分词器|当你按下搜索键时,发生了什么?(上)( 三 )
现有的分词包括有英文分词、中文分词、拼音分词。中文分词与英文分词有所区别,中文分词存在更多的难点和歧义点,不同分词策略对文档的召回率和精确率影响较大。
英文单词与单词之间,在输入时就会通过空格、逗号、句号去隔开,较好的去识别。而中文由字和字构成词,由词汇构成句子。如何去合理切分,且可以精确传达用户本意、需求,是中文分词的难点。拼音分词与中文分词的结合,更全面地处理了用户简写、误输入等使用场景。
拼音分词可以用来分析字词的全拼、首字母全拼、字词的完整拼写等,可以进行自定义的设置。拼音分词配合中文分词,完整关键词的过滤流程,达到高效分词的目的。
中文分词算法主要分为三大类,基于词典的分词、基于统计的分词、基于有序标注的分词。
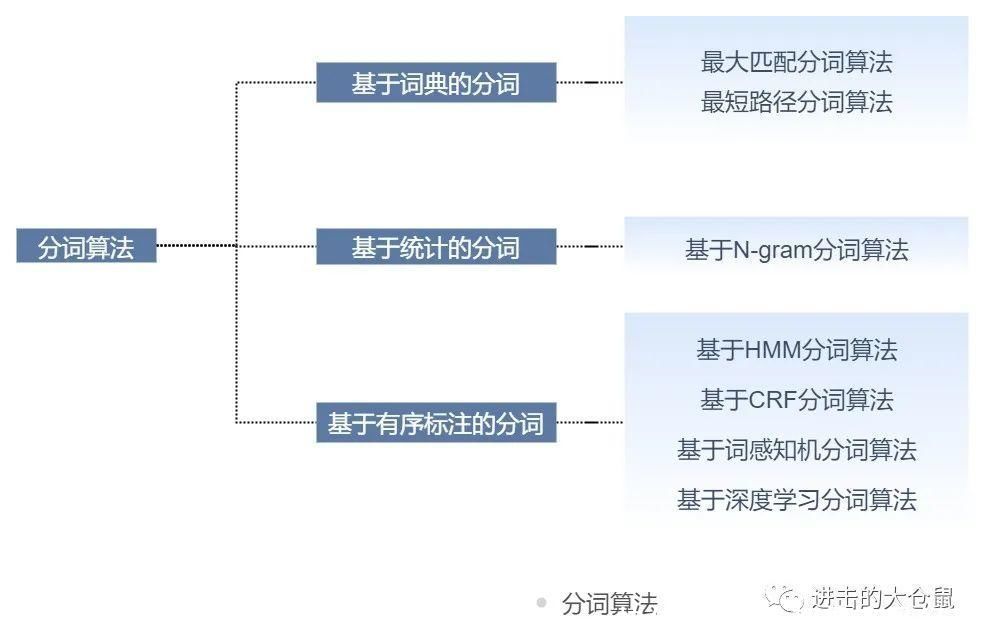
文章插图
不同的分词策略要适应于各自的业务场景,可能有些业务场景需要分词的精度大于速度,有些场景要求速度大于精度,因此在理解分词原理的基础上,如何去配合业务的需求,高效地实现分词功能,这些都给算法工程师提出了更高的要求。
2.1.3 分词的使用
在搜索过程中,分词器使用于文档的索引流程以及用户输入文本的检索流程中,需注意的是索引流程和检索流程中所使用的分词器需一致。
- 索引使用:原始文本预处理后,使用分词器将文档内容切分为单个字词;
- 检索使用:用户输入文本对象,分词器进行分词处理,分词后建立query对象,执行检索操作。

文章插图
中文分词相较于英文分词,无空格作为词之间的分隔符,且中文词语组合复杂,歧义较多,一直为自然语言处理中的难点。
2.2 构建索引索引是对数据库表中一列或多列的值进行排序的一种辅助型数据结构,构建索引有助于对表中数据的查找和排序,检索时数据库系统不必扫描整个表,而是直接定位到符合条件的记录,大大加快了查询速度,达到了以下目的:
构建索引大大缩短查询时间的同时,也带了了一定的成本,创建和维护索引都需要时间成本和空间成本,随着数据量的增加其所占用的物理存储空间也会随之增大。数据量大、经常使用查询功能,且需要排序优化的业务情境下,索引的建立还是很有必要的。
索引的构建,主要有倒排序索引和正排序索引。倒排序索引是对关键词进行索引,以求快速得到匹配文档集;正排序索引对文档进行索引,方便于排序、过滤、汇总。倒排序索引和正排序索引是搜索引擎的重要数据结构,之后检索等的操作都建立在此基础上。
2.2.1 倒排序索引
1)倒排序索引介绍
倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
索引是为了更快找到文档的一种数据结构,相当于图书中的目录,用户根据目录可以快速找到所需内容。倒排索引不是根据目录或编号来定位内容,它是通过文档中的某个字、词语而找到文档的索引类型,通过立即的单词标示迅速获取结果。倒排索引的建立和维护较复杂,但查询快速、便捷、高效,是文档检索系统中最常用的数据结构。
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- MacBook Pro|光伏电池充电器/带MPPC的太阳能电池锂离子电池滴流充电器LTC3105
- gtx1060|GTX1060上古神器?
- 显示器|微信新功能开始!长语音可以暂停
- iPhoneSE|都是情怀!iPhone SE3外观毫无改变:A15处理器、支持5G
- CPU|E5系列处理器——工作室和生产力专业处理器,小白请勿购买
- 三星|三星Galaxy S22参数曝光:仍有Exynos 2200处理器版本
- DeepMind首席科学家:比起机器智能,我更担心人类智能造成的灾难
- 传感器|称年轻,我们怎么做到经济自由?
- 显示器|年货节联合回馈,华硕显示器与雷孜推出超值创艺套装!