囚徒|郝建业:从囚徒困境到自动驾驶,蛰伏数十载的多智能体强化学习,期待破茧成蝶

文章插图
编辑 | 王晔
2019年郝建业的团队获得了第一届DAI最佳论文奖,距离他那篇研究多智能体系统中的“囚徒困境”论文的发表时间,已经整整过去了11年。
郝建业也没有想到,当初那篇只是基于简单博弈场景的研究成果,几乎被遗忘。如今通过结合深度强化学习,用于处理更复杂的场景,竟一下子成为了聚光灯下的宠儿,“仔细看DAI这篇文章里面的一些设计,其实都能在我以前的工作里找到原型。”
相对于以前的工作,这篇DAI 2019论文提出的模型,在参数空间上更加复杂,“尽管仍然是demo,但也是从理论走向实践的关键一步。”
在近期,AI科技评论与天津大学副教授、华为诺亚方舟实验室科学家郝建业进行了交流,谈了谈他从读博到科研工作期间的学术历程,试图理解他在十几年内,从简单的囚徒困境,跨越到复杂的囚徒困境,乃至自动驾驶等实际场景的研究和落地时,背后所付出的汗水,支撑他的信念,以及多智能体强化学习领域的时代剪影。
梁浩锋教授是香港中文大学计算机科学与工程学系教授和社会学系教授,研究领域包括多智能体系统、博弈论分析、本体(知识图谱)和大数据分析等。

文章插图
在郝建业的印象中,当时这两个方向的研究对象也还很简单,一般这些博弈问题都能以表格的形式表示。在深度强化学习概念还没有形成的那个时期,学者们研究的场景都是相当局限的,也就是基于表格的强化学习。
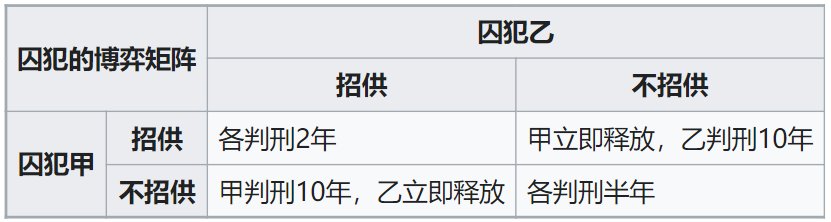
著名的囚徒困境就是一个典型的博弈场景,可以用下表来表示,在逼供场景下,囚徒有两个选择。
文章插图
在囚徒困境问题中,囚徒不仅困于监狱,亦困于仅有两个选择。但这些研究更多是在提出新的概念、范式、机制,偏向于理论,对于博弈论而言仍然具有很大的贡献。
而彼时更受欢迎的是不包括深度学习的模式识别,数据挖掘等方向,但在梁教授的引导下,郝建业还是慢慢喜欢上了这两个冷门方向。
比如博弈论是多智能体系统中最关键的一套数学工具,为此,梁教授甚至专门为他开设了个人课堂。
看论文也是一门必修课,郝建业看遍了AAMAS近一两年的几乎所有相关论文,“泛读的至少几百篇,精读的也有几十篇。”按照当年打印论文的习惯,这些论文大概得有半米的高度。AAMAS是多智能体领域最有影响力的会议,亦属于机器人领域顶会。
坚持啃论文差不多一年时间以后,郝建业才初步对多智能体方向建立了系统的认知,以及了解自己到底对哪个topic感兴趣。
“兴趣应该是做的过程中慢慢培养起来的。当你对某样东西一无所知的时候,也很难引发兴趣,而只是知道一个名词而已。比如现在很多学生说对人工智能感兴趣,但是你问对方‘什么是人工智能’,对方经常都答不上来,这种其实不是真正的兴趣,只是一时好奇。”在与梁教授的接触中,郝建业才慢慢领悟到这个道理。
- 30天卖货7500万,直播间多次上热搜,郝劭文凭什么那么牛?
- 泰山队球迷送出大蛋糕!预祝主教练郝伟预祝生日快乐!
- 郝吉虎调研滨州交通发展集团有限公司主城区道路工程项目
- 相机|郝一点和公司闹掰了?短视频账号更新,却被怀疑是假号
- 内卷|02 双11的囚徒困境
- 这项技术已经改变并将继续深刻改变我们的世界……——专访中国科学院院士郝跃|瞭望 | 瞭望
- 乾坤|郝俊杰升任代码乾坤技术合伙人,掌舵物理引擎夯实元宇宙底层
- 器件|全国教书育人楷模郝跃: 做好教书育人的一颗螺丝钉
- 国家工程研究中心|全国教书育人楷模郝跃: 做好教书育人的一颗螺丝钉
- 囚徒|斗鱼虎牙的钱途陌路