云从科技&上海交大的跨模态技术成果:探索多层关系的REMNLP 2021 | 研究者们

文章插图
EMNLP(Conference on Empirical Methods in Natural Language Processing)是计算语言学和自然语言处理领域的顶级国际会议之一,由国际语言学会(ACL)旗下SIGDAT组织。EMNLP论文入选标准十分严格,今年论文录取率仅23.3%,相比去年略有下降。EMNLP学术会议上展示的研究成果,被认为代表着自然语言处理领域的前沿水平与未来发展方向。
本次入选论文,围绕“基于语言查询的视频片段定位”这一视觉-文本的跨模态任务,将NLP与视觉技术结合,技术让机器同时具备“理解文字”和“看懂视频”的能力:能够更精准地读懂文字,并理解视频内容,在整段视频中找出与给定文字相对应的视频片段。该项成果在多个数据集上,都取得了优于过去研究的表现。
这一成果在技术研究与实践领域都具有十分重要的意义:
在技术上让机器实现“多感官进化”:如今视觉、听觉等单点AI技术,将越来越难以满足多样的应用需求。该项技术旨在让机器向完成“跨模态任务”进化:让机器能够同时掌握视觉、文字等多种模态的信息,做到像人类一样看懂、听懂、读懂,拥有全面的能力。近年来在学界,跨模态任务已成为一大研究热点,为AI领域注入新的活力。
突破单点技术,扩大跨模态应用场景:在实战场景中,随着高清摄像头的普及以及网络媒体的快速发展,各式各样的视频呈海量增长态势,自动化视频处理AI技术也迎来巨大的需求。本项成果基于语言查询的视频片段定位技术,能够有效解决治理、出行等多领域的难点问题,例如公共场合下的安全监控、社交媒体视频内容的审核等等,突破以往的单点技术应用瓶颈,带来数量级的效率提升。
NLP等决策技术被认为是AI领域下一个技术突破口,使机器拥有理解、思考、分析决策的能力,为人机交互、行业应用等带来颠覆式改变。云从科技、上海交通大学提出Relation-aware Network,探索视频片段定位任务中的多种层面关系。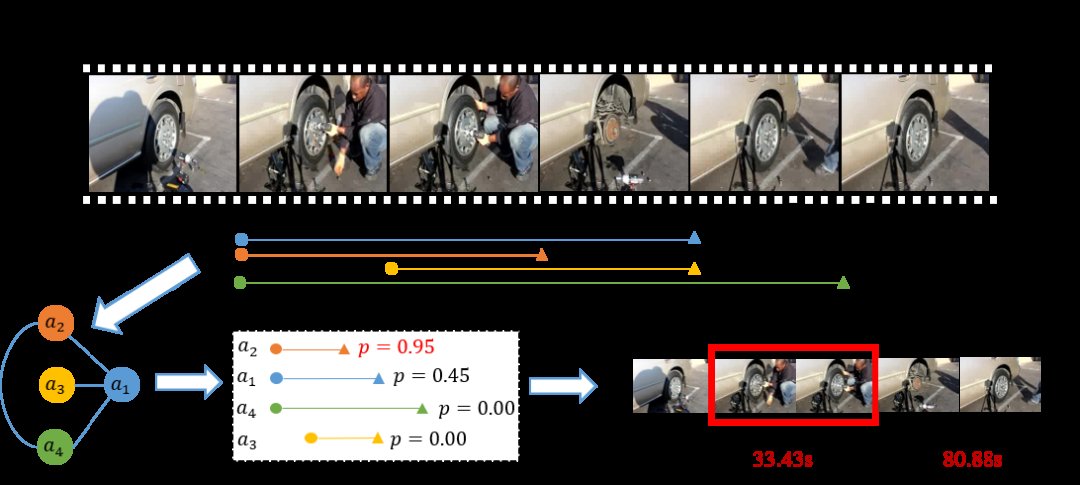
文章插图
一方面,已有的视频片段定位方法通常只考虑了视频片段和整个句子的关系,而忽略了视频片段和句子中每个词语这种更加细致的关系,这样就不能全面地交互视觉和语言的信息,云从和上交联合团队的研究者们提出了一种coarse-and-fine的交互方式,从粗粒度和细粒度的角度同时考虑了视频片段-句子层面和关系和视频片段-词语层面的关系。
- 小米科技|不聊性能只谈拍照!新旗舰反向升级成潮流,拍照手机如何选?
- 三星|试图挽回中国市场,国际大厂不断调价,从高端机皇跌到传统旗舰价
- 芯片|上市仅4个月,跌价1000元,微云台主摄+6nm芯片+4400mAh
- 小米科技|预算只有两三千买这三款,颜值性能卓越,没有超高预算的用户看看
- CPU|元宇宙+高端制造+人工智能!公司已投高科技超100亿,股价仅3元
- 计算|雄安城市计算(超算云)中心主体结构封顶
- 小米科技|RTX3060的性能到底如何?相比RTX2060提升有多大?
- 蓝思科技|苹果与34家中国供应商断绝合作,央视呼吁:尽快摆脱对苹果依赖
- 百度|马化腾的一句话,腾讯市值一小时暴涨1400亿港币,马云格局还是小了
- 一加科技|16+1TB,一加10T秀肌肉,顶级4nm+5100mAh+80W