
文章图片

文章图片
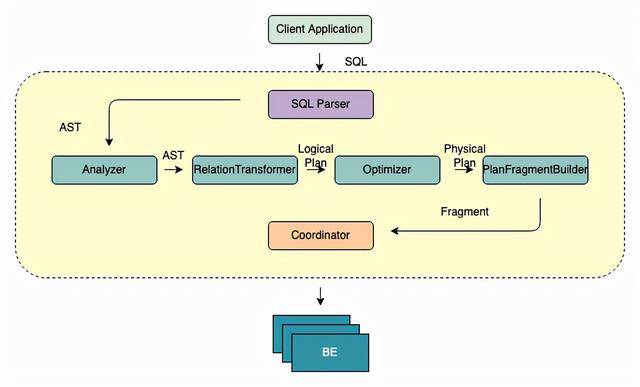
文章图片

前言 随着数字产业化和产业数字化成为经济驱动的重要动力 , 企业的数据分析场景越来越丰富 , 对数据分析架构的要求也越来越高 。 新的数据分析场景催生了新的需求 , 主要包括三个方面:
用户希望用更加低廉的成本 , 更加实时的方式导入并存储任何数量的关系数据数据(例如 , 来自业务线应用程序的运营数据库和数据)和非关系数据(例如 , 来自移动应用程序、IoT 设备和社交媒体的运营数据库和数据) 用户希望自己的数据资产受到严密的保护 用户希望数据分析的速度变得更快、更灵活、更实时 数据湖的出现很好的满足了用户的前两个需求 , 它允许用户导入任何数量的实时获得的数据 。 用户可以从多个来源收集数据 , 并以其原始形式存储到数据湖中 。 数据湖拥有极高的水平扩展能力 , 使得用户能够存储任何规模的数据 。 同时其底层通常使用廉价的存储方案 , 使得用户存储数据的成本大大降低 。 数据湖通过敏感数据识别、分级分类、隐私保护、资源权限控制、数据加密传输、加密存储、数据风险识别以及合规审计等措施 , 帮助用户建立安全预警机制 , 增强整体安全防护能力 , 让数据可用不可得和安全合规 。
为了进一步满足用户对于数据湖分析的要求 , 我们需要一套适用于数据湖的分析引擎 , 能够在更短的时间内从更多来源利用更多数据 , 并使用户能够以不同方式协同处理和分析数据 , 从而做出更好、更快的决策 。 本篇文章将向读者详细揭秘这样一套数据湖分析引擎的关键技术 , 并通过 StarRocks 来帮助用户进一步理解系统的架构 。
之后我们会继续发表两篇文章 , 来更详细地介绍极速数据湖分析引擎的内核和使用案例:
代码走读篇:通过走读 StarRocks 这个开源分析型数据库内核的关键数据结构和算法 , 帮助读者进一步理解极速数据湖分析引擎的原理和具体实现。Case Study 篇:介绍大型企业如何使用 StarRocks 在数据湖上实时且灵活的洞察数据的价值 , 从而帮助业务进行更好的决策 , 帮助读者进一步理解理论是如何在实际场景落地的。 什么是数据湖? 【数据库|如何打造一款极速数据湖分析引擎】什么是数据湖 , 根据 Wikipedia 的定义 , “A data lake is a system or repository of data stored in its natural/raw format usually object blobs or files” 。 通俗来说可以将数据湖理解为在廉价的对象存储或分布式文件系统之上包了一层 , 使这些存储系统中离散的 object 或者 file 结合在一起对外展现出一个统一的语义 , 例如关系型数据库常见的“表”语义等 。
了解完数据湖的定义之后 , 我们自然而然地想知道数据湖能为我们提供什么独特的能力 , 我们为什么要使用数据湖?
在数据湖这个概念出来之前 , 已经有很多企业或组织大量使用 HDFS 或者 S3 来存放业务日常运作中产生的各式各样的数据(例如一个制作 APP 的公司可能会希望将用户所产生的点击事件事无巨细的记录) 。 因为这些数据的价值不一定能够在短时间内被发现 , 所以找一个廉价的存储系统将它们暂存 , 期待在将来的一天这些数据能派上用场的时候再从中将有价值的信息提取出来 。 然而 HDFS 和 S3 对外提供的语义毕竟比较单一(HDFS 对外提供文件的语义 , S3 对外提供对象的语义) , 随着时间的推移工程师们可能都无法回答他们到底在这里面存储了些什么数据 。 为了防止后续使用数据的时候必须将数据一一解析才能理解数据的含义 , 聪明的工程师想到将定义一致的数据组织在一起 , 然后再用额外的数据来描述这些数据 , 这些额外的数据被称之为“元”数据 , 因为他们是描述数据的数据 。 这样后续通过解析元数据就能够回答这些数据的具体含义 。 这就是数据湖最原始的作用 。
- 跑分|市场份额高达27.02% 大屏时代排名第一的TCL是如何做到的
- 锐龙|荣耀magic4和华为mate40Pro相比较,该如何选?
- 亚马逊|一加9pro、努比亚z40pro和小米mix4相比较,该如何选?
- 三星|如何设置路由器上网和路由器常用的基本参数?
- 本文转自:东方网材料递交是打官司不可或缺的一环。|如何足不出户线上递诉讼材料?
- Windows这几代都对搜索功能作了改进|如何屏蔽某些文件目录在win11中出现?
- 神译局是36氪旗下编译团队|如何提高自己的学习效率?
- 段永平|美国若真切断俄互联网,俄罗斯如何应对?
- 芯片|真正的“新荣耀”高端耳机实力如何?这篇文章带你快速了解
- 市场份额高达27.02% 大屏时代排名第一的TCL是如何做到的