数据集|无需任何标记数据,几张照片就能还原出3D物体结构,自监督学习还能这样用
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
只给你几张物体的照片,你能准确还原出它在各种刁钻视角下的模样吗?
现在,AI可能比你还原得还要准确。
只给几个3D球的正脸照片:

文章插图
AI立刻就能将不同视角的球形照片还原出来,大小颜色都接近真实的照片。

文章插图
稍微复杂一点的结构,如这堆椅子:

文章插图
AI在经过思考后,也能立即给出椅子在另一视角下的照片,结构大小与真实场景相比,几乎没有跑偏。

文章插图
这还是在完全没有给出物体深度、边界框的情况下,AI模型纯粹靠自己预测出来的3D效果。
那么,这样的模型到底是怎么做出来的呢?
给模型安排一个“批评家”
这是一个由CNN和MLP(多层感知器)组成的模型,其目的在于通过一组2D图片(不带任何标签),从中还原出物体的3D关系来。
相比于单个3D物体,这个模型能够在整个场景上进行3D训练,并将它还原出来。
例如,根据下图的几张兔子照片,还原出3D兔子模型在俯视角度下拍摄的照片。

文章插图
但从2D照片中还原出物体的3D关系,并不如看起来这么简单。
在还原过程中,模型不仅要准确推断每个3D物体的位置、深度、大小,还要能还原出它的光照颜色。
通常训练神经网络的第一想法是,将这几个变量直接设为参数,并采用梯度下降算法对模型进行收敛。
但这样效果会很差,因为模型在想办法“偷懒”。

文章插图
例如,下图真实目标(蓝色)与当前目标(红色)有差异,然而在进行梯度下降时,尝试移动一定距离,误差没有降低;但在改变大小时,误差却降低了,就对网络模型形成了误导。
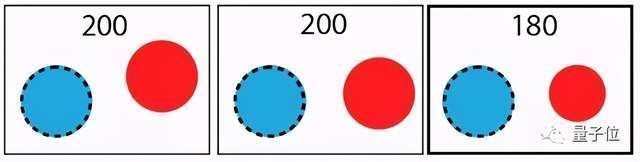
文章插图
对此,研究者利用强化学习中的好奇心驱动,额外给模型加了一个“批评家”(critic)网络,它会利用数据分布中随机提取的有效样本,来褒贬模型的结果。
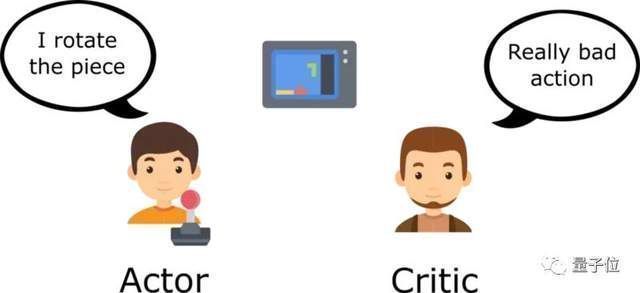
文章插图
这样,模型作为“表演者”(actor),为了获得更好的评价,就会再试图去寻找更好的方法,以生成更优的结果。
如下图所示,左边是没有利用好奇心驱动的模型,右边则是加入了好奇心驱动。在“批评家”的驱使下,模型逐渐推导出了正确的参数。
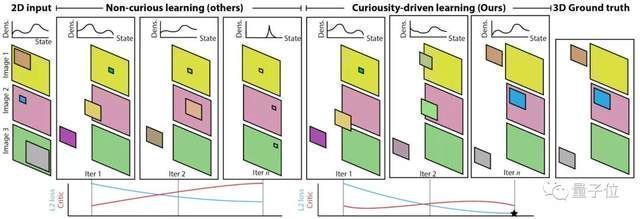
文章插图
这一“批评家”网络,迫使模型在优化过程中,不能只依赖于同一种(错误的)答案,而是必须在已有数据下寻找更好的解决方案。
事实证明,加了“批评家”网络的模型,不仅收敛下降到了一个新的高度(如上图蓝色线条),而且评论家最终给出的评分也不错。
那么,相比于其他3D关系生成模型,这一结构的优势在哪里呢?
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- OpenHarmony 项目群 12 月新增捐赠人美的集团、深圳开鸿
- 财智干货|数智化发展任重道远,财务中台提升数据服务价值 | 大数据
- 支付宝集五福活动 1 月 19 日正式开始,现可提前领福
- 美少女1985集
- 央媒表态后,联想关键数据出炉,柳传志这回要扳回一局?
- 电子封装技术、微电子、集成电路等,电子信息类专业,研究方向
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- 注册资本|美的集团投资成立汽车部件公司,注册资本 2 亿元