clip|OpenAI又出一文本生成图像模型,参数比DALL·E少85亿,质量更真( 二 )
研究人员首先比较了GLIDE两种不同的引导策略:CLIP引导和无分类器引导。
分别用XMC-GAN、DALL·E(使用CLIP重排256个样本,从中选择最佳结果)和CLIDE模型(CLIP引导/无分类器引导)在相同的文本条件下生成了一些结果。
CLIDE模型的结果未经挑选。

文章插图
可以发现,无分类器引导的样本通常比CLIP引导的看起来更逼真,当然,两者都胜过了DALL·E。
对于复杂的场景,CLIDE可以使用修复功能进行迭代生成:比如下图就是先生成一个普通客厅,再加画、加茶几、加花瓶……

文章插图
此外,CLIDE还可以在SDedit模型上利用草图与文本相结合的方式,对图像进行更多受控修改。

文章插图
- 定量实验
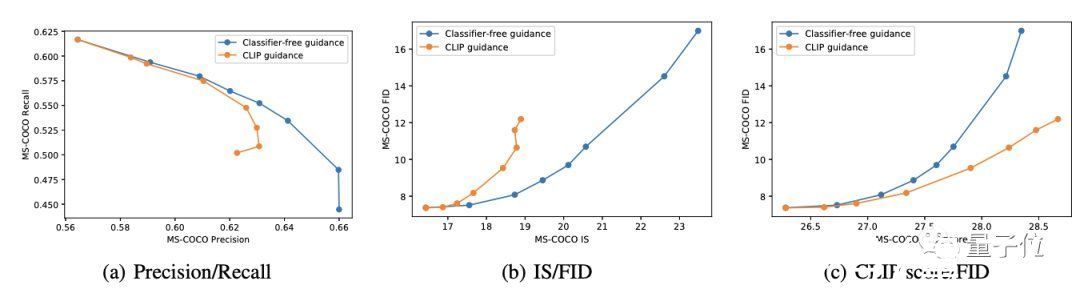
文章插图
在前两组曲线中,可以发现无分类器引导几乎都是最优的——不管是在准确率/召回率上,还是在IS/FID距离上。
而在绘制CLIP分数与FID的关系时,出现了完全相反的趋势。
研究人员假设这是CLIP引导正在为评估CLIP模型寻找对抗性示例,而并非真正优于无分类器引导。为了验证这一假设,他们聘请了人工评估员来判断生成图像的质量。
在这个过程中,人类评估者会看到两个256×256的图像,选择哪个样本更好地匹配给定文本或看起来更逼真。如果实在分辨不出,每个模型各得一半分数。
结果如下:
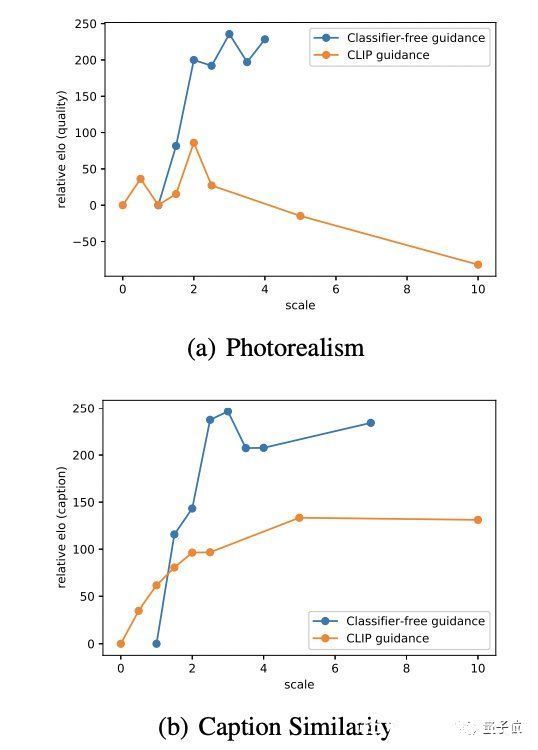
文章插图
无分类器引导产生了更符合相应提示的高质量样本。
同时,研究人员也将CLIDE与其他生成模型的质量进行了评估:CLIDE获得了最有竞争力的FID分数。
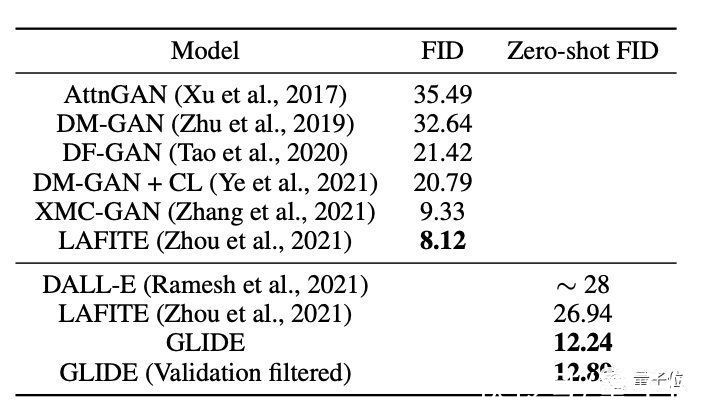
文章插图
再将GLIDE与DALL-E进行人工评估。
包含三种比法:两种模型都不使用CLIP重排序;仅对DALL·E使用CLIP重排序;对DALL-E使用CLIP重排序,并通过DALL-E使用的离散VAE映射GLIDE样本。
结果是不管哪种配置,人类评估员都更倾向于GLIDE的结果(每项第一行代表GLIDE)。
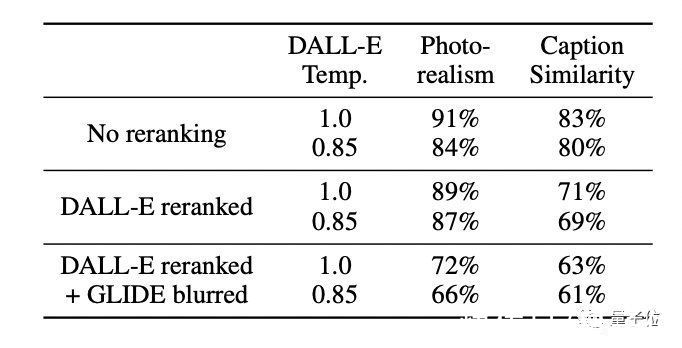
文章插图
当然,说这么多,GLIDE也有它的不足,就如开头的例子,它没法画出不合常理的“八条腿的猫”,也就是有智力但缺乏想象力。
此外,未优化的GLIDE需要15秒才能在单张A100 GPU上生成一张图像,这比GAN慢多了。
最后,po一张我们在官方发布的Colab链接上亲手试的一张效果,还凑合(an illustration of a rabbit,demo上的模型比较小):

