威力|颜水成发了个“简单到尴尬”的模型证明Transformer威力源自架构
梦晨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Transformer做视觉取得巨大成功,各大变体频频刷榜,其中谁是最强?
早期人们认为是其中的注意力机制贡献最大,对注意力模块做了很多改进。
后续研究又发现不用注意力换成Spatial MLP效果也很好,甚至使用傅立叶变换模块也能保留97%的性能。
争议之下,颜水成团队的最新论文给出一个不同观点:
其实这些具体模块并不重要,Transformer的成功来自其整体架构。
文章插图
他们把Transformer中的注意力模块替换成了简单的空间池化算子,新模型命名为PoolFormer。
这里原文的说法很有意思,“简单到让人尴尬”……
文章插图
测试结果上,PoolFormer在ImageNet-1K上获得了82.1%的top-1精度。
(PyTorch版代码已随论文一起发布在GitHub上,地址可在这篇推文末尾处获取。)
同等参数规模下,简单池化模型超过了一些经过调优的使用注意力(如DeiT)或MLP模块(如ResMLP)的模型。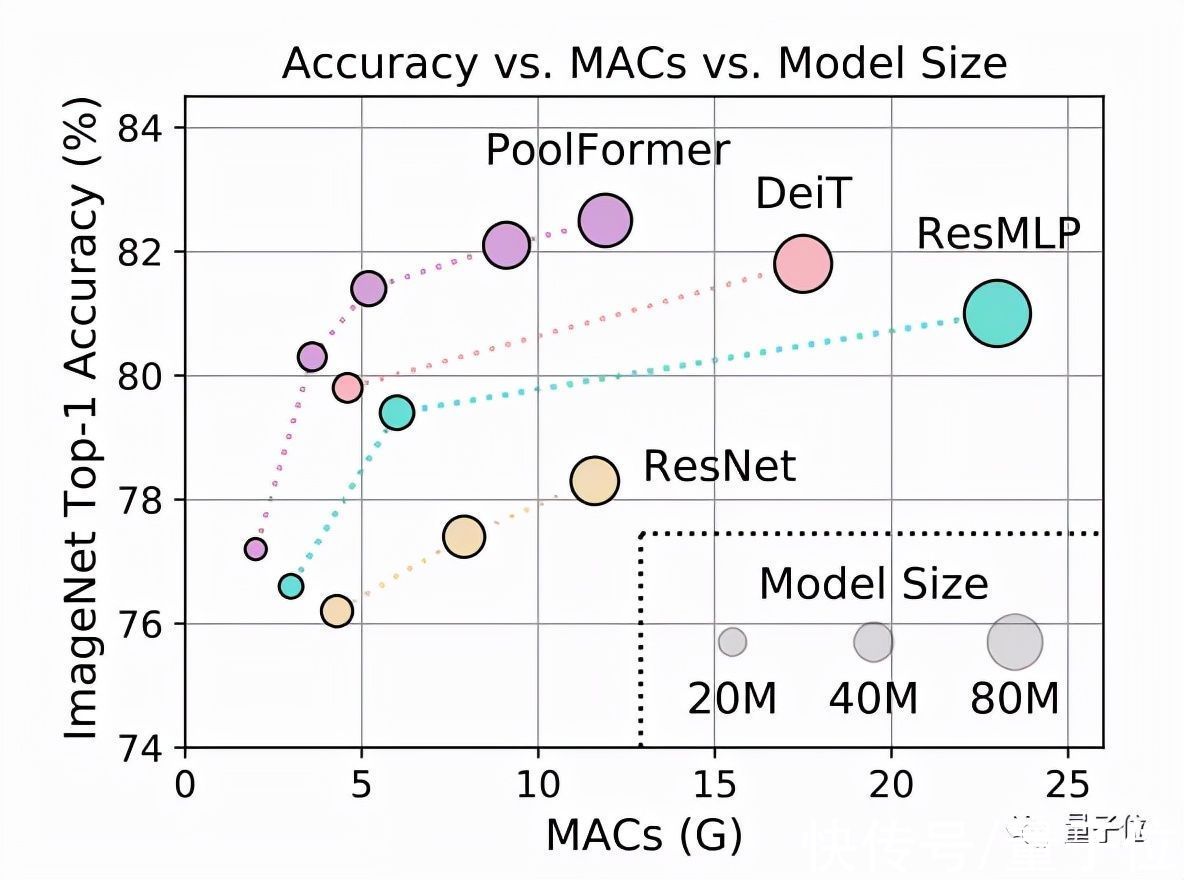
文章插图
这个结果让一些围观的CVer直接惊掉下巴:
文章插图
太好奇了,模型简单到什么样才能令人尴尬?
