rep|“非深度网络”12层打败50层,普林斯顿+英特尔:更深不一定更好
晓查 发自 凹非寺 报道 | 公众号 QbitAI“深度”是深度神经网络(DNN)的关键词。但网络越深也就意味着,训练时反向传播的链条更长,推理时顺序计算步骤更多、延迟更高。而深度如果不够,神经网络的性能往往又不好。这就引出了一个问题:是否有可能构建高性能的“非深度”神经网络?普林斯顿大学和英特尔最新的论文证明,确实能做到。他们只用了12层网络ParNet就在ImageNet上达到了接近SOTA的性能。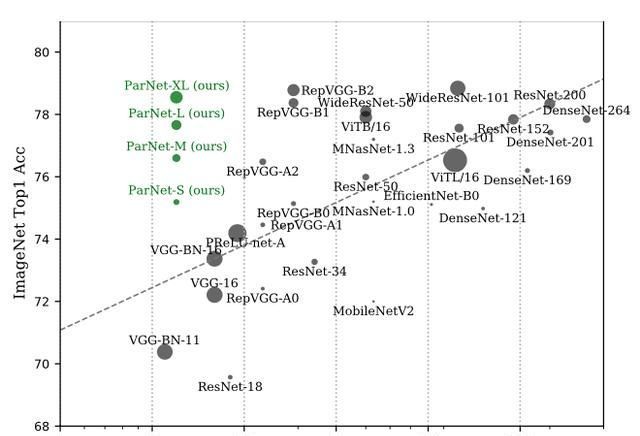
文章插图
ParNet在ImageNet上准确率超过80%、在CIFAR10上超过 96%、在CIFAR100上top-1准确率 达到了81%,另外在MS-COCO上实现了48%的AP。他们是如何在网络这么“浅”的情况下做到的?并行子网提升性能ParNet 中的一个关键设计选择是使用并行子网,不是按顺序排列层,而是在并行子网中排列层。ParNet由处理不同分辨率特征的并行子结构组成。我们将这些并行子结构称为流(stream)。来自不同流的特征在网络的后期融合,这些融合的特征用于下游任务。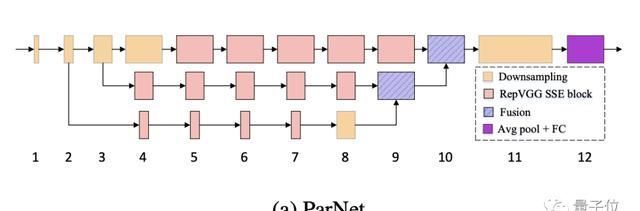
文章插图
在 ParNet 中,作者使用VGG样式的块。但是对于非深度网络来说,只有3×3卷积感受野比较有限。为了解决这个问题,作者构建了一个基于Squeeze-and-Excitation设计的 Skip-Squeeze-Excitation (SSE) 层。使用SSE模块修改后的Rep-VGG称之为Rep VGG-SSE。对于ImageNet等大规模数据集,非深度网络可能没有足够的非线性,从而限制了其表示能力。因此,作者用SiLU激活函数替代了ReLU。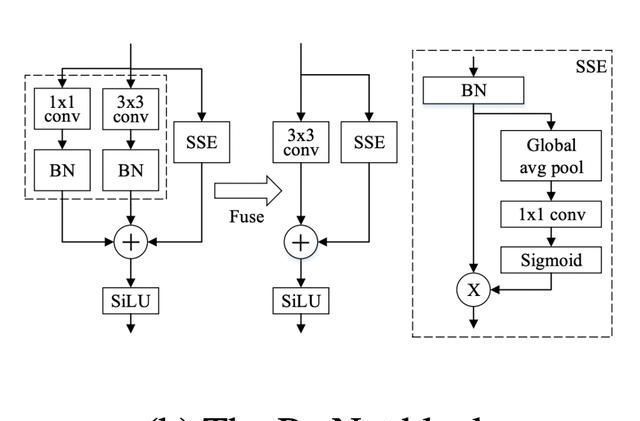
文章插图