文章插图
论文地址:
https://arxiv.org/abs/2112.10741
GitHub地址(是一个在过滤后的数据集上训练的小模型):
https://github.com/openai/glide-text2im
Colab试玩:
https://colab.research.google.com/github/openai/glide-text2im/blob/main/notebooks/text2im.ipynb#scrollTo=iuqVCDzbP1F0
— 完 —
量子位 QbitAI · 头条号签约
- 又出现一变异毒株,比奥密克戎更恐怖?世卫拉响警报,钟南山表态
- 小米科技|红米K50跑分公布,骁龙870又出神机,120W秒充+自研芯片
- eclipse|三星S22系列最新爆料:全部使用骁龙8,全系涨价,超大杯价格破万
- eclipse|带你入门Java之Eclipse的插件安装
- 微软|刚被Intel挖走芯片总监 苹果技术大牛又出走微软:开发服务器芯片
- eclipse|ROG新品电竞显示器亮相CES 2022,全新技术加持,电竞体验飞跃
- 时尚先生们的潮流Vlog神器,荣耀60又出圈了
- 专利|又出现一只“拦路虎”?华为5G再起波澜,零部件也不让用了?
- 百台订单!低碳“优等生”又出手了
- 员工|惨还是打工人惨:继算法裁员、AI监工后又出新玩法,请病假也得看AI“脸色”了