本项工作中,我们将一类新的平衡损失函数引入 NLP,用于多标签文本分类任务,并使用 Reuters-21578(一个通用的小型数据集)和 PubMed(一个生物医学领域的大型数据集)数据集进行了实验。对于这两个数据集,分布平衡损失函数在总指标上优于其他损失函数,并且显著改善了尾部标签的模型表现。我们认为,平衡损失函数为多标签文本分类的应用提供了一个有效策略。多标签文本分类中,二值交叉熵(Binary Cross Entropy, BCE)是较常用的损失函数 (Bengio et al., 2013)。原始的 BCE 容易被大量头部标签或负样本干扰。近年来,一些新的损失函数通过调节 BCE 的权重,实现了模型训练过程的相对平衡。我们在此回顾了三类损失函数设计。Focal loss (FL)通过模型对数据实例标记标签的“难易程度”为 BCE 设计权重 (Lin et al., 2017)。对于同一数据实例,相比可轻松分类(p值接近真实值)的标签,难以标记(p值远离真实值)的标签将获得比 BCE 更高的权重。由于 FL 在模型训练过程中良好的自适应效果,下述两类损失函数也采用了这一组件。Class-balanced focal loss(CB)通过估计数据采样的有效数量,将每个标签增量训练数据的边际效用纳入考虑,在不同训练数据支持的标签间调节权重 (Cui et al., 2019)。Distribution-balanced loss(DB,分布平衡损失函数)则是在 FL 基础上添加了两部分组件 (Wu et al., 2020)。其一为 Rebalancing 组件,减少了标签连锁带来的冗余信息,其二为 Negative Tolerant Regularization (NTR)组件,在不同正负样本数目的标签间调节权重,降低尾部标签的阈值。上述损失函数的具体设计如图3所示(简单起见已略去求和平均项)。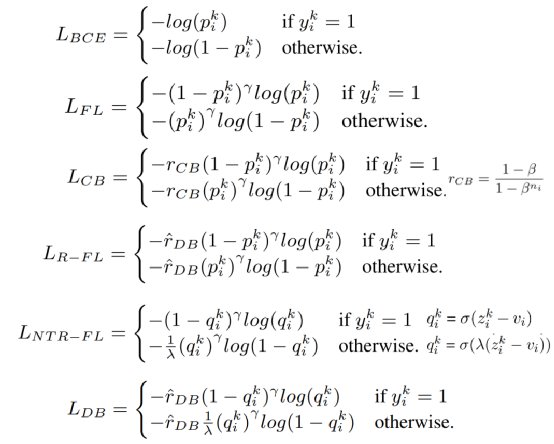
文章插图
图3 损失函数的具体设计。
本项工作中,我们使用了两个不同数据量和领域的多标签文本分类数据集(表 1)。Reuters-21578 数据集包含1987 年刊登在路透社的一万多份新闻文章(Hayes and Weinstein, 1990)。我们按照(Yang and Liu, 1999)使用的训练-测试分割数据,并将 90 个标签平均分为头部(30 个标签,各含 ≥35 个实例)、中部(31 个标签,各含 8-35 个实例)和尾部(30 个标签,各含 ≤8 个实例)标签的子集。PubMed 数据集则来自 BioASQ 竞赛(Licence:8283NLM123),包含PubMed 文章的标题、摘要及对应的生物医学主题词标记 (MeSH)(Tsatsaronis et al.,2015; Coordinators, 2017)。类似地,18211个标签按分位数分为头部(6018 个标签,各含≥50 个实例)、中部(5581 个标签,各含 15-50 个实例)和尾部(6612 个标签,各含 ≤15 个实例)标签的子集。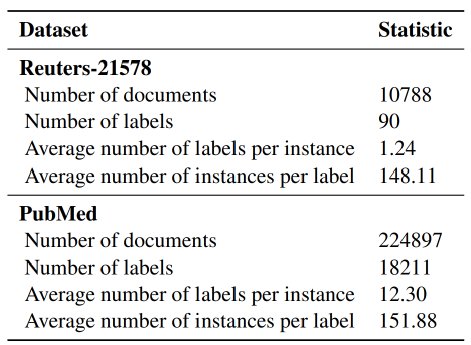
文章插图
表1 实验用数据集的基本信息
我们比较了不同损失函数与经典 SVM one-vs-rest 模型的表现。对于各个数据集和模型,我们计算了标签集整体以及头部、中部、尾部标签子集的micro-F1 和 macro-F1 得分(Wu et al., 2019;Lipton et al., 2014 )。表 2 汇总了不同损失函数的实验结果。Reuters-21578 结果中,BCE 的表现最差。依次对比 micro-F1 和 macro-F1之间、及不同组间的得分可以看出长尾分布的影响。PubMed 数据由于不平衡更明显,长尾分布的影响更大。