算法|小白产品必看的推荐系统四步指南( 二 )
类别标签是以某种指定规则将资源归类,一般根据资源的复杂度分为2~5级不等,也有平台分级更多。下图是某瓣的类别标签。
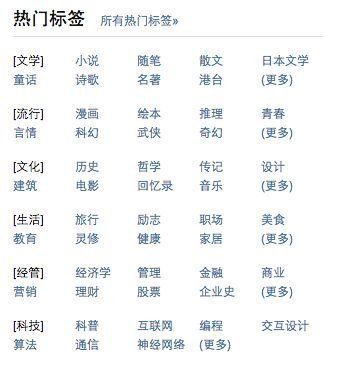
文章插图
关键词标签则是在类别的基础上更细一层,指具体的标签词。比如用户对政治人物感兴趣时,我们发现其主要体现在“特朗普”这个人名上,那关于特朗普的一些商业信息也可以做适当推荐。
通过特征工程我们会为每个用户和资源都打上大量的标签,然后再引入推荐策略。这两类资源标签一般是通过人工标注和机器学习两种方式来添加。但机器学习需要大量的标注量才能达到一定准确度,所以在产品初期会更依赖于人工标注和词库拓展。到一定数据规模后,再训练机器学习。最后通过持续的机器学习+人工修正,整个特征工程就能达到一定的识别准确度。
三、推荐策略当我们将用户标签和资源标签采集到后,接下来就是推荐策略的部分,推荐策略一般分为召回和排序两大模块。
1. 推荐系统组成用户访问产品时,我们优先从资源库中召回符合用户标签的资源,这里通常是千/万的数据量级,然后根据这些资源的标签匹配度、时间等进行排序展示,成熟的产品还会涉及到精排和重排,根据用户对每条资源的使用行为,实时改变后续资源的排序。实际工作中会由工程师将召回和排序封装成一个推荐引擎,然后内部各环节都有相应的算法人员跟进优化,也就是所谓的调参。
2. 召回/排序具体策略召回和排序是推荐算法中两个相当庞大的工程,涉及方法众多,这里仅和大家简单分享下其中主要的策略组成。
1)召回
资源库中的资源千千万,但最终给用户展示的只有几十甚至十几条,如果直接对所有物料计算排序不仅成本极高且响应较差。所以我们需要对物料进行初筛,针对性召回用户可能感兴趣的一批候选集。传统的标准召回结构一般是多路召回,主要分为“个性化召回”和“非个性化召回”两大类,个性化召回指针对用户特征进行召回,主要有“兴趣标签召回”、“协同过滤召回”等;非个性化主要指“热门召回”、“冷启动召回”这类统一特征的召回。
实际应用中会根据不同场景,选择上述一种或多种召回策略进行。比如搜索场景下的召回排序,你在淘宝搜索某件商品后,再次访问列表时便会发现该类商品排在首位。而召回的多样性是很重要的,有时候多一路召回策略产生的效果也许会是惊人的,而召回质量也很大程度上决定着推荐系统的上下限。
下图为其中“协同过滤召回”的示意图:
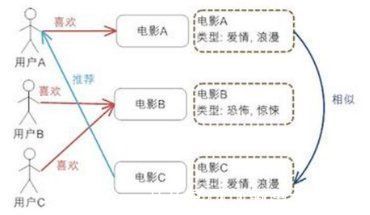
文章插图
2)排序
一般当候选集达到“千”这个数量级,我们就开始需要排序策略了,一般通过粗排和精排将候选集缩减在“百”级并进行打分,按分值top排序,再根据用户的实时反馈进行重排序,将数据量缩至“十”这个级别进行排序展示。
排序的目标是根据业务目标来不断变化的,最早期由于业务目标简单,需要聚焦的时候,往往会选取?个指标来重点优化排序。但随着多路召回策略的增多,到中期就会发现单?指标对整体的提升已经非常有限了。这时候我们就需要引入多目标排序来解决这些问题,比如结合时间、兴趣、热点、位置等众多维度的数据进行综合排序,这里因需要注意不同的用户场景其排序侧重点不同,所以需要不同的排序策略来提高精度。比如兴趣流中更注重兴趣标签,热点信息流中更重视互动数据等。
- 苹果|苹果最巅峰产品就是8,之后的产品,多少都有出现问题
- CPU|E5系列处理器——工作室和生产力专业处理器,小白请勿购买
- 发现最小白矮星,其大小相当于月亮,这让科学家很兴奋
- 合规|上海制定反垄断、互联网营销算法、盲盒经营活动等新业态合规指引
- c语言|e观沧海丨算法焉能藏“算计”
- 业务|传统企业里,产品经理失去了话语权
- 上海尊宝音响多款产品获《影音极品》器材大赏奖项
- 噪音|聊聊社交产品中的信号与暗示
- 雷曼巨幕LEDPLAY获IT影响中国2021年度创新产品奖
- iPad|一样是苹果的电子产品,为什么iPhone比iPad贵几千元呢