编码器|中科院软件所在深度神经网络静态代码分析研究中取得进展
IT之家 11 月 9 日消息,据中国科学院官网,近日,中国科学院软件研究所智能软件研究中心研究员武延军、吴敬征课题组在基于深度神经网络的静态代码分析研究中取得进展。
该课题组提出了基于多类型和多粒度的语义代码表示学习模型 ——MultiCode,解决了工业场景中涉及多需求的开发任务时面临的开发开销大、模型集成困难、可扩展性受限等问题。
该课题组的研究实现了在多需求工业场景下的高效开发和准确预测,在漏洞检测、代码克隆检测等任务中得到了具体实践,并获得实际应用。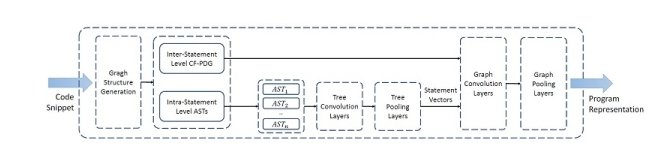
文章插图
▲ MultiCode 基于多类型和多粒度的语义代码表示学习模型框架
据介绍,MultiCode 模型能够学习代码中多种类型和粒度的语义信息,进而支撑多种代码分析任务。课题组提出使用抽象语法树、控制流图、程序依赖图等结构,对代码中不同类型和粒度的语义信息进行建模,并利用树神经网络和图神经网络分别对不同的语义信息进行处理。将该模型作为编码器进行神经网络构建,能够有效适配于不同的代码分析任务。
在漏洞检测和代码克隆检测任务上的评估结果表明,该模型能够在不需要重新构建编码器的情况下,在不同任务中有效地识别并区分不同类别代码的语义,进而支撑多种任务上的预测。
IT之家了解到,相关研究成果发表在软件可靠性工程国际会议(ISSRE 2021)的 Industry Track 上,并被评为最佳实践论文。研究工作得到国家重点研发计划、国家自然科学基金的支持。
文章插图
【 编码器|中科院软件所在深度神经网络静态代码分析研究中取得进展】▲ ISSRE 2021 最佳实践论文奖
- 智能|地震救人新突破!中科院研制出触嗅一体智能仿生机械手
- 荷兰|苹果公司向荷兰“妥协”:将开放交友软件的第三方支付系统
- 恶意软件|报告称 2021 年 Linux 的恶意软件样本数量增加了 35%
- 上海微系统与信息技术研究所|地震救人新突破!中科院研制出触嗅一体智能仿生机械手
- 软件|想提高效率?这五款软件你需要了解
- 软件|在家也能赚钱的方式,适合零基础阅读
- 三星堆|陌陌推行“付费服务”,社交软件成“约X神器”?从业者该收手了
- 芯片|美国秘密封锁的技术,被中科院一举攻破,时间缩短了1000倍
- 阿里巴巴|程序员与软件工程师的区别
- 软件|ui设计培训需要学什么软件?