
文章插图

文章插图
作者简介:黄毅,本文一作,目前为罗氏集团的数据科学家,研究领域为自然语言处理的生物医学应用。论文链接:https://arxiv.org/pdf/2109.04712.pdf文章源码:https://github.com/Roche/BalancedLossNLP多标签文本分类是自然语言处理中的一类经典任务,训练模型为给定文本标记上不定数目的类别标签。然而实际应用时,各类别标签的训练数据量往往差异较大(不平衡分类问题),甚至是长尾分布,影响了所获得模型的效果。重采样(Resampling)和重加权(Reweighting)常用于应对不平衡分类问题,但由于多标签文本分类的场景下类别标签间存在关联,现有方法会导致对高频标签的过采样。本项工作中,我们探讨了优化损失函数的策略,尤其是平衡损失函数在多标签文本分类中的应用。基于通用数据集 (Reuters-21578,90 个标签) 和生物医学领域数据集(PubMed,18211 个标签)的多组实验,我们发现一类分布平衡损失函数的表现整体优于常用损失函数。研究人员近期发现该类损失函数对图像识别模型的效果提升,而我们的工作进一步证明其在自然语言处理中的有效性。
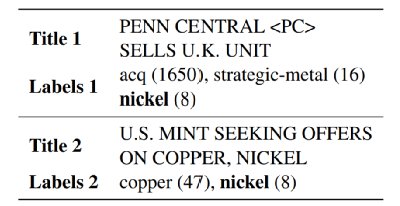
多标签文本分类是自然语言处理(NLP)的核心任务之一,旨在为给定文本从标签库中找到多个相关标签,可应用于搜索(Prabhu et al., 2018)和产品分类(Agrawal et al., 2013)等诸多场景。图 1 展示了通用多标签文本分类数据集 Reuters-21578 的样例数据(Hayes and Weinstein, 1990)。
文章插图
图1 Reuters-21578 的样例数据(仅展示文章标题)。标签后面的数字代表数据集中带有该标签的数据实例个数。当标签数据存在长尾分布(不平衡分类)和标签连锁(类别共现)时,多标签文本分类会变得更加复杂(图2)。长尾分布,指的是一小部分标签(即头部标签)有很多数据实例,而大多数标签(即尾部标签)只有很少数据实例的不平衡分类情况。标签连锁,指的是头部标签与尾部标签共同出现导致模型对头部标签的权重倾斜。现有的 NLP 解决方案包括但不限于:在分类中对尾部标签重采样(Estabrooks et al., 2004; Charte et al., 2015),模型初始化时将类别共现信息纳入考虑(Kurata et al., 2016),以及将头尾部标签混合的多任务架构方案 (Yang et al., 2020) 。但这些方案依赖于模型架构的专门设计,或不适用于长尾分布数据。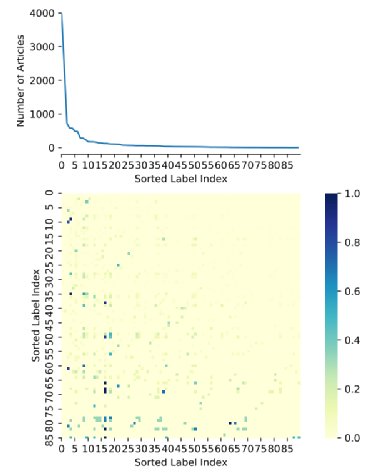
文章插图
图2 Reuters-21578的长尾分布和标签连锁现象。
热图矩阵展示了第i列标签在含第j行标签数据实例中的条件概率p(i|j)近年来,计算机视觉(CV)领域也有不少关于多标签分类的研究。其中,优化损失函数的策略已被用于多种 CV 任务,如对象识别(Durand et al., 2019; Milletari et al., 2016)、语义分割(Ge et al., 2018)与医学影像(Li et al., 2020a)等。平衡损失函数,如 Focal loss (Lin et al., 2017)、Class-balanced loss (Cui et al., 2019) 和 Distribution-balanced loss (Wu et al., 2020) 等,提供了针对多标签图像分类的长尾分布和标签连锁问题的解决方案。由于损失函数的调整可以独立于模型架构地灵活嵌入常见模型,NLP 中也逐步有类似的优化损失函数的策略探索(Li et al., 2020b; Cohan et al., 2020)。例如,(Li et al., 2020b) 将医学图像分割任务中的 Dice loss (Milletari et al., 2016) 引入 NLP,显著改善了多种任务的模型效果。