鲁棒性|自动驾驶出行服务商业化试点落地,百度“钱途”曙光初现( 二 )
对于没有reference的数据,可以使用基于规则的方法生成伪数据。针对不同的场景,可以设计对应的规则,然后从干净的数据中生成带噪数据,最后反向这个过程就可以得到编辑过程。
训练完成后,便可以进行解码。正如图2右侧展示的,Secoco 有两种解码方式。第一种是仅使用编码器-解码器结构直接进行翻译 (Secoco-E2E),另一种则是对输入进行迭代编辑后再进行翻译 (Secoco-Edit)。
3
性能一览
作者在三个测试集进行了实验,包括一个基于电视剧的中英对话测试集,一个内部的中英语音翻译测试集,以及加入人工噪声的英德WMT14测试集。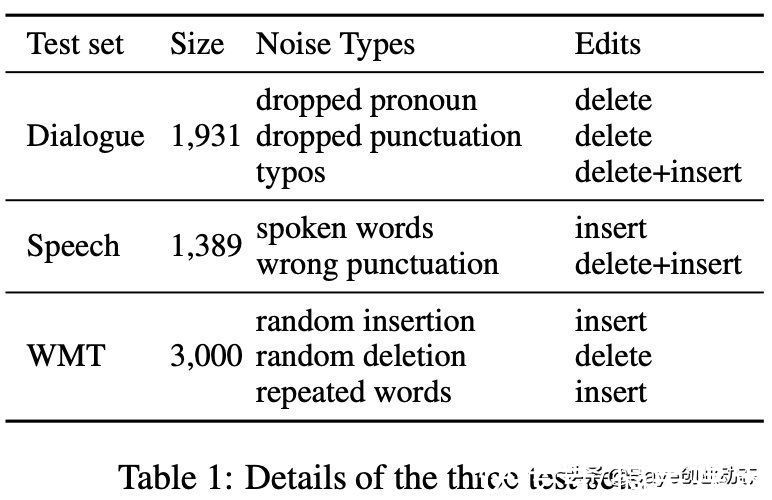
文章插图
表1 测试集统计
如表1所示,对话测试集包含主语省略,标点省略,错别字等问题;语音测试集包含口语词,错别字等 ASR 引起的问题;WMT14 则包含由规则构造的随机插入,随机删除,重复等问题。
实验结果如表2所示。除了 Secoco 之外,作者还和3种方法进行了对比,分别是将合成的噪声数据加入原始数据中一起训练 (BASE+synthetic);使用修复模型加上翻译模型的 pipeline 级联结构 (REPAIR);以及多编码器-单解码器的结构 [1] (RECONSTRUCTION)。可以看出,所有的方法相较于基线模型都有所提升。Secoco 在三个测试集上都获得了最好的效果。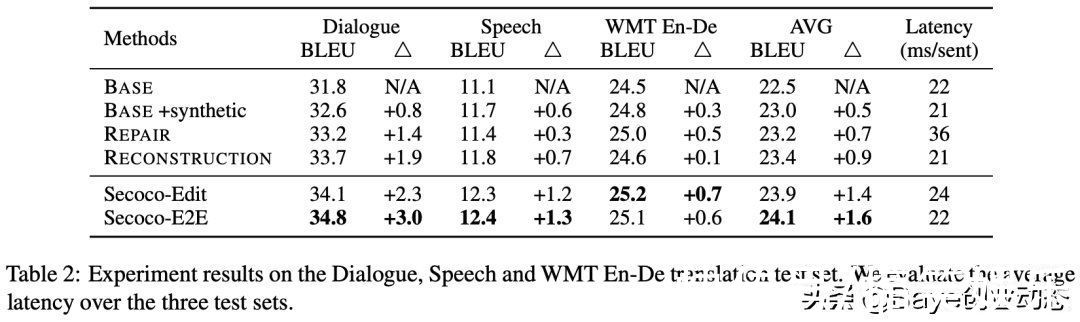
文章插图
表2 实验结果
此外,在这三个测试集中,对话测试集明显包含更多的噪声,Secoco 最多可以带来3个 BLEU 的提升。语音测试集由于是由 ASR 导出的,因此最好的结果也仅有12.4。
文章插图
表3 迭代编辑样例
表格3中给出了一些迭代编辑的具体例子。针对每一句输入,模型对其进行迭代删除和插入操作,直到文本不再发生变化。从例子中可以看到,一次编辑操作可以同时删除或者插入多个词。此外,对于上述的测试集,平均每个句子需要2-3次编辑操作。
4
总结
针对互联网中非规范输入带来的鲁棒性问题,本文主要介绍了一个具有自我修正能力的神经机器翻译框架 Secoco,该框架通过两个独立的编辑操作预测器建模修正带噪输入的过程。实验表明,Secoco 在多个测试集上都优于基线模型,增强了翻译模型的鲁棒性,并提供了一定的可解释性。
【 鲁棒性|自动驾驶出行服务商业化试点落地,百度“钱途”曙光初现】[1] Shuyan Zhou, Xiangkai Zeng, Yingqi Zhou, Antonios Anastasopoulos, and Graham Neubig. 2019. Improving robustness of neural machine translation with multi-task learning. In Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1), pages 565–571.
- 36氪5G创新日报0112|福建省首个“5G+VR”英模会客厅正式上线;齐鲁医院健康管理中心“5G+ 5g
- 算力|不靠显卡!NVIDIA在中国焕发第二春:自动驾驶芯片被车厂爆买
- 自动驾驶|华为首秀自动驾驶,王兴:特斯拉遇到技术与忽悠能力相当的对手了
- 测试|解码自动驾驶商业化进阶的亦庄样本
- 京东|京东在荷兰开设全自动智能商店
- 齐鲁壹点|36氪首发 | 「艾灵网络」获数千万元Pre-A+轮投资,为工业领域搭建最后一公里ICT基础设施
- 虽然百度官方对百度自动驾驶部门裁员矢口否认|自动驾驶技术公司毫末智行的生存之道
- 自动驾驶计算|自动驾驶计算芯片制造商黑芝麻智能获得博世旗下博原资本战略投资
- 消研所周报|红杉中国控股WE11DONE;奈雪自主研发自动化制茶设备;bosie正式发布NFT数字艺术作品 | 自动化
- 特斯拉|生命安全至上!复旦教授称不要尝试L2级别以上自动驾驶