google|Meta公布自我监督学习多样语言模型XLS-R,可对应128种语言互译
Meta旗下Facebook人工智能研究院宣布推出名为XLS-R,并且能对应多样语言自我监督学习的模型,目前已经能识别128种语言,相比先前采用语言学习模型能以10倍数据量学习多达两倍语言数量。
【 google|Meta公布自我监督学习多样语言模型XLS-R,可对应128种语言互译】
文章插图
依照说明,XLS-R语言学习模型是以据自我监督的语句描述识别工具wav2vec 2.0为基础,并且以长达43万6000小时长度公开可使用语句进行训练,并且建立超过20亿组参数,借此获得可对应128种语言流畅互译的训练模型。
在BABEL语言测试中,XLS-R在对应印度阿萨姆语、菲律宾他加禄语、非洲史瓦希利语、老挝通用老挝语,以及在伊朗、土耳其等地区使用的格鲁吉亚语,与英语转译时的错误率,相比前一版本语言模型均明显减少。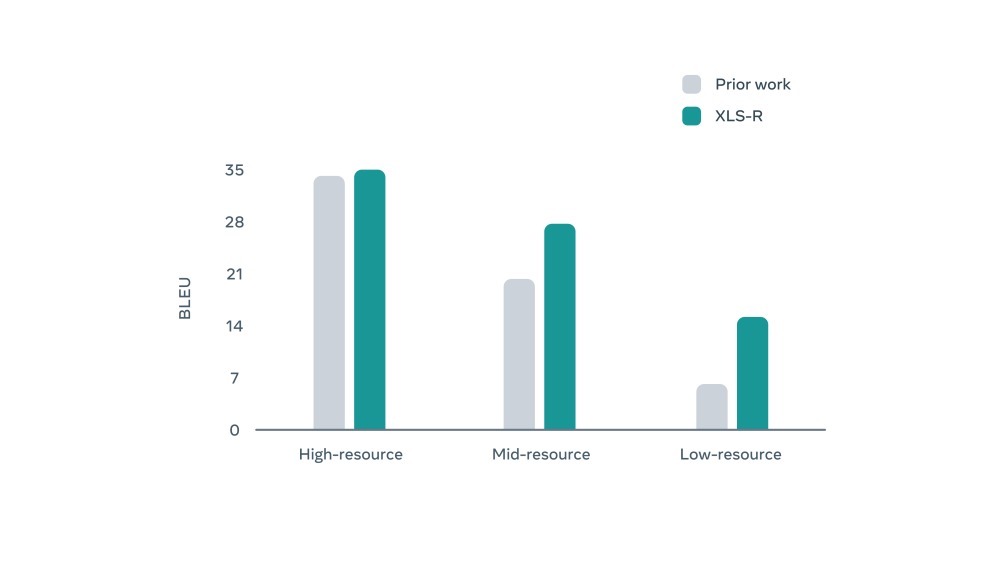
文章插图
而在BLEU语言互译的结果中,无论是在参考数据较多或较少情况,都能获得更高测试分数。
Meta接下来希望透过单一语言学习模型即可对应识别全球超过7000种语言,并且缩减不同语言之间沟通落差,让不同语言背景的用户日后可以更流畅地沟通。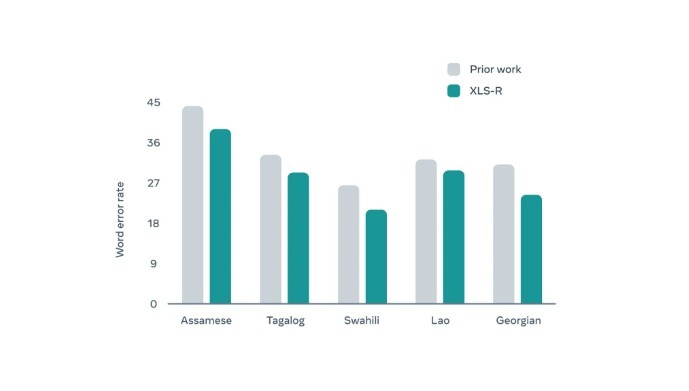
文章插图
除了Meta持续投入语言互译技术发展,包含Google、微软、亚马逊等业者也同样借由旗下数据资源建立语言学习模型,并且透过人工智能技术实现实时互译效果,借此打破各地区语言隔阂现象。
例如,Google 目前已经在 Android 操作系统整合运用人工智能技术的即时翻译功能 (Live Translate),不仅可在连接云端情况下支持 108 种语言互译,就算在离线状态也能通过手机数据库实现特定几种语言互译,至于 NVIDIA 则计划借由其GPU 加速方式,借此加快多种语言训练学习效率。
- meta|陈根:Meta或将发布新专利,为元宇宙助力
- Google|全球游戏领域的标杆,MSI&AMD把事情做得很漂亮
- meta|一个24小时就会自毁的网站,在网友的接力下存活了两年
- Oculus|Meta旗下虚拟现实公司Oculus遭反垄断调查
- 1月14日|奇瑞瑞虎8plus插电混动车型公布售价15.18万和16.5
- meta|阿里云到底有多强大?一起来盘点一下它骄人的战绩
- meta|运用好Facebook组群可以带来哪些好处呢?
- F被指收集 4400 万用户数据,Facebook 母公司 Meta 面临 32 亿美元索赔
- 中国电信|中国电信公布断网原因:通信行程码无法显示
- 盖茨|微软将调查对比尔·盖茨性骚扰的指控,结果或于春季公布