本文为re:Invent 2021亮点解读的第二部分,关于机器学习的部分,此前介绍了关于Graviton的内容,后续还有关于存储的部分,欢迎关注。
正文:
人工智能和机器学习被许多企业视为提升竞争力的关键技术,企业的顾虑主要在成本上,一方面是直接需要投入的算力资源和人员资源成本,另一部分是时间成本,随着机器学习模型的加速膨胀,问题越来越突出。
众所周知,GPU显卡的价格很高,构建GPU服务器训练集群的成本也会高,云计算可以非常便捷地让用户快速享用到庞大的计算资源,高速网络以及大容量存储资源,即使是面对规模最大的模型,也能快速完成训练任务,从容应对。
所以,云计算很适合用来承载机器学习负载,就凭这点,我们可以认为未来更多机器学习的负载会放到云上。
用芯片层面的创新降低成本
此前,亚马逊云科技发布了第一款机器学习芯片叫Amazon Inferentia,顾名思义,是做推理的,实际应用中推理的工作负载量是非常大的,Amazon Inferentia芯片的性能和吞吐量都能满足实际要求,而且,Inf1实例的成本比基于GPU的方案要低很多。

文章插图
虽然推理的负载多,但一般企业也经常遇到训练任务,机器学习的训练环节经常需要用到昂贵的GPU,所以训练的成本通常会很高。
为了降低成本,亚马逊云科技发布了Amazon Trainium芯片,据说采用该芯片的Trn1实例(或者说集群)可以提供云端速度最快,成本最低的训练服务。

文章插图
Trn1实例,有13.1TB/s的最大内存带宽,3.4 PFLOPS的算力,FP32的TFlops高达840,时钟频率为4GHz,含有550亿个晶体管。
实际应用起来如何呢?
亚马逊云科技提供的信息显示,在训练深度学习模型时,采用Amazon Trainium芯片的Trn1实例的成本,要比采用英伟达A100的P4d实例最多低出40%,而且速度最多能快50%。
一句话总结Amazon Trainium的特点,兼具GPU的灵活性和专用加速器的效率。
之所以大家喜欢用GPU做训练,主要是因为GPU除了性能高,而且灵活性也非常高,专用的加速器虽然效率很高,但灵活性较差。
为了避免灵活性上的问题,Amazon Trainium内置了16个专用的可编程数据处理器,支持各种机器学习框架,以提供更好的灵活性。所以,它比专用的加速器更灵活。
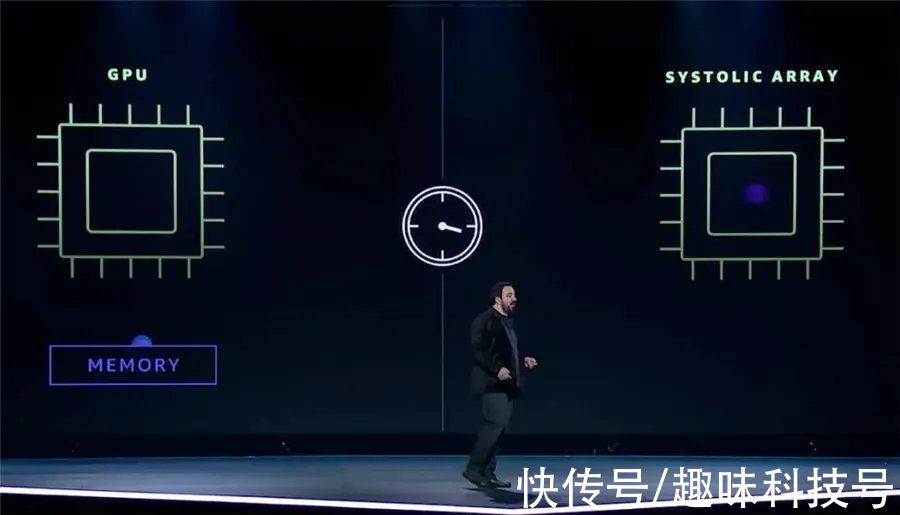
文章插图
与GPU相比,Amazon Trainium采用了一种新的运算模式,避免了GPU需要频繁与内存交换数据的麻烦,在芯片内完成训练。Peter没介绍太多细节,但是感觉这一说法跟此前了解过的存算一体化的思路有异曲同工之妙,有机会我再学习一下。
用大规模机器学习训练集群提升效率

文章插图
从P3、P3dn再到P4d、Trn1,内存容量和网络性能不断提升
为了提升机器学习训练的效率,机器学习加速器的内存不断加大,网络带宽也在不断提升。
Trn1实例提供800Gbps EFA网络带宽,它比P4d快一倍,网络性能更强的Trn1n比Trn1又快了一倍,达到1600Gbps。
用户可以启动具有EC2 UltraClusters功能的Trn1实例,EC2 UltraClusters可以让训练扩展到多个用高速网络互连的Trainium芯片,从而实现分布式并行训练。
这不仅意味着用户可以快速获得超算级性能,而且,让用户训练大型复杂模型的时间大大缩短,成本也大量节省。

- 芯片|上市仅4个月,跌价1000元,微云台主摄+6nm芯片+4400mAh
- iPhone|iphone14价格被曝!“胶囊”挖孔屏+三星4nm芯片,售价或5999起
- 信息科学技术学院|瞧不起中国芯?芯片女神出手,30岁斩获国际大奖,让美国哑口无言
- 400亿芯片交易接近尾声,英伟达、ARM表明态度,禁止收购后
- 芯片|据称索尼和台积电计划在日本投资70亿美元建芯片工厂
- 体验首款Linux消费级平板,原来芯片和系统全是国产
- 算力|不靠显卡!NVIDIA在中国焕发第二春:自动驾驶芯片被车厂爆买
- 小米12|自研动态性能调度!小姐姐实测小米12 Pro《王者荣耀》:功耗下降20%
- 军工|中国版“英伟达”诞生,核心技术完全自研,国产替代即将崛起
- 芯片|腾讯立功了,国产芯片迎来好消息,重要程度不亚于华为鸿蒙