PoolFormer整体结构与其他模型类似,PoolFormer只是把token mixer部分换了一下。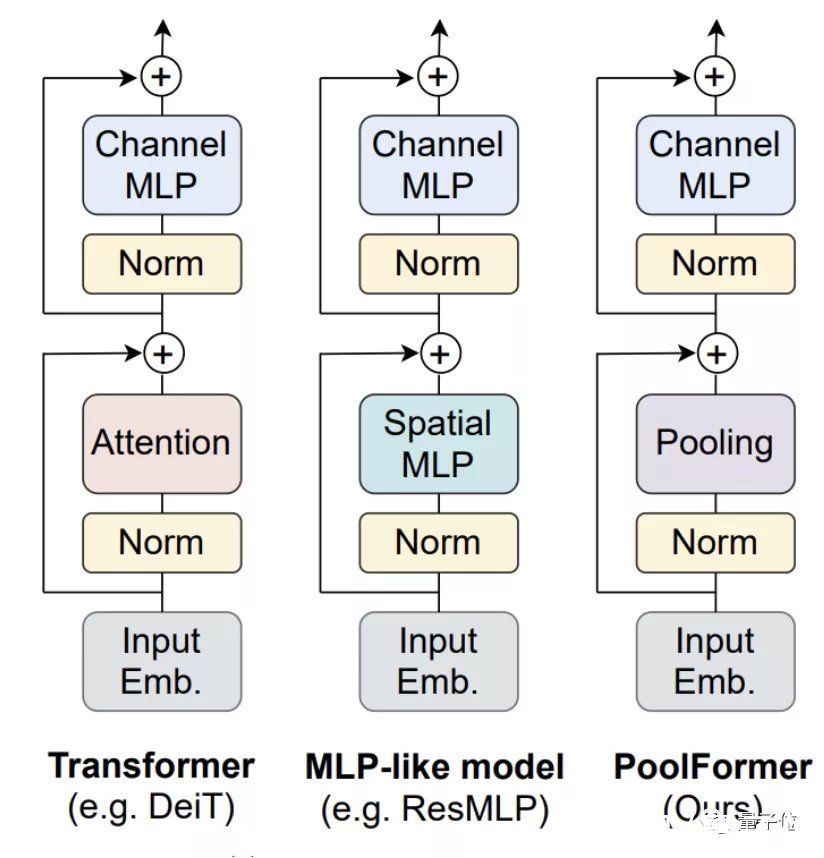
文章插图
因为主要验证视觉任务,所以假设输入数据的格式为通道优先,池化算子描述如下: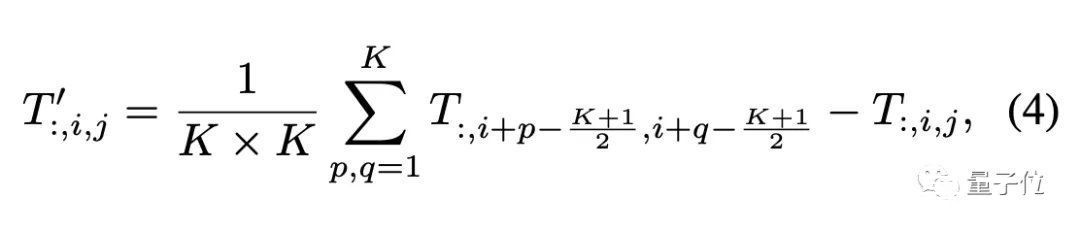
文章插图
PyTorch风格的伪代码大概是这样:
文章插图
池化算子的复杂度比自注意力和Spatial MLP要小,与要处理的序列长度呈线性关系。
其中也没有可学习的参数,所以可以采用类似传统CNN的分阶段方法来充分发挥性能,这次的模型分了4个阶段。
假设总共有L个PoolFormer块,那么4个阶段分配成L/6、L/6、L/2、L/6个。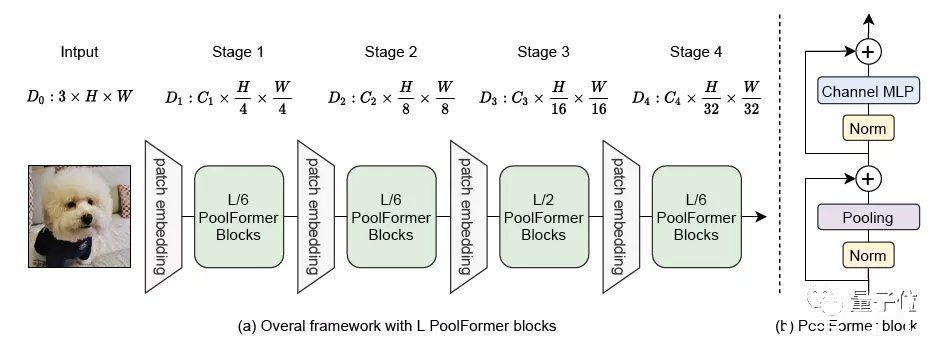
