文章图片
作为开发人员 , 了解 JVM 的架构非常重要 , 因为它使我们能够更有效地编写代码 。
什么是 JVM?
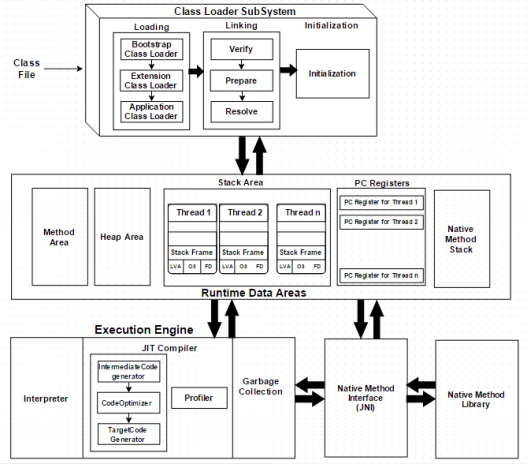
虚拟机是物理机的软件实现 。 Java 是根据 WORA(一次编写 , 随处运行)的概念开发的 , 它在 VM 上运行 。 编译器将 Java 文件编译为 Java .class 文件 , 然后将该 .class 文件输入到 JVM 中 , JVM 加载并执行该类文件 。 下面是JVM的架构图 。
JVM 是如何工作的?
如上架构图所示 , JVM主要分为三个子系统:类加载器子系统、运行时数据区、执行引擎 。
1. 类加载器子系统
Java 的动态类加载功能由类加载器子系统处理 。 它加载 , 链接 , 并在运行时而不是编译时第一次引用类时初始化类文件 。
1)加载
类将由该组件加载 。 BootStrap ClassLoader、Extension ClassLoader 和 Application ClassLoader 是三个有助于实现它的类加载器 。
l BootStrap ClassLoader – 负责从引导类路径加载类 , 除了 rt.jar 。 此加载程序将获得最高优先级 。
l Extension ClassLoader – 负责加载 ext 文件夹 (jre\\lib) 中的类 。
l Application ClassLoader——负责加载Application Level Classpath、路径提到的环境变量等 。
上述类加载器在加载类文件时将遵循委托层次算法 。
2)链接
l 验证 - 字节码验证器将验证生成的字节码是否正确 , 如果验证失败 , 我们将收到验证错误 。
【一加科技|Java:JVM架构解释】l 准备 - 对于所有静态变量 , 内存将被分配并分配默认值 。
3)初始化
这是类加载的最后阶段 , 在这里 , 所有静态变量都将被赋予原始值 , 并且将执行静态块 。
2. 运行时数据区
运行时数据区分为五个主要部分:
1)方法区——所有类级别的数据都将存储在这里 , 包括静态变量 。 每个JVM只有一个方法区 , 它是一个共享资源 。 Java培训班的课程都是系统全面的整体 , 无论个人基础的好坏 , 都能真正做到从0开始 , 循序渐进的过渡到实际项目演练 , 在实际项目中验证所学知识的掌握程度 , 这是个人自学难以企及的巨大优势 。
2)堆区——所有对象及其对应的实例变量和数组都将存储在这里 , 每个 JVM 也有一个堆区 。 Method 和 Heap 区域为多个线程共享内存 。
3)堆栈区——对于每个线程 , 将创建一个单独的运行时堆栈 。 对于每个方法调用 , 都会在堆栈内存中创建一个条目 , 称为堆栈帧 。 所有局部变量都将在堆栈内存中创建 。 堆栈区域是线程安全的 , 因为它不是共享资源 。 Stack Frame 分为三个子实体:
l 局部变量数组 - 与方法相关 , 涉及多少局部变量以及相应的值将存储在这里 。
l 操作数栈——如果需要执行任何中间操作 , 操作数栈充当运行时工作区来执行操作 。
l 帧数据——与方法对应的所有符号都存储在这里 。 在任何异常的情况下 , catch 块信息将保存在帧数据中 。
4)PC 寄存器——每个线程都有单独的 PC 寄存器 , 用于保存当前执行指令的地址 , 一旦指令执行 , PC 寄存器将被下一条指令更新 。
5)本机方法堆栈——本机方法堆栈保存本机方法信息 。 对于每个线程 , 将创建一个单独的本机方法堆栈 。
3.执行引擎
分配给运行时数据区的字节码将由执行引擎执行 , 执行引擎读取字节码并逐段执行 。
1)解释器——解释器更快地解释字节码 , 但执行速度很慢 。 解释器的缺点是当一个方法被多次调用时 , 每次都需要新的解释 。
- 伊隆·马斯克|弘辽科技:拼多多新店dsr分多久出?如何提高?
- 小米科技|年轻人的第一个金首饰!2500元的小米手环你见过吗?
- 一加科技|品牌不好的手机,真的不值得购买吗?本质上看问题
- 小米科技|起价4699元,小米12SPro值得买吗?看完用户评价就知道了
- 本文转自:科技日报插图显示了一种包含氮化硼片(蓝色和银色球晶格)和二氧化钛纳米颗粒(灰色...|新复合光催化剂分解“永久化学污染物”
- 一加科技|OPPO Find X6和一加11均遭曝光:芯片和方向基本清晰了
- |降价后的一加10Pro,是否值得购买?
- 一加科技|8GB+64MP+66W,旗舰机外观+120Hz全视屏,仅售1199
- 一加科技|下半年大牌旗舰新机大爆发,国内外品牌4款机型哪一台最受期待?
- Google|美科技巨头的日子不好过