
文章插图
图片来源@视觉中国
文 | 半导体产业纵横
处理器芯片经历了从专用到通用,再从通用到专用的两次转变。Henessy和Patterson提出了特定领域架构(DSA)的概念,以冯·诺依曼体系的诞生作为分界线,在此之前晶体管计算机、录音机、计算器等使用不同的芯片,而在冯·诺依曼体系诞生后,芯片逐渐走向通用CPU。
领域特定架构随着摩尔定律的减速,通用CPU对于图形处理计算的速度较慢,也因此GPU诞生,解放了原本CPU的部分工作。Henessy和Patterson提出的特定领域架构(DSA)的概念,而GPU就是用于3D图形领域的DSA。
下图对CPU和GPU的逻辑架构进行了对比。其中Control是控制单元,ALU是逻辑运算单元,Cache是其内部缓存,DRAM就是内存。可以看到,CPU虽然也是多核,但总数没有超过两位数,且需要复杂的控制单元和缓存。
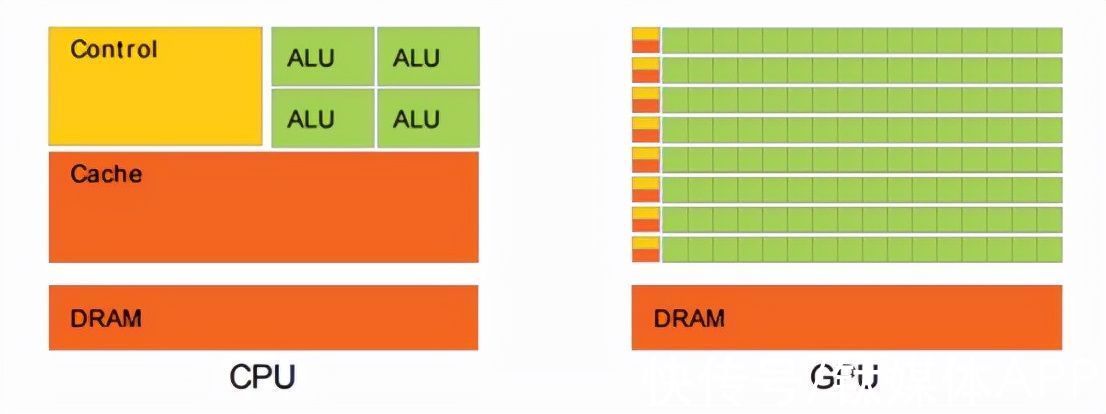
文章插图
而GPU的优势在于多核,其核数远超CPU可以达到数百个,每个核拥有的缓存相对较小,数字逻辑运算单元少且简单。从实际来看,CPU芯片空间的5%是ALU,而GPU空间的40%是ALU,这也成为GPU计算能力超强的原因。
正因为GPU的原理,今天的GPU不仅具备高质量和高性能图形处理能力,还可以用于通用计算。事实证明,在浮点运算、并行运算等部分计算方面,GPU可以提供数十倍乃至于上百倍于CPU的性能,GPU使得显卡减少了对于CPU的依赖,并进行部分原本CPU的工作。
因此,GPU具有双重属性:一是图像处理,另一个是高速计算。
GPU未来发展趋势作为创造出GPU的公司,英伟达对于GPU的定位和探索对于窥探行业未来发展非常重要。GPU未来如何发展,从历年英伟达举办的中国GTC大会中可见一二。在2019年中国GTC大会上英伟达设置了两大主题,分别是AI和图形。在2020年,GTC大会的主题分论坛则包含深度学习、自主机器和边缘计算、高性能计算与专业图形等。

文章插图
来源:英伟达官网
不难看出,GPU未来徘徊于其双重属性AI DSA和3D DSA之间,并且人工智能计算、大规模扩展计算能力的高性能计算、专业图像显示是目前GPU的主要发展方向。
尽管GPU具有双重属性,但这两重属性是无法同时得到拓展的。AI DSA需要加速张量运算,这是一种在AI中很常见的运算,但是在3D视觉中是没有的,同时,为3D用途准备的固定功能硬件对于AI来说一般是不需要的。
在论文《GPU Domain Specialization via Composable On-Package Architecture Share on》中,也展示了GPU中高精度与低精度数学运算吞吐量强烈的差异。这个鸿沟导致设计一个能够同时支持高性能计算和深度学习使用的存储系统是非常困难的。
因此,尽管GPU适用于多领域运用,但遗憾的是目前GPU无法同时出色实现某两个领域的极致。
1.高性能计算
高性能计算(HPC)常用于大数据分析、超级计算、高级建模和模拟,超级计算机代表着高性能计算系统最尖端的水平。
其工作原理是异构计算,通过多个计算节点利用GPU主力的并行处理能力,HPC能够高效、可靠、快速地运行先进的大型应用程序项目,速度提升后可大幅提升吞吐量并降低成本。
英伟达最新发布的Tesla V100s高性能计算GPU,其有640个Tensor内核,集成5120个CUDA Core,640个Tensor Core,采用32 GB HBM2显存,显存带宽达1134GB/S,单精度浮点计算能力达16.4 TFLOPS。
2.AI领域
由于GPU良好的矩阵计算能力和并行计算的特性,是最早被用于AI计算的,这也是为什么英伟达CEO多次表达过:“英伟达不是一家游戏公司,而是一家AI公司。”AI运算指以“深度学习”为代表的神经网络算法,需要系统高效处理大量结构化数据,例如文本、视频、图像、语言等。
- 设计师|UI设计岗位薪资怎么样
- iPhone 14 Pro|iPhone14Pro概念设计:苹果要是能做出来,花一万块钱都要买
- excel|苹果换设计师了?iPhone14“定妆照”曝光,库克的审美终于提高了
- iPhone|苹果iPhone 14最新的双挖孔渲染图很丑!还不如继续用刘海屏设计
- 芯片|全球仅有,能设计并制造出5nm芯片的,不是苹果更不是台积电
- 巴黎协定|纳微半导体成立全球首家电动车氮化镓功率芯片设计中心
- 软件|ui设计培训需要学什么软件?
- 设计师|系统分析师和系统架构设计师的主要区别是什么?
- iPhoneSE|iPhone SE3 要来了,外观设计大改,但可能要涨价了
- 艺术设计|女子拍艺术照被造谣“张爱玲奶奶” 网友吐槽行为低劣:微博CEO都表示费解