
文章图片

文章图片
文章图片

文章图片
文章图片
使用 Pandas 的between 、cut、qcut 和 value_count离散化数值变量
分箱是一种常见的数据预处理技术有时也被称为分桶或离散化 , 他可用于将连续数据的间隔分组到“箱”或“桶”中 。在本文中 , 我们将讨论使用 python Pandas 库对数值进行分箱的 4 种方法 。
我们创建以下合成数据用于演示
import pandas as pd # version 1.3.5
import numpy as np
def create_df():
\tdf = pd.DataFrame({'score': np.random.randint(01011000))
\treturn df
create_df()
df.head()
数据包括 1000 名学生的 0 到 100 分的考试分数 。而这次的任务是将数字分数分为值“A”、“B”和“C”的等级 , 其中“A”是最好的等级 , “C”是最差的等级 。
1、between & locPandas .between 方法返回一个包含 True 的布尔向量 , 用来对应的 Series 元素位于边界值 left 和 right[1
之间 。
参数有下面三个:
- left:左边界
- right:右边界
- inclusive:要包括哪个边界 。可接受的值为 {“both”、“neither”、“left”、“right” 。
- A: (80 100
- B: (50 80
- C: [0 50
df.loc[df['score'
.between(0 50 'both') 'grade'
= 'C'
df.loc[df['score'
.between(50 80 'right') 'grade'
= 'B'
df.loc[df['score'
.between(80 100 'right') 'grade'
= 'A'
以下是每个分数区间的人数:
df.grade.value_counts()
此方法需要为每个 bin 编写处理的代码 , 因此它仅适用于 bin 很少的情况 。
2、cut可以使用 cut将值分类为离散的间隔 。此函数对于从连续变量到分类变量[2
也很有用 。
cut的参数如下:
- x:要分箱的数组 。必须是一维的 。
- bins:标量序列:定义允许非均匀宽度的 bin 边缘 。
- labels:指定返回的 bin 的标签 。必须与上面的 bins 参数长度相同 。
- include_lowest: (bool) 第一个区间是否应该是左包含的 。
labels = ['C' 'B' 'A'
df['grade'
= pd.cut(x = df['score'
bins = bins labels = labels include_lowest = True)
这样就创建一个包含 bin 边界值的 bins 列表和一个包含相应 bin 标签的标签列表 。
查看每个区段的人数
df.grade.value_counts()
结果与上面示例相同 。
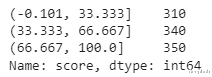
3、qcutqcut可以根据排名或基于样本分位数将变量离散为大小相等的桶[3
。
在前面的示例中 , 我们为每个级别定义了分数间隔 , 这回使每个级别的学生数量不均匀 。 在下面的示例中 , 我们将尝试将学生分类为 3 个具有相等(大约)数量的分数等级 。 示例中有 1000 名学生 , 因此每个分箱应该有大约 333 名学生 。
- switch|小米12Pro对比小米11ultra,哪个更值得购买?
- 小米科技|四月骁龙8机型销量对比,荣耀笑到最后,小米也不差
- 摩托罗拉|买对不买贵!这几款真香机值得入手,保证不踩坑
- CPU|阿里云跌至第四!研发比例逐年降低的背后,华为腾讯开始崛起
- 华为WATCH GT3 Pro|华为WATCH GT3 Pro男款开箱:四款华为手表外观对比,哪个好看?
- 联想|夜景拍摄实测对比,苹果、华为和OPPO哪家最强?样张见分晓
- 小米科技|小米MIX 5稳了,2K屏幕+隔空充电+徕卡镜头,这次绝对高端!
- 华为荣耀|荣耀次旗舰跌破四千元大关:对比新旗舰,还是有很多不足!
- CPU|选手机非得看处理器?不!普通用户看的其实是“大内存”
- 对台积电“出手” 了?老美做出选择,11家半导体厂商或将联手!