训练|迷你版DALL-E:模型缩小27倍,训练成本仅200美元,在线可玩!( 二 )
文章插图
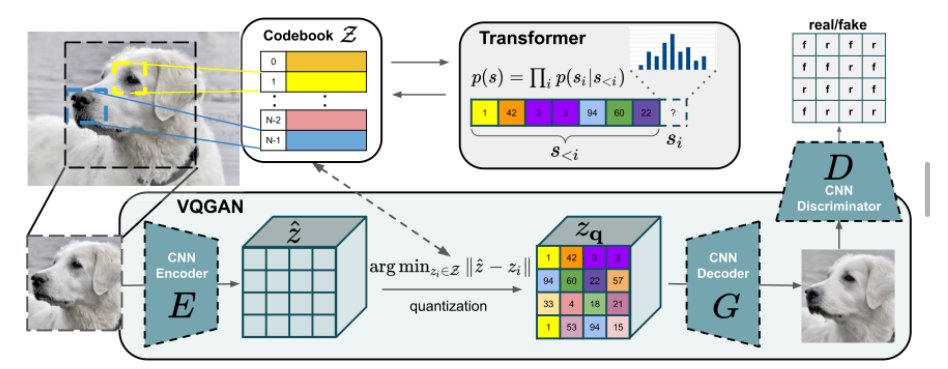
2.Dall·E mini使用大量预先训练好的模型(VQGAN、BART编码器和CLIP),而OpenAI从头开始训练。
3.在图像编码方面,表( vocabulary )的对比是8192 vs 16384,tokens的对比是1024vs256。Dall·E使用VQVAE,而作者使用VQGAN。
4.在文本编码方面,表( vocabulary )的对比是16384 vs 50264,tokens的对比是256 vs 1024。
5.Dall·E通过自回归模型读取文本,而Dall·E mini使用双向编码器。
6.Dall·E接受了2.5亿对图像和文本的训练,而Dall·E mini只使用了1500万对。
文章插图
- iphone13 pro|粉丝买美版iPhone13Pro,躲过了网络锁,却没想到有配置锁!
- 华为|iOS15.2.1 正式版发布:新增 6 项改进
- 三星|三星Galaxy S22参数曝光:仍有Exynos 2200处理器版本
- iOS|苹果推送iOS15.2.1正式版修复漏洞为主 用户是否要更新看体验再说
- 军工|中国版“英伟达”诞生,核心技术完全自研,国产替代即将崛起
- Minisforum 发布 UM350 迷你 PC:搭载 R5 3550H 处理器
- 今日|《战神4》pc版正式解锁dlss和fsr性能表现
- 作为知名的迷你PC厂商|魔方推出全新amd迷你pc
- 不得不说新iMac在时尚感上的确是提升了不少|ipad简版imac花费不超300元,仅需背后的支架放下来
- 联想|百度地图、高德地图、腾讯地图的手机版,哪个导航最靠谱?