文章插图
每个阶段的具体参数如下: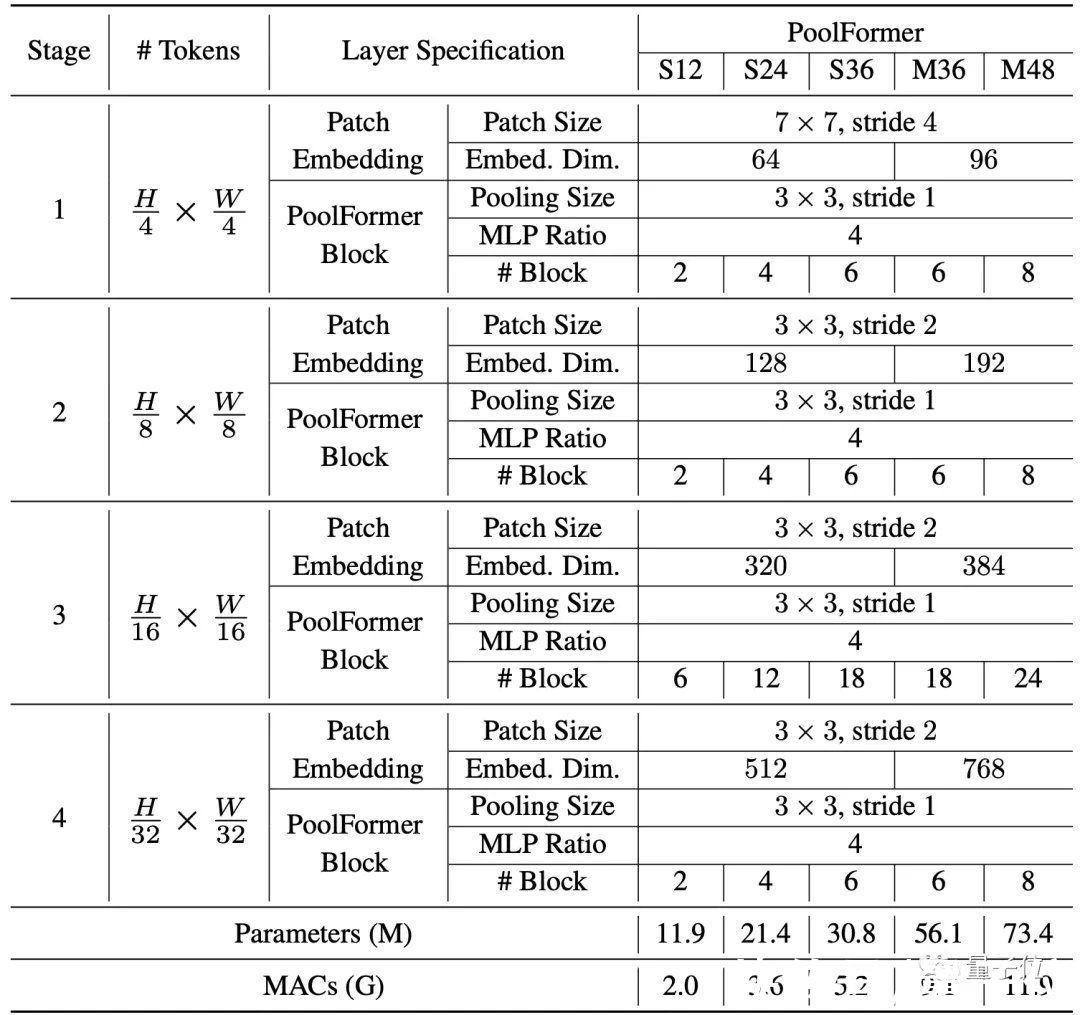
文章插图
PoolFormer基本情况介绍完毕,下面开始与其他模型做性能对比。
【 威力|颜水成发了个“简单到尴尬”的模型证明Transformer威力源自架构】首先是图像分类任务,对比模型分为三类:
- CNN模型ResNet和RegNetY
- 使用注意力模块的ViT、DeiT和PVT
- 使用Spatial MLP的MLP-Mixer、ResMLP、Swin-Mixer和gMLP
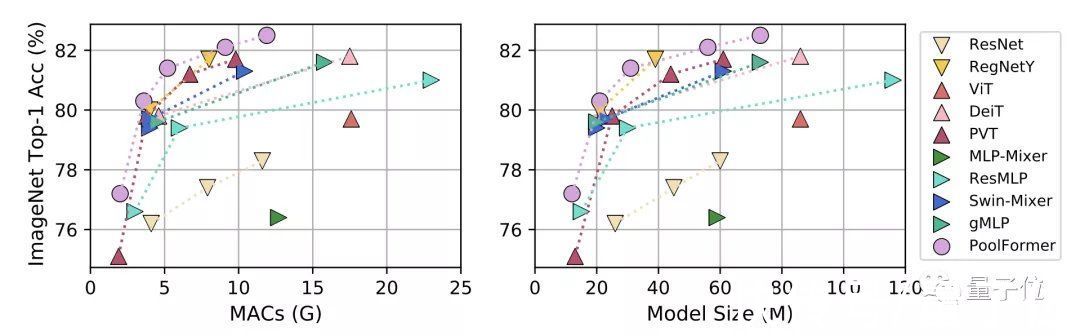
文章插图
