算法|99.99%准确率!AI数据训练工具No.1来自中国
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
这年头,真是什么样的数据集都有了。
IBM的5亿行代码(bug)数据集、清华&阿里的460万少样本NER数据集、还有假货数据集、“黑话”数据集、小黄图数据集……咳咳。
没错,相比遭遇瓶颈的算法,数据现在成了AI行业的“香饽饽”——
他们发现,当年一个ImageNet走天下,微调AI模型参数就能取得SOTA的时代已经过去。
来自谷歌AI的最新研究表明,要想在细分领域取得更好的模型效果,精准优质的数据十分重要,它在极大程度上决定了AI模型的性能。
文章插图
例如,谷歌曾经做过一款流感趋势预测模型,但由于数据质量太差,预测结果甚至偏离了流感峰值的140%。
连斯坦福大学副教授、Coursera联合创始人吴恩达,也强调数据质量对于AI的重要性:
80%的数据+20%的模型=更好的AI。
真正“有用”的AI模型,离不开数据
一直以来,数据质量对于AI模型的影响程度都在被低估。
【 算法|99.99%准确率!AI数据训练工具No.1来自中国】随着大模型如BERT、Alphafold2、GPT-3、DALL·E逐渐成为人工智能产业的潮流,更多的数据也在被“投喂”进各种AI模型中。
数据质量的问题,也因此更加突出。
来自谷歌、苹果、斯坦福、哈佛等七家顶级机构的一项研究表明,越大的语言模型,隐私泄露风险就越高。
他们用OpenAI的GPT-3模型做了实验,发现只需要一串“暗号”,就能让它报出某个人的姓名、电话、住址等隐私信息。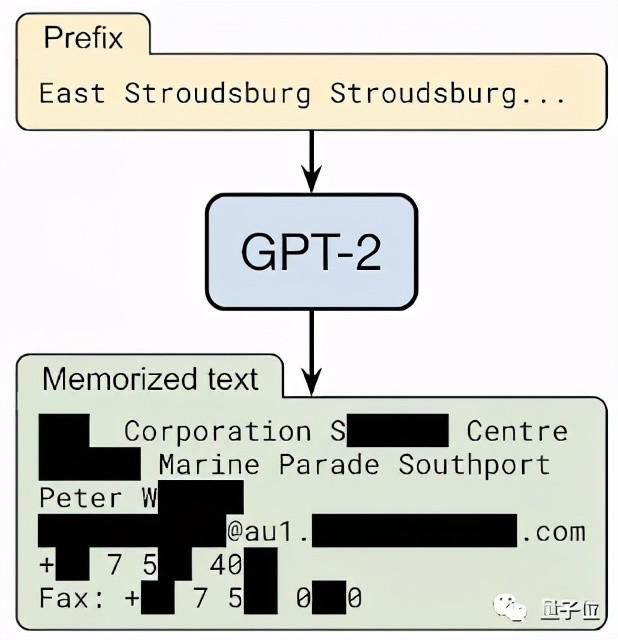
文章插图
由于AI模型不能完全“消化”数据,只会把训练数据中的一部分原样展示出来,导致模型越大,对数据的记忆能力就越强,泄露隐私、输出虚假信息片段的可能性就越高。
不少大型AI公司,已经开始从根本上解决数据质量问题。
谷歌就已经开始研发数据处理算法,其中的TEKGEN模型,能将数据质量靠谱的知识图谱转换成文本数据库,再用于AI模型的训练。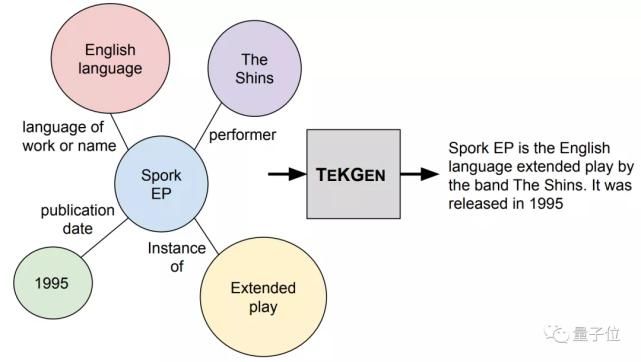
