文章图片

Python 3.11 pre-release已经发布 。更新日志中提到:
Python 3.11 is up to 10–60% faster than Python 3.10. On average we measured a 1.25x speedup on the standard benchmark suite. See Faster CPython for details. — Python 3.11 Changelog.
Python 在生产系统上的速度一直是被新手对比和吐槽 。, 因为真的并不块 , 为了解决性能问题 , 我们总是需要使用 Cython 或 Tuplex 转换关键代码 。
Python 3.11中特意强了这个优化 , 我们可以实际验证下到底有没有官方说的平均1.25倍的提升呢?
作为数据科学来说 , 我更期待的是看看它在 Pandas 处理DF方面是否有任何改进 。
首先 , 让我们尝试一些斐波那契数列 。
安装Python 3.11 pre-releasewindows的话可以在官方下载安装文件 , ubuntu可以用apt命令进行安装
sudo apt install Python3.11
我们在工作中还不能直接使用3.11 。所以需要创建单独的虚拟环境来保存两个 Python 版本 。
$ virtualenv env10 --python=3.10
$ virtualenv env11 --python=3.11
# To activate v11 you can run
$ source env11/bin/activate
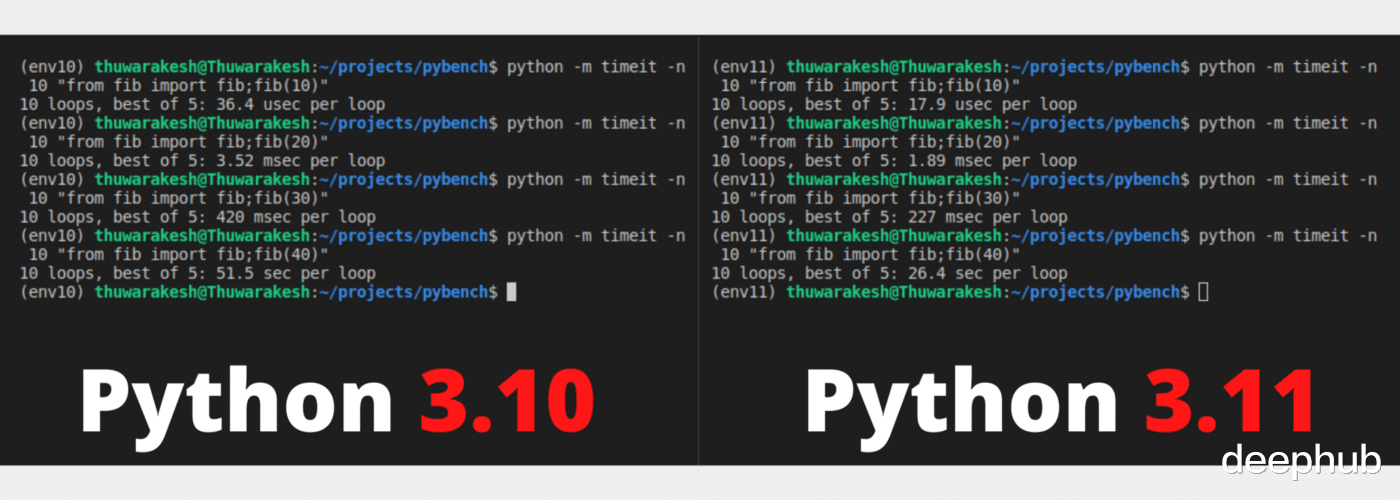
Python 3.11 与 Python 3.10 相比有多快?【Python|Python 3.11比3.10 快60%:使用冒泡排序和递归函数对比测试】我创建了一个小函数来生成一些斐波那契数 。
def fib(n: int) -> int:
return n if n < 2 else fib(n - 1) + fib(n - 2)
用 Timeit 运行上面的斐波那契数生成器来确定执行时间 。以下命令将重复生成过程十次并显示最佳执行时间 。
# To generate the (n)th Fibonacci number
python -m timeit -n 10 \"from fib import fib;fib(n)\"
以下是 Python 3.10 和 Python 3.11 上的结果
Python 3.11 在每次运行中都优于 Python 3.10 。执行时间大约是 3.11 版本的一半 。
我其实是想确认它在 Pandas 任务上的表现 。但不幸的是 , 到目前为止Numpy 和 Pandas 还没有支持 Python 3.11 的版本 。
冒泡排序由于无法对 Pandas 进行基准测试 , 因此我们试试一般常见的计算时的性能对比 , 测量对一百万个数字进行排序所花费的时间 。 排序是日常使用的最多也是最常用的一个操作了 , 相信它的结果可以为我们提供一个很好的参考 。
import random
from timeit import timeit
from typing import List
def bubble_sort(items: List[int
) -> List[int
:
n = len(items)
for i in range(n - 1):
for j in range(0 n - i - 1):
if items[j
> items[j + 1
:
items[j
items[j + 1
= items[j + 1
items[j
numbers = [random.randint(1 10000) for i in range(1000000)
print(timeit(lambda:bubble_sort(numbers)number=5))
上面的代码生成了一百万个随机数 。timeit 函数被设置为仅测量冒泡排序函数执行的持续时间 。
结果如下
Python 3.11 只用了 21 秒来排序 , 而 3.10 对应的用时 39 秒 。
I/O 操作是否存在性能差异?这两个版本在磁盘上读写信息的速度有差异吗 。 在pandas读取df还有深度学习读取数据时 I/O 性能至关重要 。
这里准备了2个程序 第一个将一百万个文件写入磁盘 。
from timeit import timeit
statement = \"\"\"
for i in range(100000):
with open(f\"./data/a{i.txt\" \"w\") as f:
f.write('a')
\"\"\"
print(timeit(statement number=10))
- 5月18日消息|AirPods卖爆了!真无线耳机出货量暴增:苹果占比达32%
- 丘比特是罗马神话和希腊神话中的小爱神|你的520约会好帮手——华为小艺建议
- 5月18日上午|腾讯用16K拍摄裸眼3D高精度文物模型:纤毫毕现 比真的还“
- |为啥都宁选荣耀手机,也绝不考虑高性价比的红米,三个原因很现实
- 摩托罗拉|摩托罗拉对国人很好,12GB+512GB比友商便宜2000,销量逆袭了
- Python|安卓微信8.0.23内测更新:回归聊天社交,并受到马斯克称赞!
- 大屏|百元性价比:高清三摄+6.26英寸大屏,8+128G仅669元,售价更亲民
- 英特尔|双通道32GB内存仅600元?挑战本世代性价比之王,真香体验!
- 显卡|老主板焕发新生!高性价比3A配置推
- 腾讯|腾讯用16K拍摄裸眼3D高精度文物模型:纤毫毕现 比真的还“真”