Facebook|Facebook 宕机背后,我们该如何及时发现DNS问题

文章图片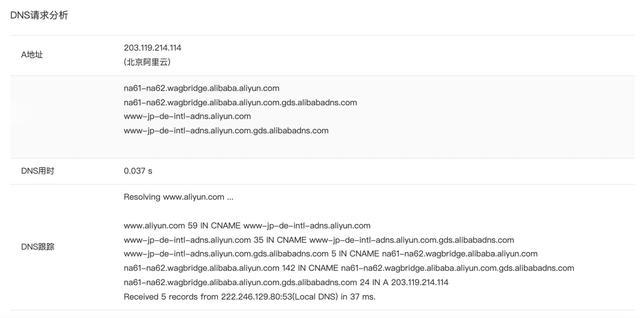
在我们享受国庆假期的时候 , 大洋对岸的互联网世界却出了一件重大“事故”:Facebook 及其旗下 Instagram 和 WhatsApp 等应用全网宕机 , 停机时间将近 7 小时 5 分钟 , 浏览器在尝试打开时显示 DNS 错误 。 这对于旗下应用群月活和日活高达 35.1 亿和 27.6 亿的 Facebook 而言 , 可谓损失惨重 。 据投资机构估计 , 7 小时宕机导致超过 9.68 亿美元影响成本 。 并直接让 Facebook 市值损失 643 亿美元 , 其创始人马克·扎克伯格净资产蒸发 70 亿美元 。
Facebook 表示 , 故障根本原因是例行维护工作出了问题 , 协调数据中心之间网络流量的骨干路由器配置变化 , 继而导致其 DNS 服务器发生问题并致使内部工具和系统被关闭 , 运维人员无法远程访问设备以便恢复网络 。 因此 , 运维人员不得不进入有着流程措施严格的数据中心进行人工重启 。 因此 , MTTR 被严重拖长 。
一句话总结 , 一条糟糕的命令、一款有缺陷的审核工具、一套阻碍成功恢复网络的 DNS 系统以及繁琐的数据中心流程 , 共同导致了 Facebook 长达 7 个小时的重大故障 。
具体而言 , 运维人员对骨干网络的一部分进行断网维护 。 例行维护的一部分就是评估全球骨干网容量的可用性 , 但无意间中断开了骨干网络所有连接 , 也断开了 Facebook 全球数据中心的连接 。 与此同时 ,由于 Facebook 的架构设计是根据服务器可用性来扩展或缩减 DNS 服务 。 当服务器可用性因网络故障而降至零时 , 就会停用所有 DNS 服务器 。 自动响应骨干网崩溃似乎成为导致 DNS 瘫痪的原因 。 这种停用通过 Facebook 的 DNS 名称服务器向互联网边界网关协议(BGP) 路由器发送消息来完成的 , 这些路由器存储用来抵达特定 IP 地址的路由方面的信息 。 这些路由通常被公告给路由器 , 让路由器了解如何适当地引导流量 。
Facebook 的 DNS 服务器发送的 BGP 消息禁用了公告给路由 , 因此无法将流量解析成 Facebook 骨干网络上的任何对应内容 。 最终结果就是 , 即使 DNS 服务器仍在运行 , 也访问不了 , 用户也会因试图访问的网络崩溃而丢失服务 。 更不幸的是 , DNS 服务用于面向客户的网站 , 还将其用于自己的内部工具和系统 。
看到这里我们会发现 , DNS 在这其中扮演着重要的角色 , 那么 DNS 又是什么?DNS 即Domain Name System 的缩写 , 域名系统以分布式数据库的形式将域名和IP地址相互映射 。 简单的说 , DNS 是用来解析域名的 , 在正常环境下 , 用户的每一个上网请求会通过 DNS 解析指向到与之相匹配的IP地址 , 从而完成一次上网行为 。 DNS 作为应用层协议 , 主要是为其他应用层协议工作的 , 包括不限于 HTTP 和 SMTP 以及 FTP , 用于将用户提供的主机名解析为 IP 地址 , 具体过程如下:(1)用户主机(PC 端或手机端)上运行着 DNS 的客户端;(2)浏览器将接收到的 URL 中抽取出域名字段 , 就是访问的主机名 , 比如http://www.aliyun.com/并将这个主机名传送给 DNS 应用的客户端;(3)DNS 客户机端向 DNS 服务器端发送一份查询报文 , 报文中包含着要访问的主机名字段(中间包括一些列缓存查询以及分布式 DNS 集群的工作);(4)该 DNS 客户机最终会收到一份回答报文 , 其中包含有该主机名对应的IP地址;(5)一旦该浏览器收到来自 DNS 的 IP 地址 , 就可以向该 IP 地址定位的 HTTP 服务器发起 TCP 连接 。
- 猪心移植人体成功的背后,站着一位华人女科学家
- 酷睿处理器|旗舰背后故事!1亿像素超清摄影+骁龙778G,你认为它适合什么人
- 不得不说新iMac在时尚感上的确是提升了不少|ipad简版imac花费不超300元,仅需背后的支架放下来
- meta|运用好Facebook组群可以带来哪些好处呢?
- F被指收集 4400 万用户数据,Facebook 母公司 Meta 面临 32 亿美元索赔
- 诺顿|天猫淘宝合并背后,京东唯品会也在行动,中国互联网风向变了
- |Facebook推广时可以使用哪些技巧?
- 今年最惨新股背后,一个芯片大佬的起伏人生
- 阿里巴巴|盒马融资传闻背后:阿里生态单元投资价值有望释放
- meta|Facebook广告投放时,你遇到过这些问题吗?