Babelfish 的方案是用 hooks(钩子)方法在 PostgreSQL 内置引擎中实现,将自己暴露为不同的数据库(否则就只能修改 PostgreSQL 许多核心区域的代码),其架构图如下:
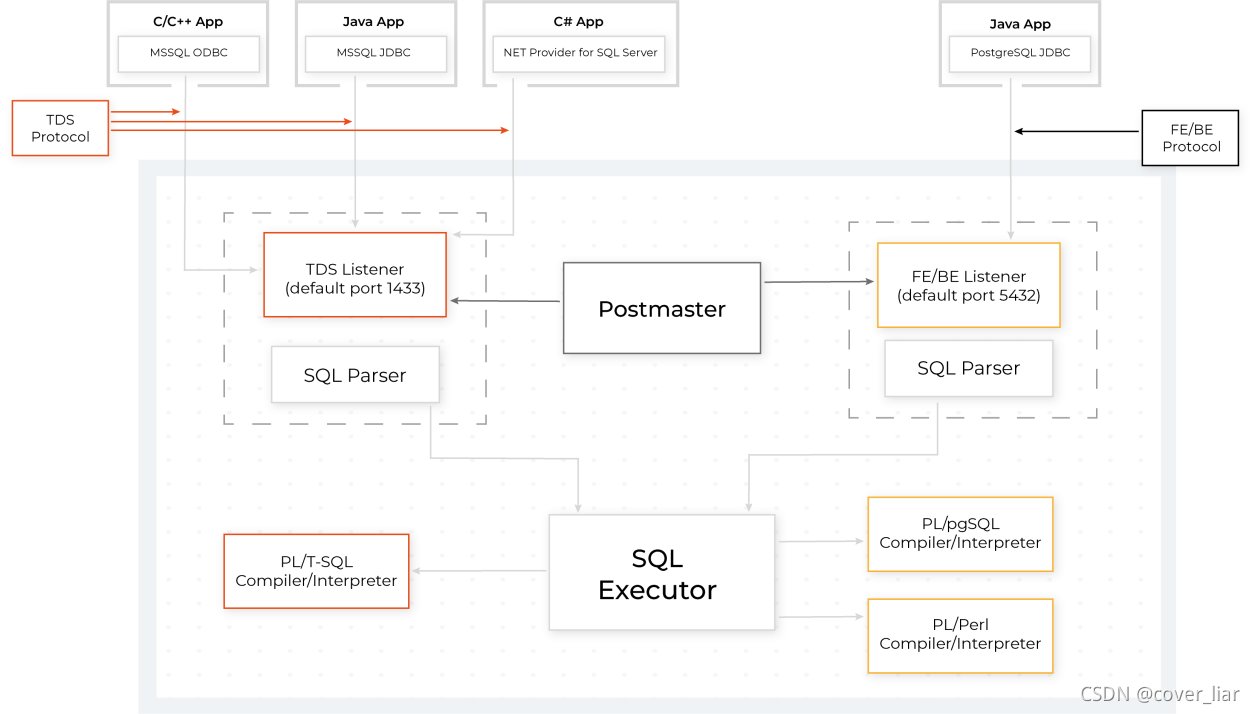
文章插图
精妙之处在于,通过数据库内核部分执行器层面的扩展开发,Babelfish 实现了 T-SQL 与 pgSQL 之间的互相调用。也就是说,新写 PostgreSQL 代码可以调用之前应用写的 SQL Server 代码。对于写过存储过程的朋友们来说,这个功能已经和 Babelfish 的名字一样,带上“科幻”色彩了。即便已经使用了最硬核的实现方式, Babelfish 也没有完全实现兼容,ADD SIGNATURE 等一些功能、语法还没有实现。亚马逊官方工程师说:“SQL Server 已经发展了 30 多年,我们不希望立即支持所有功能。相反,我们专注于最常见的 T-SQL 命令并返回正确的响应或错误消息。”
这也恰恰说明了类似迁移加速器的开发难度,也证实了为什么开源路线才是最适合 Babelfish 发展的,因为开源可以让足够多的开发者参与到产品迭代中来。
同理,一个如此高难度的开发项目,也不太可能是无足轻重的。相反,它可能是亚马逊云科技 2020 年最重要的发布之一。
2.数据库碎片化时代,真的来了?
