基于相似样本检索的在线更新机器翻译系统|EMNLP 2021 | 样本( 三 )
文章插图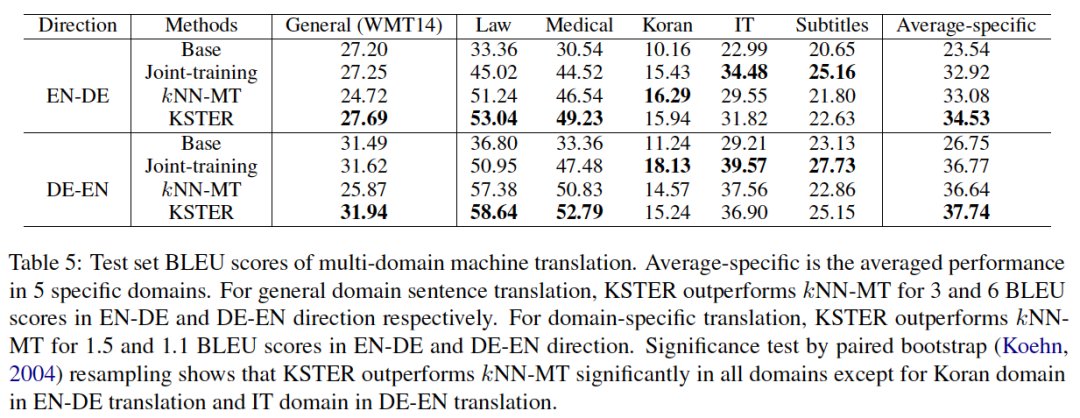
文章插图
文章插图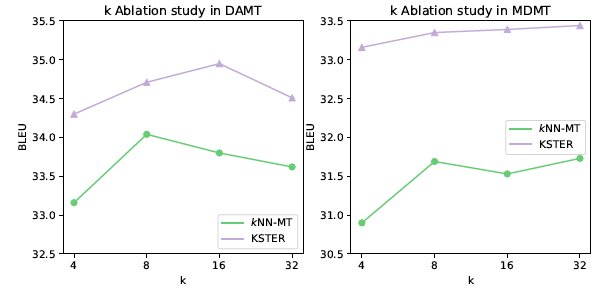
文章插图
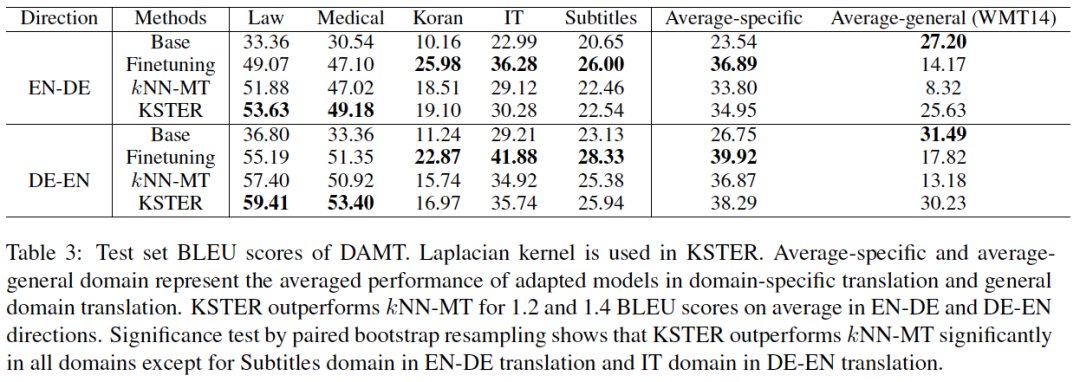
图8 检索不同数量样本 k 时,kNN-MT 和 KSTER 的翻译效果
图9 验证了检索丢弃这种训练策略的必要性。在不使用检索丢弃策略时,KSTER模型产生了严重的过拟合。而使用检索丢弃策略后,过拟合的现象得到明显缓解。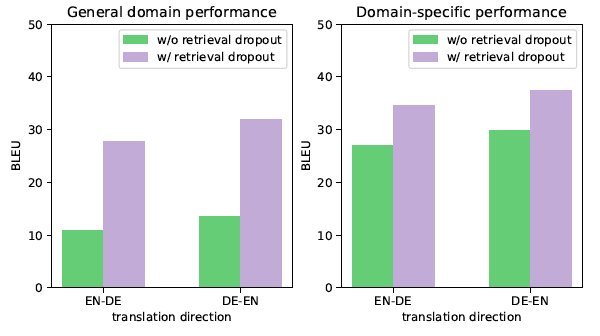