目标检测和实例分割任务上用了COCO数据集,两项任务中PoolFormer都以更少的参数取得比ResNet更高的性能。
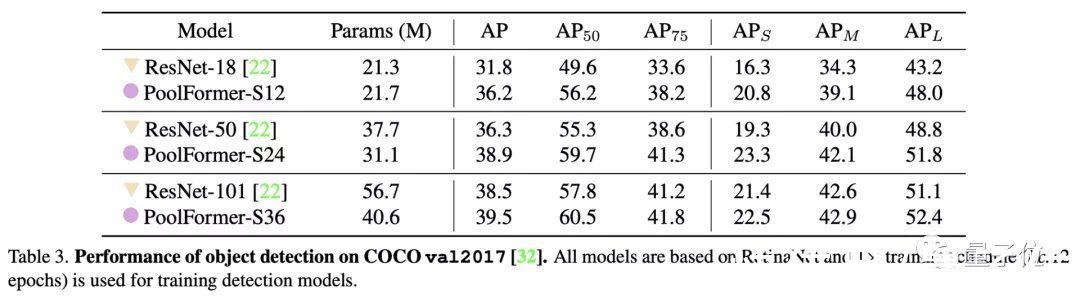
文章插图
△目标检测
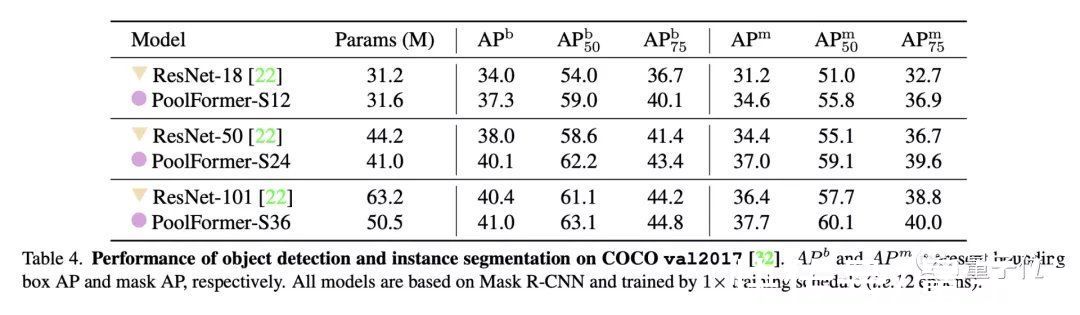
文章插图
△实例分割
最后是ADE20K语义分割任务,PoolFormer的表现也超过了ResNet、ResNeXt和PVT。
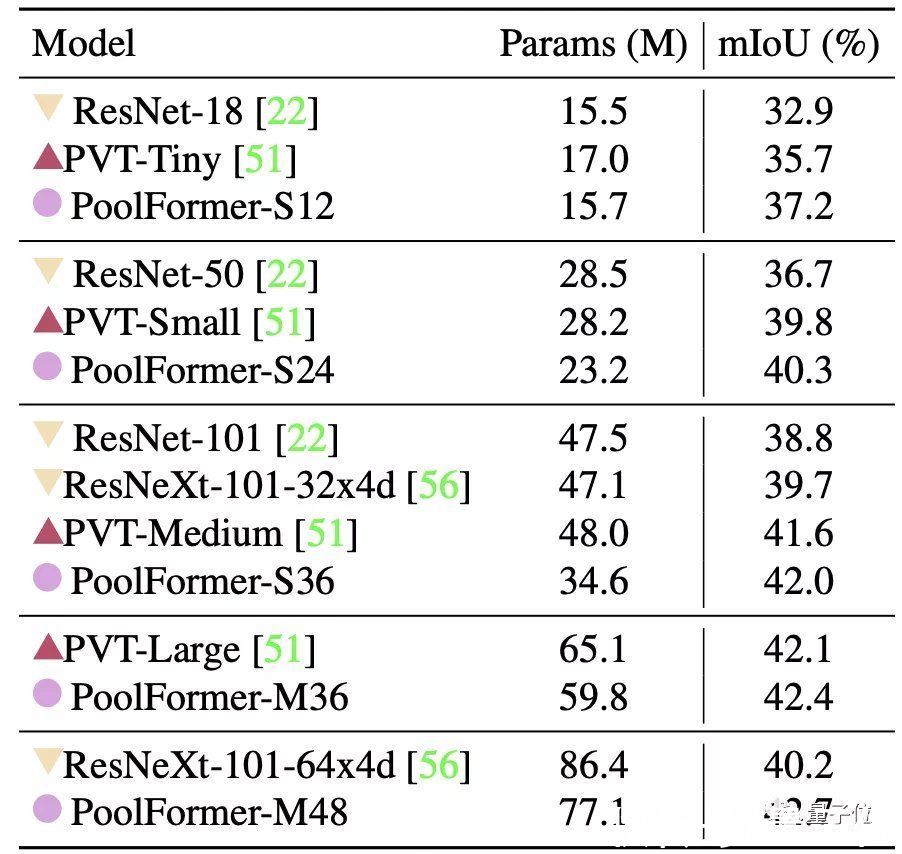
文章插图
消融实验上面可以看出,几大视觉任务上PoolFormer都取得了有竞争力的成绩。
不过这还不足以支撑这篇论文开头提出的那个观点。
- 小米科技|预算只有两三千买这三款,颜值性能卓越,没有超高预算的用户看看
- |盘点三款外观颜值最适合春节的手机:一款比一款好看,性价比很高
- 海尔|燃魂时刻,高颜值也有好手感,又为颜值买了单!
- 小米科技|三月份发布,小米12 Ultra颜值回归,神似Mate40
- 旗舰机|21年最值得入手的四款手机 颜值高+性能强 旗舰机千元机各占两款
- 人才|俄罗斯00后“天才情侣”加入华为,高颜值高智商情侣,网友慕了
- OPPO|直角边框高颜值,拥有出色手感的OPPO A96将于明日开售
- iqoo|颜值高配置强,年底换机小米12、iQOO 9值得入手
- 华为matebook d|英特尔赛扬G6900展现新架构威力,超频后单核性能与酷睿i9-10900K相当
- 读特客户端?深圳新闻网2022年1月14日讯(记者 罗瑜 实习生 韦秋颜 )1月6日|易星标技术荣获集成电路领域“创芯新锐奖”