亚马逊在云计算领域的发布,曾多次引导了整个产业的发展方向。比如,2012 年发布的 Amazon Redshift 引导了云原生数仓的发展方向,2014 年发布的 Amazon Lambda 引导了 Serverless 的发展方向(Gartner 到 2019 年才确认 Serverless 为未来趋势),Amazon Aurora 本身也是云原生数据库的先驱产品。
如果说,Babelfish 也代表了一种方向,那么或许是,数据库碎片化的时代,真的来了。
数据库这个产品本身因为开发难度太高,长期以来都被少数几家公司把控着,其中的佼佼者 Oracle 更是以极快的速度提升着商业数据库的开发门槛。
但数据库“单极”化发展后导致的价格高、绑定风险高等问题,也让众多企业逐渐难以忍受。当下,各种类型的数据库层出不穷,关系型、键值、时序、图形……让人难以抉择。另外一个重要的现象是,大部分云原生数据库都是基于 PostgreSQL 研发而来,但后续的许多研发力量却没有投入到高性能、高可拓展性等传统技术概念本身。
数据库兼容,这一开发难度高,与性能无关的特性,却成为了亚马逊云科技的研发重点。某种意义上也说明,遍地开花的各类型数据库还将长期存在于产业内。人们习惯认为,产业的长期发展趋势是从单一走向多元,最终经过市场筛选,回归单一。但这次,“单极”时代可能真的一去不复返了。
此外,在 2020 Gartner 的魔力象限报告里,云数据库领域有数家占领导位置的企业,亚马逊、微软、Google 位居前三位。
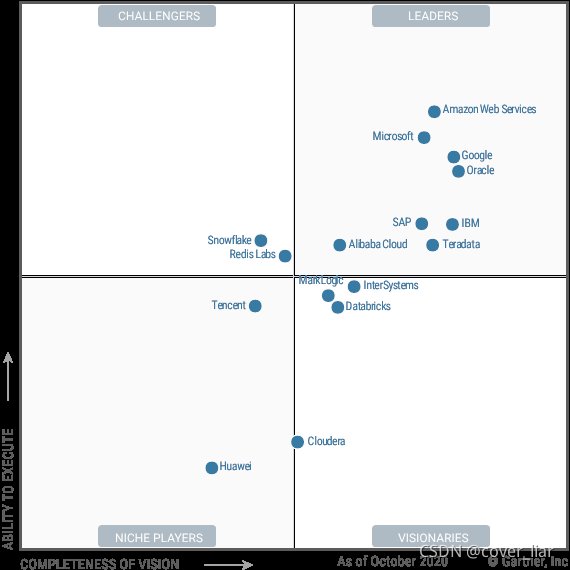
文章插图
而就在 2019 年,前三名还是微软、Oracle、亚马逊。老大老三打着打着,老二没了……
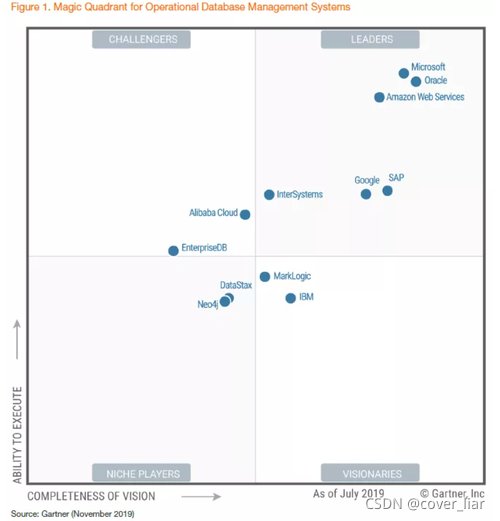
文章插图
如今,有 Babelfish 加持的 Amazon Aurora ,兼容了 Microsoft SQL Server ,恐怕受伤的还是 Oracle。云数据库之间的墙壁在倒塌,而传统商业型数据库的竞争难度在进一步加大。
而乘上碎片化时代东风,发布了 Babelfish 的 Amazon ,也顺理成章的成为了云数据库市场新的领头羊。
3.写在最后
数据库行业远未走到终局,也不会有所谓的终局。但云原生数据库可以获得的优势并不仅限于数据库本身,比如 Amazon Aurora Serverless 提供的弹性伸缩服务,Amazon Aurora Global Database 提升了数据全球同步能力与业务连续性,Amazon DevOps Guru 将机器学习引入了应用管理。这是“合力”,将数据库在云上的体验拉伸到了全新的维度。
- 加盟行业|原来加盟行业是这么玩的!
- 京东|适合过年送长辈的数码好物,好用不贵+大牌保障,最后一个太实用
- 一个时代的结束!中国移动:10086 App将于1月30日起
- Linux|电脑城卖的CPU是intel而不是AMD,和实体店不喜欢卖小米手机是一个道理
- 高通骁龙|发布一个月仍供不应求,144Hz+12G+256G,开售几乎秒售完
- meta|一个24小时就会自毁的网站,在网友的接力下存活了两年
- 酷睿处理器|只少一个“K” 酷睿12600到底怎么样
- 路由器|只需一个设置,WIFI 信号大幅增强?
- 国美电器|没有音乐就很无聊!自己动手制作一个小功放,是不是很有成就感呢
- 阿里巴巴|一块桌面版3070显卡的价格,就够买一个3070笔记本,还能剩点