云从科技&上海交大的跨模态技术成果:探索多层关系的REMNLP 2021 | 研究者们( 二 )
另一方面,现有的工作往往忽视了不同视频片段之间的关系,或者仅仅采用了几层卷积网络的堆叠,存在计算量大、有噪声影响等缺点,本文的研究者们提出了一种稀疏连接的图网络,仅仅考虑了起始或者终止时间相同的视频片段,高效地建模了不同视频片段之间的关系,帮助模型更好地区分视觉上相似的视频片段。
文章插图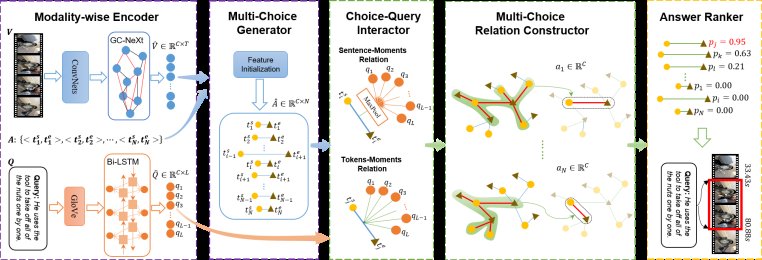
文章插图
RaNet一共包含5个部分:(1)多模态的特征编码模块;(2)候选视频片段的生成模块;(3)候选视频片段和查询语句的交互模块;(4)不同视频片段的关系构建模块;(5)结果选择模块。
- 特征编码模块中,研究者们采用了在时序动作检测(Temporal Action Localization)中表现优异的GC-NeXt来获取视频序列中的时序信息,使用双向的LSTM来获取语言信息的长时间依赖。
- 候选视频片段生成模块中,研究者们借鉴了之前工作2D-TAN的方式,构建了一个二维的时序网格图,每一个小网格都代表一个候选视频片段,其特征是由起始时间帧的特征和终止时间帧的特征串联而得。
文章插图
- 视觉语言交互模块中,研究者们同时构建了视频片段-句子层面的关系和视频片段-单词层面的关系。对于视频片段和句子的关系,研究者们之间对语言特征进行max-pooling,然后和视频片段特征进行点乘。对于视频片段和单词的关系,研究者们通过语言特征和视频片段特征首先构建出一个注意力权重矩阵,然后再与视频片段特征交互,动态地生成query-aware的视频片段表征。这种粗粒度和细粒度结合的方式能够充分地交互视觉和语言两种模态之间的信息。
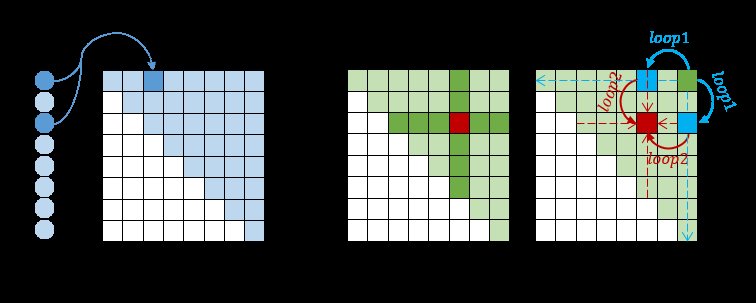
- 视频片段关系构建模块中,研究者们将每个候选视频片段视作图的点,将这些视频片段之间的关系视作图的边,构建了视频片段关系的图网络模型。考虑到重叠比较高的视频片段关联性更强,研究者们在构建图时仅考虑了和当前候选视频片段具有相同起始时间或者终止时间的视频片段,在网格图中就是一种十字架的形式。这样构建图的方式不仅可以减少不相关视频片段带来的噪声影响,还能有效提高模型的效率。
- 结果选择模块中,研究者们采用一个卷积层和sigmoid激活层为每个候选视频片段进行打分,根据得分从大到小排序,选择top-1或者top-5作为最终的预测视频片段。
- 小米科技|不聊性能只谈拍照!新旗舰反向升级成潮流,拍照手机如何选?
- 三星|试图挽回中国市场,国际大厂不断调价,从高端机皇跌到传统旗舰价
- 芯片|上市仅4个月,跌价1000元,微云台主摄+6nm芯片+4400mAh
- 小米科技|预算只有两三千买这三款,颜值性能卓越,没有超高预算的用户看看
- CPU|元宇宙+高端制造+人工智能!公司已投高科技超100亿,股价仅3元
- 计算|雄安城市计算(超算云)中心主体结构封顶
- 小米科技|RTX3060的性能到底如何?相比RTX2060提升有多大?
- 蓝思科技|苹果与34家中国供应商断绝合作,央视呼吁:尽快摆脱对苹果依赖
- 百度|马化腾的一句话,腾讯市值一小时暴涨1400亿港币,马云格局还是小了
- 一加科技|16+1TB,一加10T秀肌肉,顶级4nm+5100mAh+80W