擎天柱|业务进阶:AI图像识别( 二 )
2)描述学习
直接把数据丢给算法模型,又称为“聚类”。
在给定一系列仅由输入实例构成的数据集的条件下,其目标是发现数据中的有趣模式。
描述学习有时候也称为只是发现,这类问题并没有明确定义,因为我们不知道需要寻找什么样的模式,也没有明显的误差度量可供使用。为了让机器能够理解物体之间的关系,我们最终把现实中的特征转化为“向量”进行计算。
例如擎天柱,张三和我,如果细分的话,张三和我应该是一类,因为属于人类;擎天柱属于机械类。最后三者才同归属于生命体类。
3)算法模型
目前所有算法模型都是各有千秋的状态,没有一种算法能够被证明全面优于其他算法,每种算法都是为了解决某一特定场景的问题,只有某一特定场景更优的算法,可以通过对比找到其中最好的算法。
目前出现的相对流行的算法主要是以对象、区域、上下文等场景的分类算法:
① 基于对象的场景分类
这种分类方法以对象为识别单位,根据场景中出现的特定对象来区分不同的场景;基于视觉的场景分类方法大部分都是以对象为单位的,也就是说,通过识别一些有代表性的对象来确定自然界的位置。
典型的基于对象的场景分类方法有以下的中间步骤:特征提取、重组和对象识别。
缺点:底层的错误会随着处理的深入而被放大。例如,上位层中小对象的识别往往会受到下属层相机传感器的原始噪声或者光照变化条件的影响。尤其是在宽敞的环境下,目标往往会非常分散,这种方法的应用也受到了限制。
需要指出的是,该方法需要选择特定环境中的一些固定对象,一般使用深度网络提取对象特征,并进行分类。例如PCA算法实现识别人脸降维原理,排除冗余和噪音的干扰,试验步骤如下:
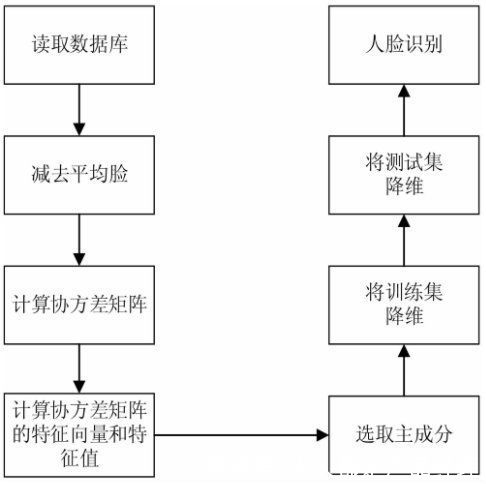
文章插图
② 基于区域的场景分类
首先通过目标候选候选区域选择算法,生成一系列候选目标区域,然后通过深度神经网络提取候选目标区域特征,并用这些特征进行分类。
例如K-means算法,它把N个对象根据属性分为K个类别,使得结果满足:同一类中的对象相似度较高,不同的对象相似度较小,定义损失函数如下:
其中Xn为待分类的数据点,μk为第k个类别的中心,Rnk∈{0,1}来表示数据点Xn对于k的归属(其中n=1,。。。,N;k=1,。。。,k)
如果数据点Xn属于第k类,则Rnm=1,否则为0。
K-means通过迭代求解,得到使得损失函数J最小的所有数据点的归属值{Rnk}和聚类中心{μk}。
③ 基于上下文的场景分类
这类方法不同于前面两种算法,而将场景图像看作全局对象而非图像中的某一对象或细节,这样可以降低局部噪声对场景分类的影响。将输入图片作为一个特征,并提取可以概括图像统计或语义的低维特征。
该类方法的目的即为提高场景分类的鲁棒性。因为自然图片中很容易掺杂一些随机噪声,这类噪声会对局部处理造成灾难性的影响,而对于全局图像却可以通过平均数来降低这种影响。
基于上下文的方法,通过识别全局对象,而非场景中的小对象集合或者准确的区域边界,因此不需要处理小的孤立区域的噪声和低级图片的变化,其解决了分割和目标识别分类方法遇到的问题。
四、图像识别过程图像识别技术归纳起来,主要包括4个步骤:
1)首先是获取信息,主要是指将各类信息通过传感器向电信号转换,也就是对识别对象的基本信息进行获取,并通过“聚类”的方式,将其向计算机可识别的信息转换。
- 电子商务|阿里“透底”云业务近况:非互联网占营收52%,云计算新周期已至?
- gmv|美欧同意禁止俄罗斯使用SWIFT系统;滴滴称不会关闭俄罗斯业务;微信微博抖音处理涉俄乌局势不当言论丨邦早报
- 进阶|?红米系列手机,质量还是相当可靠,操作系统也很好用
- NVIDIA|被黑客勒索攻击 NVIDIA:业务没有受到干扰 仍在评估
- 手机业务|李斌要在雷军地盘上“踩一脚”
- ign|狐讯|百度回应多条业务线裁员 ;《艾尔登法环》正式开售
- 业务收入|上海“双千兆”用户稳步增长
- yy|百度多个业务线人员精简,涉及核心技术部门
- 车商|透过汽车之家二手车业务,看二手车市场的模式终局
- 快手视频|为实现电商业务闭环,快手与淘宝、京东“断舍离”