|11个常见的分类特征的编码技术

文章图片
文章图片
文章图片
文章图片
文章图片
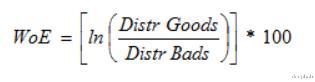
文章图片

文章图片
文章图片

文章图片
【|11个常见的分类特征的编码技术】机器学习算法只接受数值输入 , 所以如果我们遇到分类特征的时候都会对分类特征进行编码 , 本文总结了常见的11个分类变量编码方法 。
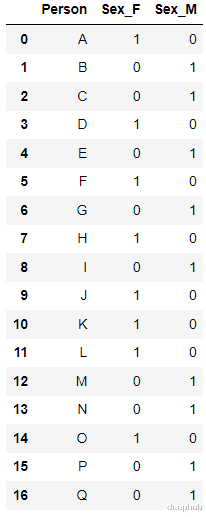
1、ONE HOT ENCODING最流行且常用的编码方法是One Hot Enoding 。 一个具有n个观测值和d个不同值的单一变量被转换成具有n个观测值的d个二元变量 , 每个二元变量使用一位(0 , 1)进行标识 。
例如:
编码后
最简单的实现是使用pandas的' get_dummies
new_df=pd.get_dummies(columns=[‘Sex’
data=https://mparticle.uc.cn/api/df)
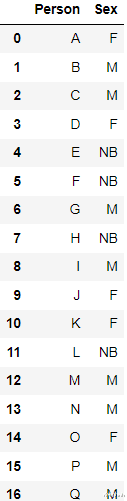
2、Label Encoding为分类数据变量分配一个唯一标识的整数 。 这种方法非常简单 , 但对于表示无序数据的分类变量是可能会产生问题 。 比如: 具有高值的标签可以比具有低值的标签具有更高的优先级 。
例如上面的数据 , 我们编码后得到了下面的结果:
sklearn的LabelEncoder 可以直接进行转换:
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
df[‘Sex’
=le.fit_transform(df[‘Sex’
)
3、Label BinarizerLabelBinarizer 是一个用来从多类别列表创建标签矩阵的工具类 , 它将把一个列表转换成一个列数与输入集合中惟一值的列数完全相同的矩阵 。
例如这个数据
转化后结果为
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
new_df[‘Sex’
=lb.fit_transform(df[‘Sex’
)
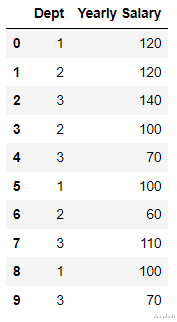
4、Leave one out EncodingLeave One Out 编码时 , 目标分类特征变量对具有相同值的所有记录会被平均以确定目标变量的平均值 。在训练数据集和测试数据集之间 , 编码算法略有不同 。因为考虑到分类的特征记录被排除在训练数据集外 , 因此被称为“Leave One Out” 。
对特定类别变量的特定值的编码如下 。
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where
ci = encoded value for ith record
tj = target variable value for jth record
n = number of records with the same categorical variable value
R = regularization factor
εi = zero mean random variable with normal distribution N(0 s)
例如下面的数据:
编码后:
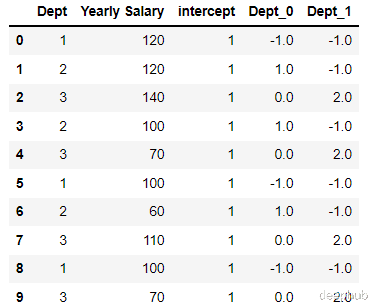
为了演示这个编码过程 , 我们创建数据集:
import pandas as pd;
data = https://mparticle.uc.cn/api/[[‘1’ 120
[‘2’ 120
[‘3’ 140
[‘2’ 100
[‘3’ 70
[‘1’ 100
[‘2’ 60
[‘3’ 110
[‘1’ 100
[‘3’ 70
df = pd.DataFrame(data columns = [‘Dept’’Yearly Salary’
)
然后进行编码:
- |一个时代的落幕:明年2月起,微软Windows 10将永久禁用IE11
- 手机行业|齿谐波,在电机运行中的具体表现有哪些?
- 比亚迪|有技术护城河的比亚迪跟进特斯拉“官降”?经销商:双11促销活动
- 音响|烧友的第一套音响怎么选?绝不踩雷的平价音响套装不可错过
- |大数据和云计算的发展
- |可以K歌的智能屏,添添旋转智能屏T10
- 鼠标|艺术加持科技!这次整点不一样的跨界新玩法!
- 双十一|iPhone 14在双11期间翻身了,销量数据喜人,如何翻身的?
- 双11最后一天|双11最划算的三款手机,预算2k以内首选,错过等明年
- 荣光|小米逐渐变更路线,旗舰走中端旗舰的道路,结局只会两败俱伤