文章插图
如 图10 所示,由于训练数据中没有出现过“字节跳动”这种新兴实体,以及“C位”这类新词,翻译系统对它们的翻译效果是不好的。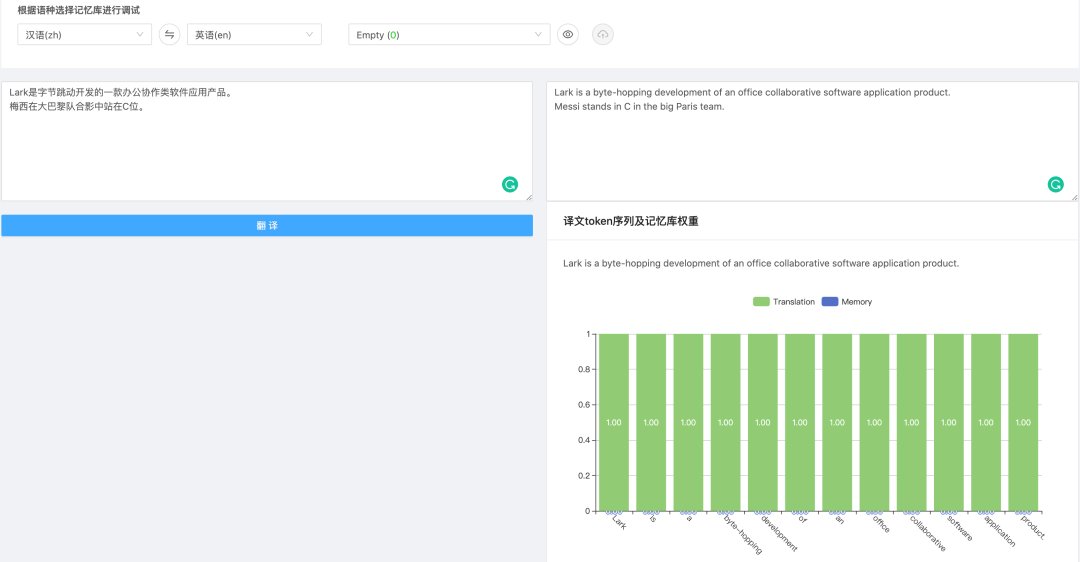
文章插图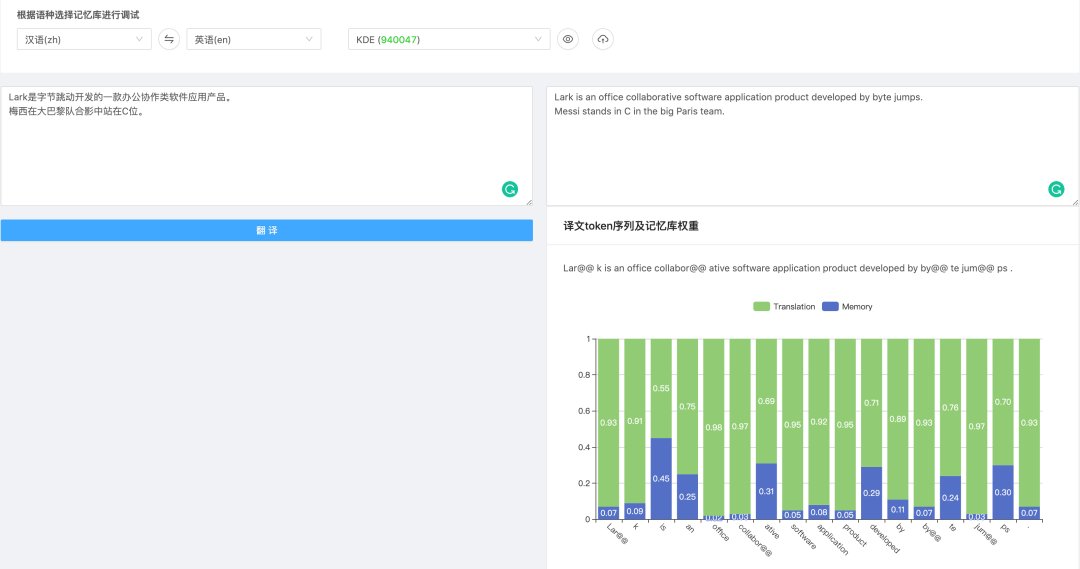
文章插图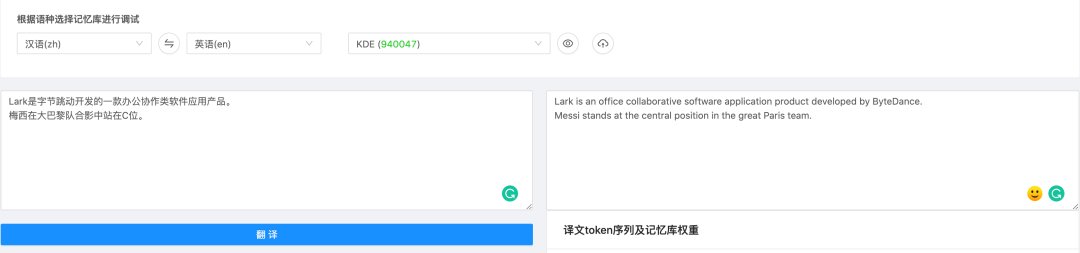
文章插图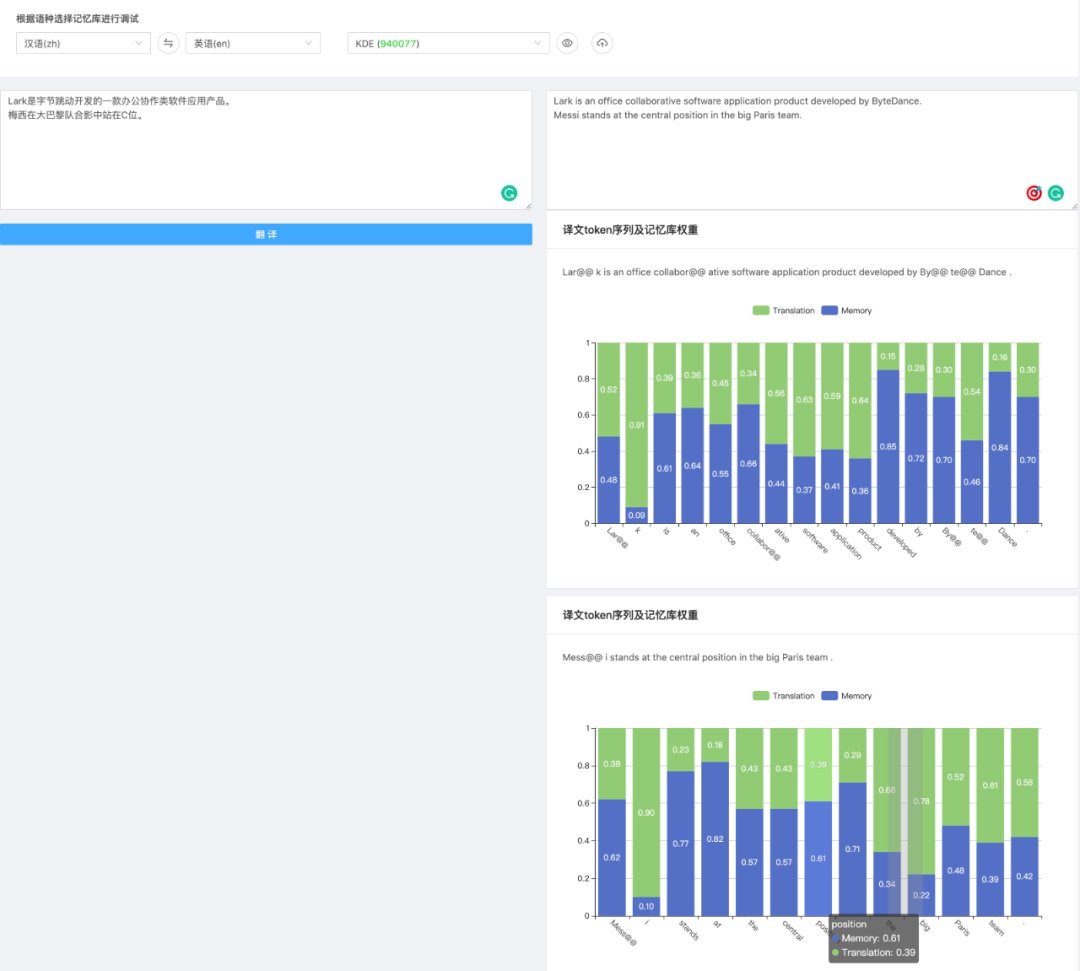
文章插图
- 测试|解码自动驾驶商业化进阶的亦庄样本
- 恶意软件|报告称 2021 年 Linux 的恶意软件样本数量增加了 35%
- 中文|爱数智慧CEO张晴晴:基于”情感“的人机交互,要从底层数据开始
- 米家|从零开始,基于群晖轻松玩转开源homeassistant智能家居前期搭建
- |基于LM2576HV-ADJ的多输出电源
- 进步奖|招标股份董秘回复:公司研发的生态环境数字孪生平台在下游应用领域更多基于客户自身需求
- 京东云打造“特色样本” 助推数字经济发展
- 基于蜜网的工业互联网协同检测技术研究
- 近日|科学家开发出基于FBG传感原理的触觉传感器应用于微创手术组织触诊
- 墨芯人工智能完成数亿元A轮融资,基于稀疏架构的首颗云端AI芯片即将量产