数据集|无需任何标记数据,几张照片就能还原出3D物体结构,自监督学习还能这样用( 二 )
无需任何外部标记,2D还原3D关系
作者与其他模型进行了详细对比,这些模型涵盖不同的3D还原方法,包括深度图、CNN、立体像素、网格等。
在监督学习所用到的参数上,可用的包括深度、关键点、边界框、多视图4类;而在测试部分,则包括2D转3D、语义和场景3种方式。

文章插图
可以看见,绝大多数网络都没办法同时实现2D转3D、在还原场景的同时还能包含清晰的语义。
即使有两个网络也实现了3种方法,他们也采用了深度和边界框两种参数进行监督,而非完全通过自监督进行模型学习。
这一方法,让模型在不同的数据集上都取得了不错的效果。
无论是椅子、球体数据集,还是字母、光影数据集上,模型训练后生成的各视角照片都挺能打。

文章插图
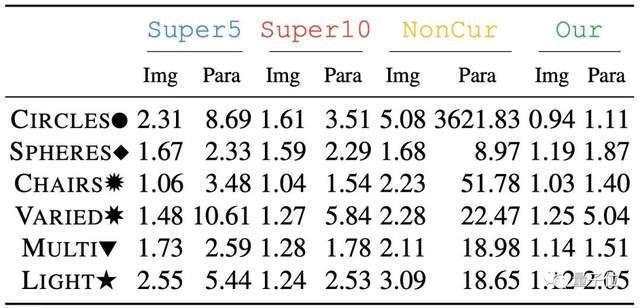
甚至自监督的方式,还比加入5%监督(Super5)和10%监督(Super10)的效果都要更好,误差基本更低。
文章插图
而在真实场景上,模型也能还原出照片中的3D物体形状。
例如给出一只兔子的照片,在进行自监督训练后,相比于真实照片,模型基本还原出了兔子的形状和颜色。

文章插图
不仅单个物体,场景中的多个3D物体也都能同时被还原出来。

文章插图
当然,这也离不开“好奇心驱动”这种方法的帮助。
事实上,仅仅是增加“好奇心驱动”这一部分,就能降低不少参数错误率,原模型(NonCur)与加入好奇心驱动的模型(Our)在不同数据集上相比,错误率平均要高出10%以上。

文章插图
不需要任何外部标记,这一模型利用几张照片,就能生成3D关系、还原场景。
作者介绍
3位作者都来自伦敦大学学院。

文章插图
一作David Griffiths,目前在UCL读博,研究着眼于开发深度学习模型以了解3D场景,兴趣方向是计算机视觉、机器学习和摄影测量,以及这几个学科的交叉点。

文章插图
Jan Boehm,UCL副教授,主要研究方向是摄影测量、图像理解和机器人技术。
Tobias Ritschel,UCL计算机图形学教授,研究方向主要是图像感知、非物理图形学、数据驱动图形学,以及交互式全局光照明算法。
【 数据集|无需任何标记数据,几张照片就能还原出3D物体结构,自监督学习还能这样用】有了这篇论文,设计师出门拍照的话,还能顺便完成3D作业?
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- OpenHarmony 项目群 12 月新增捐赠人美的集团、深圳开鸿
- 财智干货|数智化发展任重道远,财务中台提升数据服务价值 | 大数据
- 支付宝集五福活动 1 月 19 日正式开始,现可提前领福
- 美少女1985集
- 央媒表态后,联想关键数据出炉,柳传志这回要扳回一局?
- 电子封装技术、微电子、集成电路等,电子信息类专业,研究方向
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- 注册资本|美的集团投资成立汽车部件公司,注册资本 2 亿元