|【全面】pandas数据分析面试题(二)汇总!
文章图片
文章图片

文章图片
文章图片
文章图片
文章图片

哈喽 , 大家好 , 今天继续为大家带来pandas数据分析面试题 。
我们接下来的操作依旧是以如下数据作为案例:
dic={
\"name\":['python''pandas''numpy''Matplotlib''python''html'
\"price\":[405060704551
\"adress\":['北京''上海''广州''深圳'
'杭州''湖州'
df=pd.DataFrame(dic)
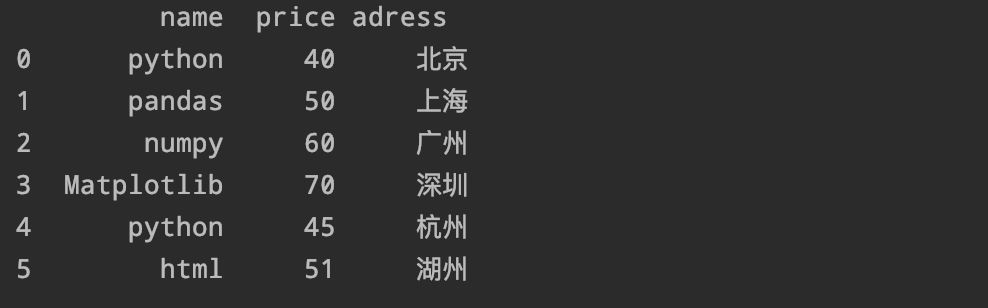
1、删除最后一行数据:
df.drop([5
axis=0)
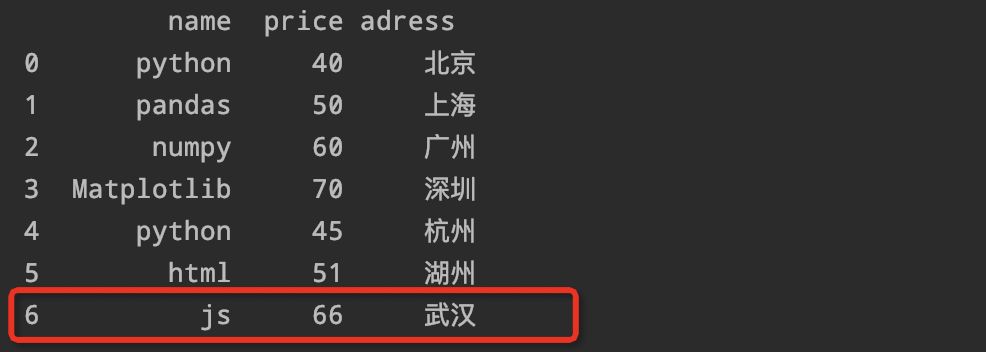
2、如何添加一行数据:
row={'name':'js''price':66'adress':'武汉'
df=df.append(rowignore_index=True)
3、对数据按照price这列进行排序:
df.sort_values(\"price\")
4、通过pandas读取Excel数据
df=pd.read_excel('pandas面试题.xlsx')
5、将数据按照name进行分组 , 并计算出平均的价格:
df.groupby(\"name\").mean()
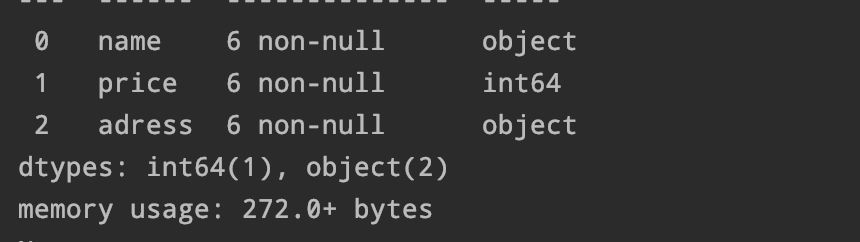
6、查看索引、数据类型和内存信息
df.info()
7、查看数值型列的汇总统计
df.describe()
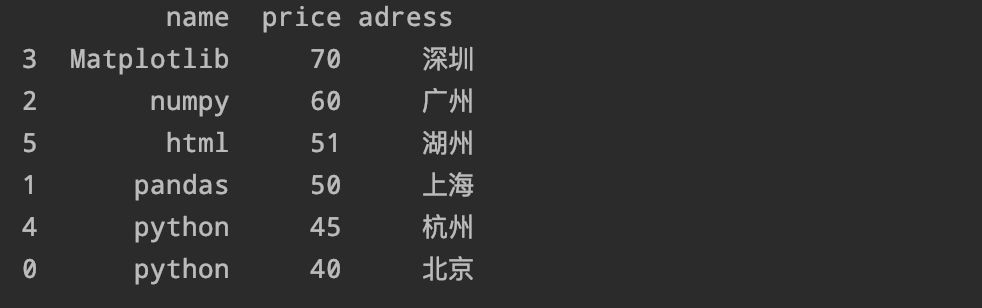
8、按照价格列对数据降序排列
