clip|OpenAI又出一文本生成图像模型,参数比DALL·E少85亿,质量更真
OpenAI刚刚推出了一个新的文本生成图像模型,名叫GLIDE。
文章插图
相比今年年初诞生的大哥DALL·E,它只有35亿参数(DALL·E有120亿)。
规模虽然小了,质量却不赖。
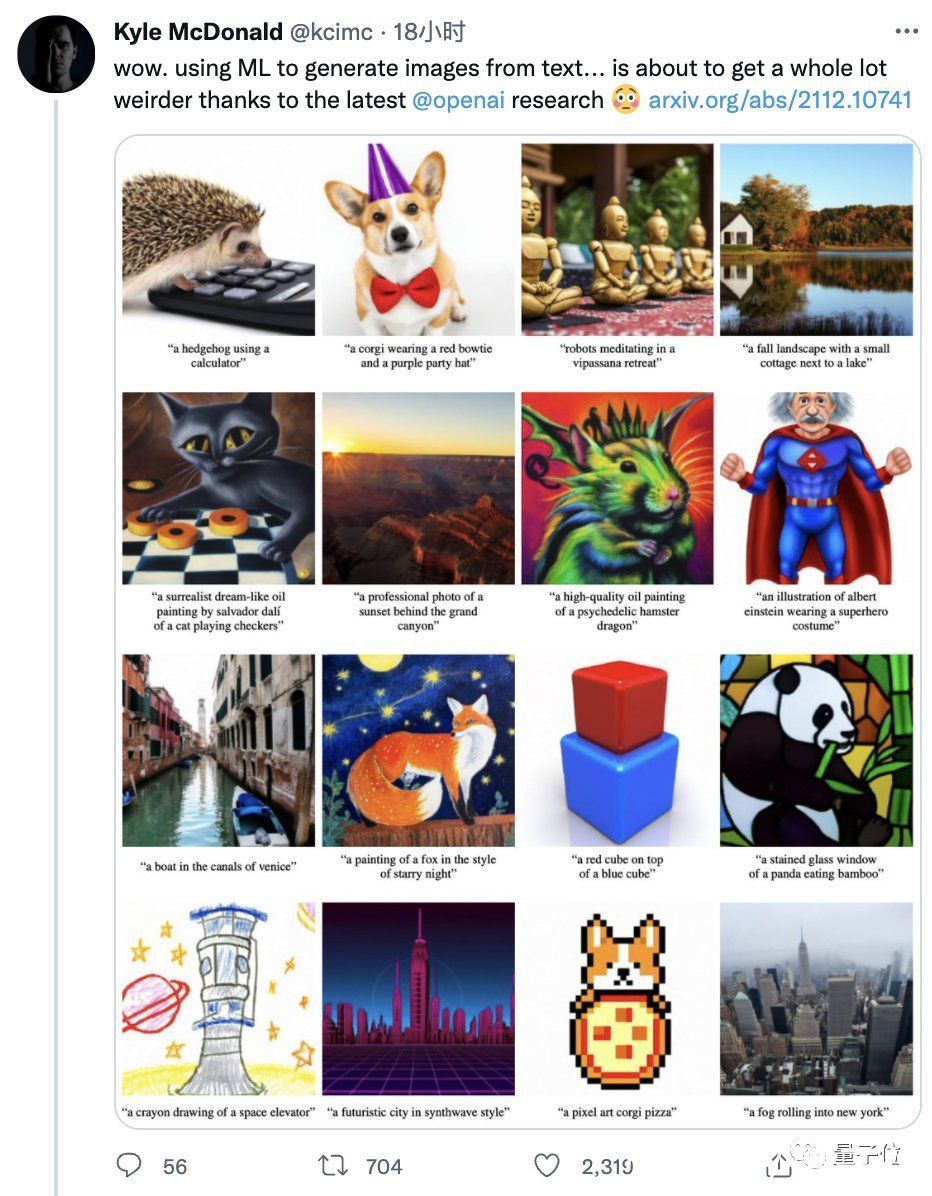
大家仔细看这效果,“使用计算器的刺猬”、“星空下的狐狸”、“彩色玻璃窗风格的熊猫吃竹子”、“太空升降舱蜡笔画”:

文章插图
是不是很像样儿?
一位码农兼艺术家的网友则形容它“和真的难以区分”。

文章插图
【 clip|OpenAI又出一文本生成图像模型,参数比DALL·E少85亿,质量更真】GLIDE在人类评估员的打分中,确实PK掉了使用CLIP给图片排序的DALL·E。