除了RepVGG-SSE块的输入和输出具有相同的大小外,ParNet还包含下采样和融合块。模块降低分辨率并增加宽度以实现多尺度处理,而融合块组合来自多个分辨率的信息,有助于减少推理期间的延迟。为了在小深度下实现高性能,作者通过增加宽度、分辨率和流数量来扩展ParNet。作者表示,由于摩尔定律放缓,处理器频率提升空间也有限,因此并行计算有利于神经网络实现更快的推理。而并行结构的非深度网络ParNet在这方面具有优势。实际性能如何在ImageNet数据集上,无论是Top-1还是Top-5上,ParNet都接近SOTA性能。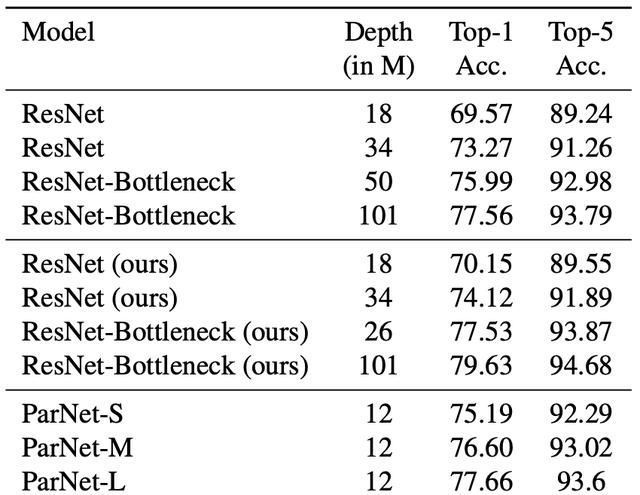
文章插图
在MS-COCO任务中,ParNet在性能最佳的同时,延迟最低。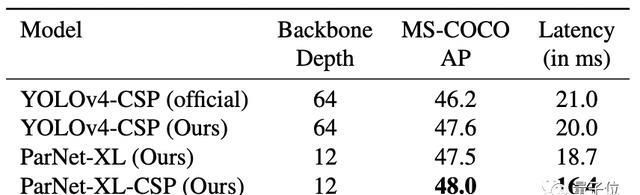
文章插图
不过也有人质疑“非深度网络”的实际表现,因为虽然层数少,但网络宽度变大,实际上ParNet比更深的ResNet50的参数还要多,似乎不太有说服力。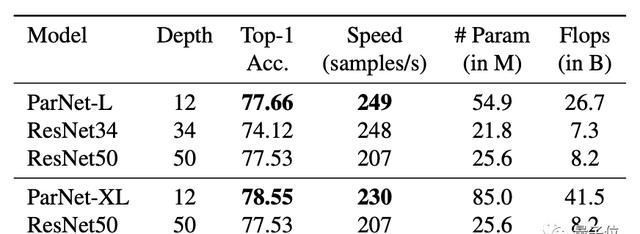
文章插图
但作者也表示“非深度”网络在多GPU下能发挥更大的并行计算优势。最后,ParNet的GitHub页已经建立,代码将在不久后开源。参考链接:[1]https://arxiv.org/abs/2110.07641[2]https://github.com/imankgoyal/NonDeepNetworks
- 苹果|库克压力确实大,在众多国产厂家对标下,iPhone13迎来“真香价”!
- 京东正式上线“年礼无忧”服务
- 央视公开“支持”倪光南?柳传志该醒悟了
- 小米 11 Ultra 内测 NFC“读写勿扰”与“解锁后使用”功能
- 造车|苹果造车一波三折,缺了一家“富士康”
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- iPhone|iphone14价格被曝!“胶囊”挖孔屏+三星4nm芯片,售价或5999起
- 36氪5G创新日报0112|福建省首个“5G+VR”英模会客厅正式上线;齐鲁医院健康管理中心“5G+ 5g
- 物联网|据说,物联网也可以称之为“一张想想的网络”,物联网世界是梦
- 微信上线“语音暂停”功能