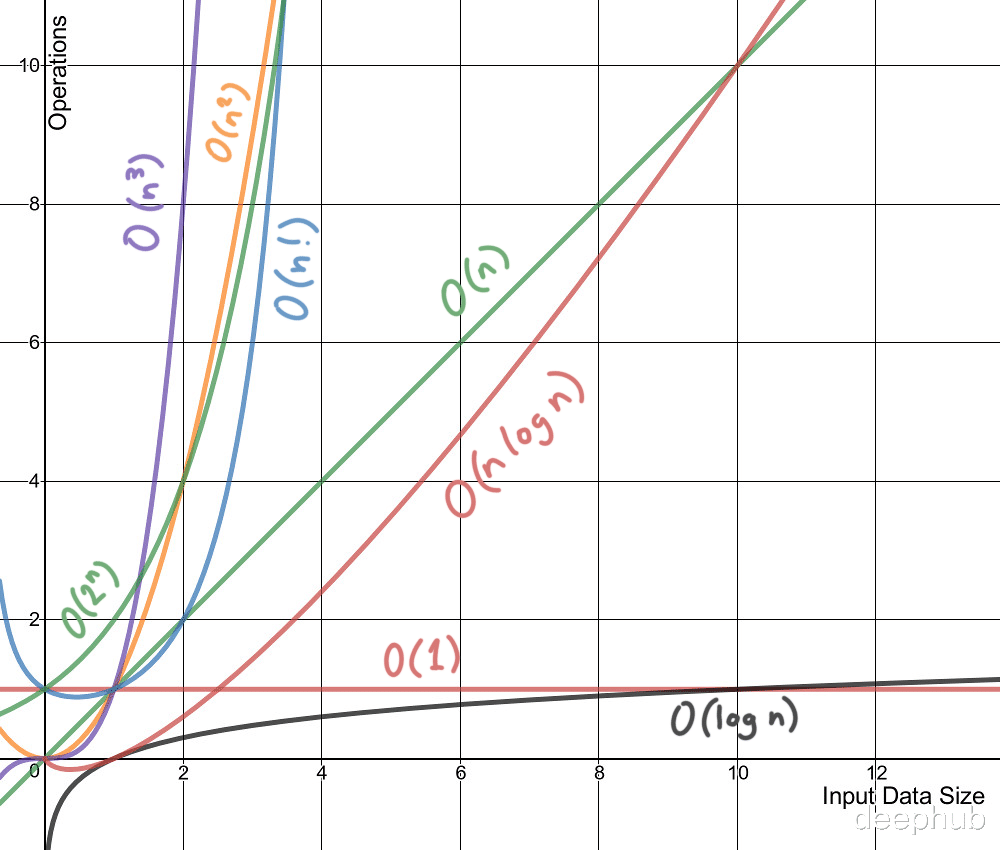
计算的复杂度是一个特定算法在运行时所消耗的计算资源(时间和空间)的度量 。
计算复杂度又分为两类:
1、时间复杂度
时间复杂度不是测量一个算法或一段代码在某个机器或者条件下运行所花费的时间 。 时间复杂度一般指时间复杂性 , 时间复杂度是一个函数 , 它定性描述该算法的运行时间 , 允许我们在不运行它们的情况下比较不同的算法 。 例如 , 带有O(n)的算法总是比O(n2)表现得更好 , 因为它的增长率小于O(n2) 。
2、空间复杂度
就像时间复杂度是一个函数一样 , 空间复杂度也是如此 。从概念上讲 , 它与时间复杂度相同 , 只需将时间替换为空间即可 。维基百科将空间复杂度定义为:
算法或计算机程序的空间复杂度是解决计算问题实例所需的存储空间量 , 以特征数量作为输入的函数 。
下面我们整理了一些常见的机器学习算法的计算复杂度 。
1、线性回归
【算法|8个常见的机器学习算法的计算复杂度总结】n= 训练样本数 , f = 特征数
训练时间复杂度:O(f2n+f3)
预测时间复杂度:O(f)
运行时空间复杂度:O(f)
2、逻辑回归:
n= 训练样本数 , f = 特征数
训练时间复杂度:O(f*n)
预测时间复杂度:O(f)
运行时空间复杂度:O(f)
3、支持向量机:
n= 训练样本数 , f = 特征数 , s= 支持向量的数量
训练时间复杂度:O(n2) 到 O(n3) , 训练时间复杂度因内核不同而不同 。
预测时间复杂度:O(f) 到 O(s*f):线性核是 O(f) , RBF 和多项式是 O(s*f)
运行时空间复杂度:O(s)
4、朴素贝叶斯:
n= 训练样本数 , f = 特征数 , c = 分类的类别数
训练时间复杂度:O(n*f*c)
预测时间复杂度:O(c*f)
运行时空间复杂度:O(c*f)
5、决策树:
n= 训练样本数 , f = 特征数 , d = 树的深度 , p = 节点数
训练时间复杂度:O(n*log(n)*f)
预测时间复杂度:O(d)
运行时空间复杂度:O(p)
6、随机森林:
n= 训练样本数 , f = 特征数 , k = 树的数量 , p=树中的节点数 , d = 树的深度
训练时间复杂度:O(n*log(n)*f*k)
预测时间复杂度:O(d*k)
运行时空间复杂度:O(p*k)
7、K近邻:
n= 训练样本数 , f = 特征数 , k= 近邻数
Brute:
训练时间复杂度:O(1)
预测时间复杂度:O(n*f+k*f)
运行时空间复杂度:O(n*f)
kd-tree:
训练时间复杂度:O(f*n*log(n))
预测时间复杂度:O(k*log(n))
运行时空间复杂度:O(n*f)
8、K-means 聚类:
n= 训练样本数 , f = 特征数 , k= 簇数 , i = 迭代次数
训练时间复杂度:O(n*f*k*i)
运行时空间复杂度:O(n*f+k*f)
作者:Rafay Qayyum
- 算法|抓鱼猫APP:在线兼职都有哪些比较好的项目?
- 算法|我们只是活在各自的世界里,而不是活在这个世界上……
- 以下哪种夏季常见水果属于感光食物,吃多了要小心晒太阳 答答星球8月3日每日一答答案
- 算法|每天睡4小时搜狐不及阿里零头?可别再嘲讽张朝阳了,人潇洒着呢
- 本文转自:科技日报图片来源:俄罗斯卫星通讯社俄罗斯创新城大学开发出一种用机器学习算法预测...|机器学习算法能预测癫痫发作|创新连线·俄罗斯
- 本文转自:科技日报科技日报记者?张梦然英国牛津大学材料系研究人员联合埃克塞特大学和明斯特...|总编辑圈点|AI模拟条件反射进行联想学习,比传统机器
- 小米科技|Facebook Marketplace 上的 8 种常见骗局
- 算法|硅谷初创公司Kift:召唤更多人住进车里,组建流动社区
- 算法|云业务增长,个人电脑市场在“恶化”!微软通过6月份报告指出
- bilibili|算法永远无法复制“二舅”