df.sort_values('price'ascending=False)
9、将数据第二列提取出来:
df.loc[2
10、计算价格列的中位数:
df[\"price\"
.median()
11、根据价格列绘制直方图:
df.price.plot(kind='hist')
12、删除最后一列
del df['adress'
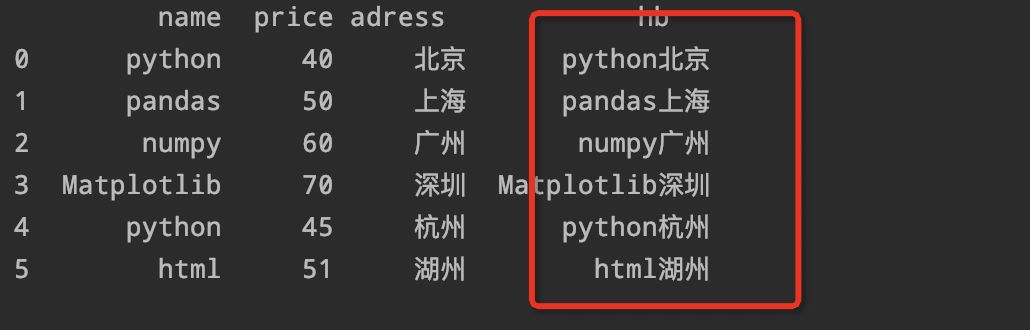
13、将第一列和最后一列合并后生成新的列:
df['hb'
=df[\"name\"
+df[\"adress\"
14、将第一行与最后一行拼接
pd.concat([df[:1
df[-2:-1
)
15、将第二行数据添加到末尾:
df.append(df.loc[2
)
【|【全面】pandas数据分析面试题(二)汇总!】好了 , 今天的内容就先到这里了 , 明天见!
- 本文转自:新民网上海集成电路“大师讲堂”系列活动8月12日启动|上半年集成电路产业增速超17%!上海已集聚超过1200家行业重点企业
- c语言|“取消外卖,关闭电商,恢复人间烟火气,恢复市面繁荣”,网友:开玩笑呢
- 折叠屏|折叠屏也玩起了性价比?直板手机价格更有吸引力
- 1.0MPA橡胶接头
- 【专利】FCC赢得交通运输协会诉讼;
- 相互宝|再也没有了!马云退位后,支付宝又一功能宣布永久关闭
- 摩托罗拉|摩托罗拉X30Pro与红米K50至尊版全面对比:优缺点一目了然
- 【科创之声】芯片法案拦不住“中国芯”
- 本文转自:长江日报统筹|陈智 设计|马伊霖 实习生|王亚昆【编辑:汪宇瑾】更多精彩内容|1年前的今天,长航货运有限公司建造的我国内河首艘绿色智
- 小米 MIX Fold 2 和 MIX Fold 有什么区别?该怎么选?