囚徒|郝建业:从囚徒困境到自动驾驶,蛰伏数十载的多智能体强化学习,期待破茧成蝶( 三 )
因此,在这项工作中,郝建业等人应用深度强化学习,探索了在复杂场景下,能抵抗对手剥削,同时又能适当合作的智能体策略。这其中的关键点,就在于推测对手心理。
他们提出了一个合作度检测网络,它相当于一个心理模型。给定对方的一系列动作,来预测对方的合作程度。该网络结合了LSTM和自编码器,可以保证对观察到的动作进行有效的特征提取,加快心理模型的训练速度,提高鲁棒性。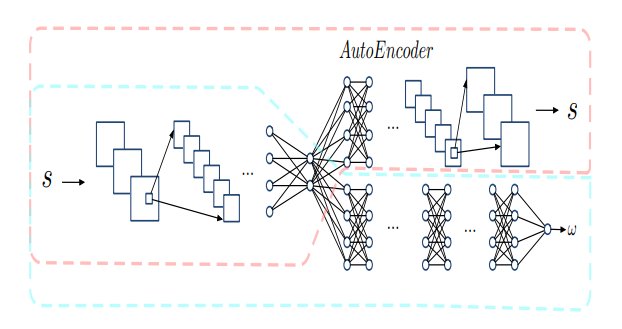
文章插图
比如在 Apple-Pear 游戏中,有一个红苹果和一个绿梨。蓝色智能体喜欢苹果,而红色智能体喜欢梨。每个智能体有四个动作:上、下、左、右,每走一步都会产生 0.01 的成本。当智能体走到水果对应方格时,就能收集到水果。
文章插图
当蓝色(红色)智能体单独收集一个苹果(梨)时,它会获得更高的奖励 1。当智能体收集到不喜欢的水果时,则只能获得更低的奖励 0.5。但是,当它们分享一个梨或一个苹果时,它们都会获得相应奖励的一半。
以合作度为度量,智能体可以产生更加多样化的决策。实验结果也不意外地显示,这两个智能体合作程度越高,总体奖励越高。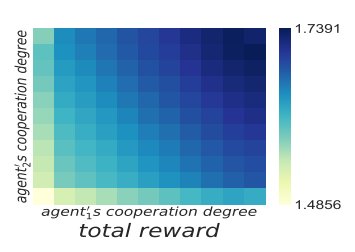
文章插图
郝建业将这种博弈场景称之为序列囚徒困境(SPD),它更加接近于现实世界中的博弈过程,即结合观察来随时调整策略。
训练方面,该方法包括两个阶段:离线和在线阶段。离线阶段生成不同合作度的策略并训练合作度检测网络。在线阶段则根据检测到的对手的合作程度,从连续的候选范围中自适应地选择具有适当合作程度的策略。
直观地说,该算法是面向合作的,并且对对手的自私、剥削行为也有防御能力。
文章插图
论文地址:http://ala2018.it.nuigalway.ie/papers/ALA_2018_paper_18.pdf
科研更像是在撒播种子,学者们依靠期望和想象去支撑意志力,从而坚持不懈地耕耘。这一过程存在太大的不确定性,但每次或隔一个月、或隔十年回到原野时,都期盼能看到令人出乎意料的景观。
郝建业坦言,“尽管最初只是非常简单的模型,但时间的力量以及外部环境的助推,可以令其茁壮成长,并最终在现实中变成让我们惊叹的样子。”
他没有仅仅满足于增加问题复杂度,而是进一步将目光聚焦到了更贴近现实的层面——研究自动驾驶场景的多智能体系统。
文章插图
SMARTS针对的是仿真平台的两个限制性问题,一个是环境单一,比如大部分仿真平台都只设置了晴天的天气;另一个则是缺少与其它智能体的互动场景,比如下图中的“双重合并”。
文章插图
可以说,多样的互动场景是SMARTS的一大特色。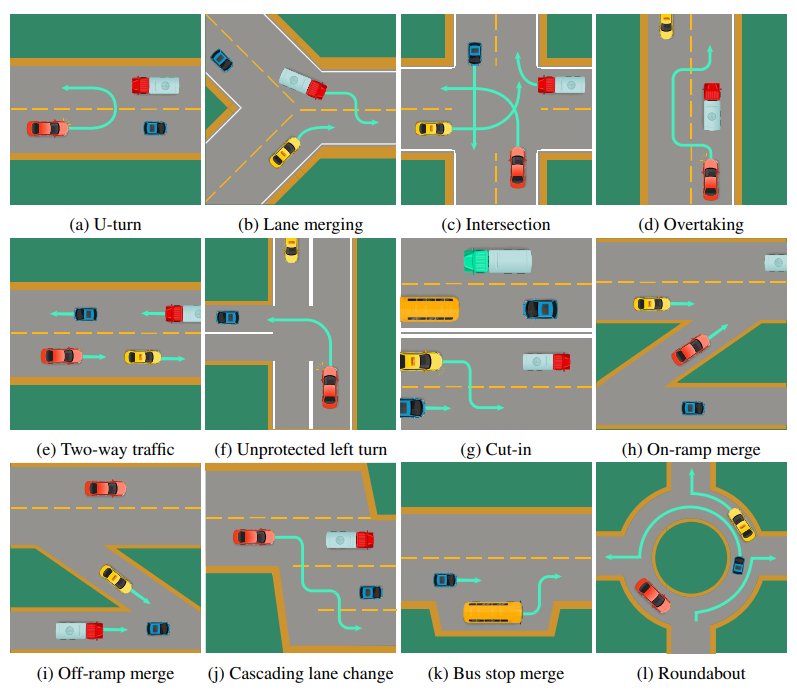
文章插图
SMARTS的相关论文“SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving”发表在机器人顶会之一CoRL 2020上,并斩获最佳系统论文奖。
- 30天卖货7500万,直播间多次上热搜,郝劭文凭什么那么牛?
- 泰山队球迷送出大蛋糕!预祝主教练郝伟预祝生日快乐!
- 郝吉虎调研滨州交通发展集团有限公司主城区道路工程项目
- 相机|郝一点和公司闹掰了?短视频账号更新,却被怀疑是假号
- 内卷|02 双11的囚徒困境
- 这项技术已经改变并将继续深刻改变我们的世界……——专访中国科学院院士郝跃|瞭望 | 瞭望
- 乾坤|郝俊杰升任代码乾坤技术合伙人,掌舵物理引擎夯实元宇宙底层
- 器件|全国教书育人楷模郝跃: 做好教书育人的一颗螺丝钉
- 国家工程研究中心|全国教书育人楷模郝跃: 做好教书育人的一颗螺丝钉
- 囚徒|斗鱼虎牙的钱途陌路