GPU的架构领域定制通过集成GPM和专用领域优化的MSM实现,该MSM可以利用平面或垂直的裸芯堆叠方法,使用2.5D或3D封装集成。
- 设计师|UI设计岗位薪资怎么样
- iPhone 14 Pro|iPhone14Pro概念设计:苹果要是能做出来,花一万块钱都要买
- excel|苹果换设计师了?iPhone14“定妆照”曝光,库克的审美终于提高了
- iPhone|苹果iPhone 14最新的双挖孔渲染图很丑!还不如继续用刘海屏设计
- 芯片|全球仅有,能设计并制造出5nm芯片的,不是苹果更不是台积电
- 巴黎协定|纳微半导体成立全球首家电动车氮化镓功率芯片设计中心
- 软件|ui设计培训需要学什么软件?
- 设计师|系统分析师和系统架构设计师的主要区别是什么?
- iPhoneSE|iPhone SE3 要来了,外观设计大改,但可能要涨价了
- 艺术设计|女子拍艺术照被造谣“张爱玲奶奶” 网友吐槽行为低劣:微博CEO都表示费解