文章插图
而IBM、清华大学、阿里达摩院等国内外研究机构,也开始建立类似代码bug、假货、少样本NER一样的细分领域数据集。
但这些做法都需要足够的人力和精力,相比之下,外包/众包可能是更多AI企业的选择。然而在这种情况下,又可能获得不合要求、甚至良莠不齐的数据,质量难以保障。
现在,AI训练数据处理行业中迸现出一匹黑马——
一家对AI算法落地有所研究的AI训练数据服务商,自主研发了一个名为「云测数据标注平台4.0」的数据处理平台,直接将数据标注的最高准确率提升到了99.99%。
据云测数据表示,这一平台使得企业服务成本平均降低了60%以上,至于研发AI项目的效率,则提升了2倍不止。
这样的标注效率,并非有口无据。在4.0正式版上线前,「云测数据标注平台」一直是云测数据内部自用的AI训练数据处理平台。
正是凭借着这一平台,结合其高精准数据标注能力和场景化训练数据方案等实力,云测数据连续两年在数据标注公司排行榜上夺得TOP 1的位置。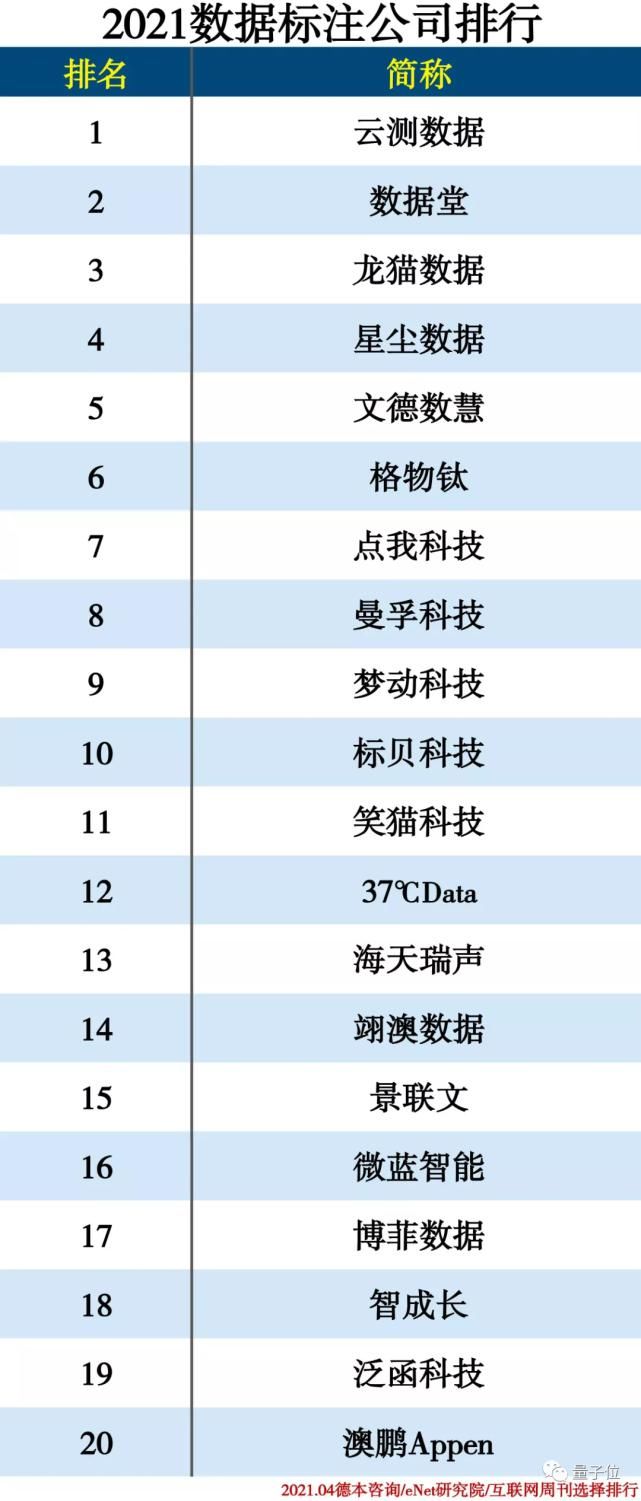
文章插图
他们的平台,凭什么拿下行业TOP 1?
凭的是三大技术特点:稳、全、快。
首先,对于目前成熟的标注场景,保证AI辅助标注稳定不出错。
对于智能数据标注技术来说,目前比较成熟的场景包括OCR(光学字符识别)、语音切割等任务。
以OCR为例,识别准确率是基本要求,更重要的是文字识别的效率:
- 合规|上海制定反垄断、互联网营销算法、盲盒经营活动等新业态合规指引
- c语言|e观沧海丨算法焉能藏“算计”
- 算法|【2022/1/15】thinkphp源码无差别阅读(二十)
- 算法|电竞好用日常也爽的小金刚显示器,优派VX2780-2K-PRO分享
- 算法|用户来得太难,走得太容易,怎么办?
- 华人女博士提出高效NAS算法:AutoML一次「训练」适配亿万硬件
- 算法|数据结构学习笔记之线性表(02)
- 王国彬|北京海淀:一审宣判全国首例涉人工刷量平台干扰搜索引擎算法不正当竞争纠纷案
- 展示|人脸识别准确率达93% 三星展示首款基于MRAM 的内存计算
- 百度|全国首例!百度起诉我爱网获赔200万:人工刷量干扰搜索引擎算法