文章插图
最有趣的是,这个GLIDE似乎具有“智力”——会否决你画出八条腿的猫的主意,也不认为老鼠可以捕食狮子。

文章插图
OpenAI岁末新作GLIDEGLIDE全称Guided Language to Image Diffusion for Generation and Editing,是一种扩散模型(diffusion model)。
扩散模型最早于2015提出,它定义了一个马尔可夫链,用于在扩散步骤中缓慢地向数据添加随机噪声,然后通过学习逆转扩散过程从噪声中构建所需的数据样本。
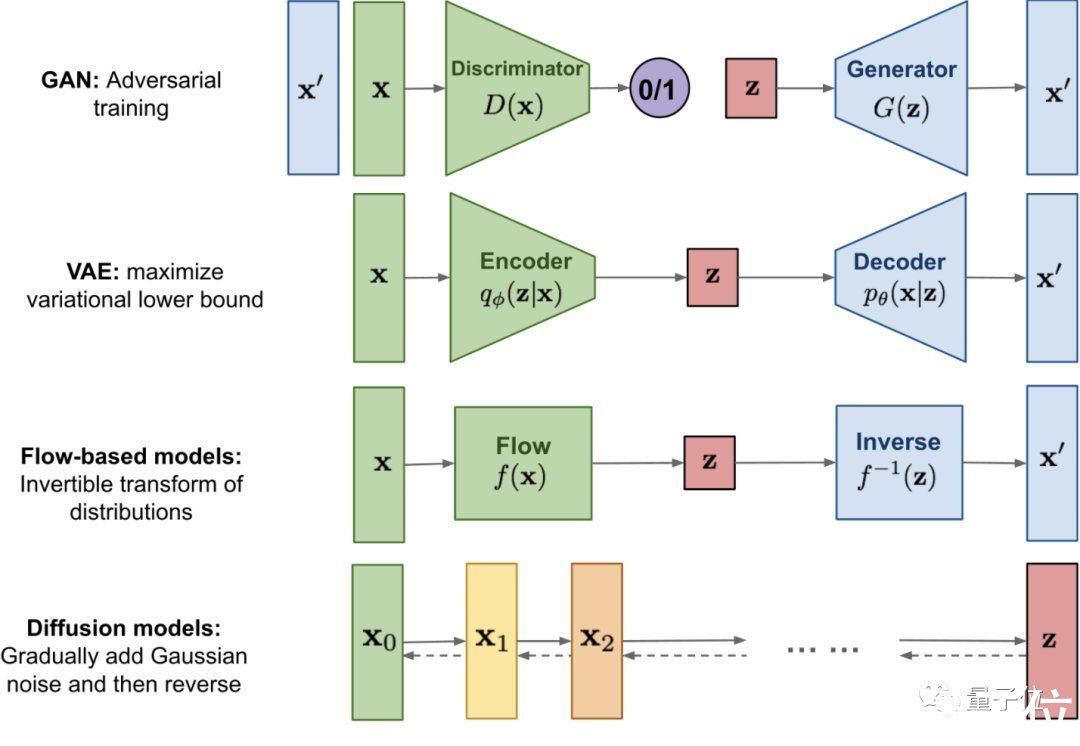
相比GAN、VAE和基于流的生成模型,扩散模型在性能上有不错的权衡,最近已被证明在图像生成方面有很大的潜力,尤其是与引导结合来兼得保真度和多样性。
文章插图
△扩散模型与其他三种生成模型的对比
研究人员训练了一个64×64分辨率的文本条件扩散模型,参数35亿;以及一个256×256分辨率的文本条件上采样扩散模型,参数15亿。
模型有两种引导形式来获得更好的生成效果:无分类器引导(classifier-free guidance)和CLIP引导。
对于CLIP引导,他们还训练了一个噪声感知的64×64 ViT-L CLIP模型 (vit)。
模型采用了SOTA论文《Improved Denoising Diffusion Probabilistic Models》(改进的去噪扩散概率模型)的架构,使用文本条件信息对其进行增强。
对于每个带噪图像xt和相应的提示文本caption,该模型预测出p(xt-1|xt,caption)。
为了对文本进行条件处理,模型还将文本编码为K个token的序列,并将这些token馈送到Transformer中,此Transformer的输出有两个用处:
1、在ADM模型中使用最终token embedding来代替class embedding;
2、token embedding的最后一层在整个ADM模型中分别映射每个注意层的维度,然后连接到每个层的注意上下文。
研究人员在与DALL·E相同的数据集上训练GLIDE,batch size为2048,共经过250万次迭代;对于上采样模型,则进行了batch size为512的160万次迭代。
这些模型训练稳定,总训练计算量大致等于DALL·E。
在初始训练完成之后,研究人员还微调了基础模型以支持无条件图像生成。
训练过程与预训练完全一样,只是将20%的文本token序列替换为空序列。这样模型就能既保留文本条件生成的能力,也可以无条件生成。
为了让GLIDE在图像编辑任务中产生不必要的伪影,研究人员在微调时将GLIDE训练样本的随机区域擦除,其余部分与掩码通道一起作为附加条件信息输入模型。

文章插图
相比DALL·E,GLIDE的效果更逼真
- 定性实验
- 又出现一变异毒株,比奥密克戎更恐怖?世卫拉响警报,钟南山表态
- 小米科技|红米K50跑分公布,骁龙870又出神机,120W秒充+自研芯片
- eclipse|三星S22系列最新爆料:全部使用骁龙8,全系涨价,超大杯价格破万
- eclipse|带你入门Java之Eclipse的插件安装
- 微软|刚被Intel挖走芯片总监 苹果技术大牛又出走微软:开发服务器芯片
- eclipse|ROG新品电竞显示器亮相CES 2022,全新技术加持,电竞体验飞跃
- 时尚先生们的潮流Vlog神器,荣耀60又出圈了
- 专利|又出现一只“拦路虎”?华为5G再起波澜,零部件也不让用了?
- 百台订单!低碳“优等生”又出手了
- 员工|惨还是打工人惨:继算法裁员、AI监工后又出新玩法,请病假也得看AI“脸色”了