数据集|数据缩至1/5000,模型准确率却翻倍,谷歌新“蒸馏法”火了
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在炼丹过程中,为了减少训练所需资源,MLer有时会将大型复杂的大模型“蒸馏”为较小的模型,同时还要保证与压缩前相当的结果。
这就是知识蒸馏,一种模型压缩/训练方法。
不过随着技术发展,大家也逐渐将蒸馏的对象扩展到了数据集上。
这不,谷歌最近就提出了两种新的数据集蒸馏方法,在推特上引起了不小反响,热度超过600:
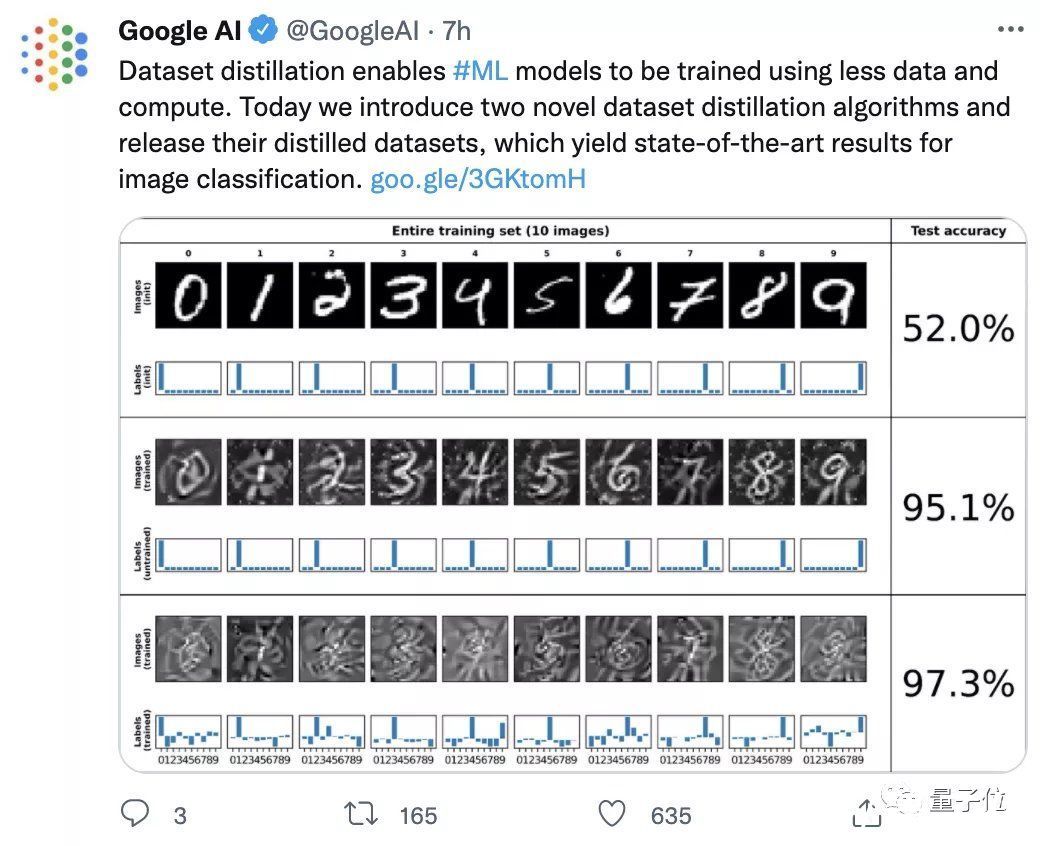
文章插图
像这样, 将50000张标注图像的CIFAR-10数据集“蒸馏”缩小至1/5000大小,只基于10张合成数据点进行训练,模型的准确率仍可近似51%:

文章插图
△上:原始数据集 下:蒸馏后
而如果“蒸馏数据集”由500张图像组成(占原数据集1%大小),其准确率可以达到80%。
两种数据集蒸馏方法分别来自于ICLR 2021和NeurIPS 2021上的两篇论文。

文章插图

文章插图
通过两阶段循环进行优化那么要如何才能“蒸馏”一个数据集呢?
其实,这相当于一个两阶段的优化过程:
- “内部循环”,用于在学习数据上训练模型
- “外部循环”,用于优化学习数据在自然数据上的性能
这时,谷歌提出的两种方法就分别有了不同的处理路线:
一、标注解释 (LS)
这种方法直接解释最小化KRR损失函数的支持标注集(support labels),并为每个支持图像生成一个独特的密集标注向量。
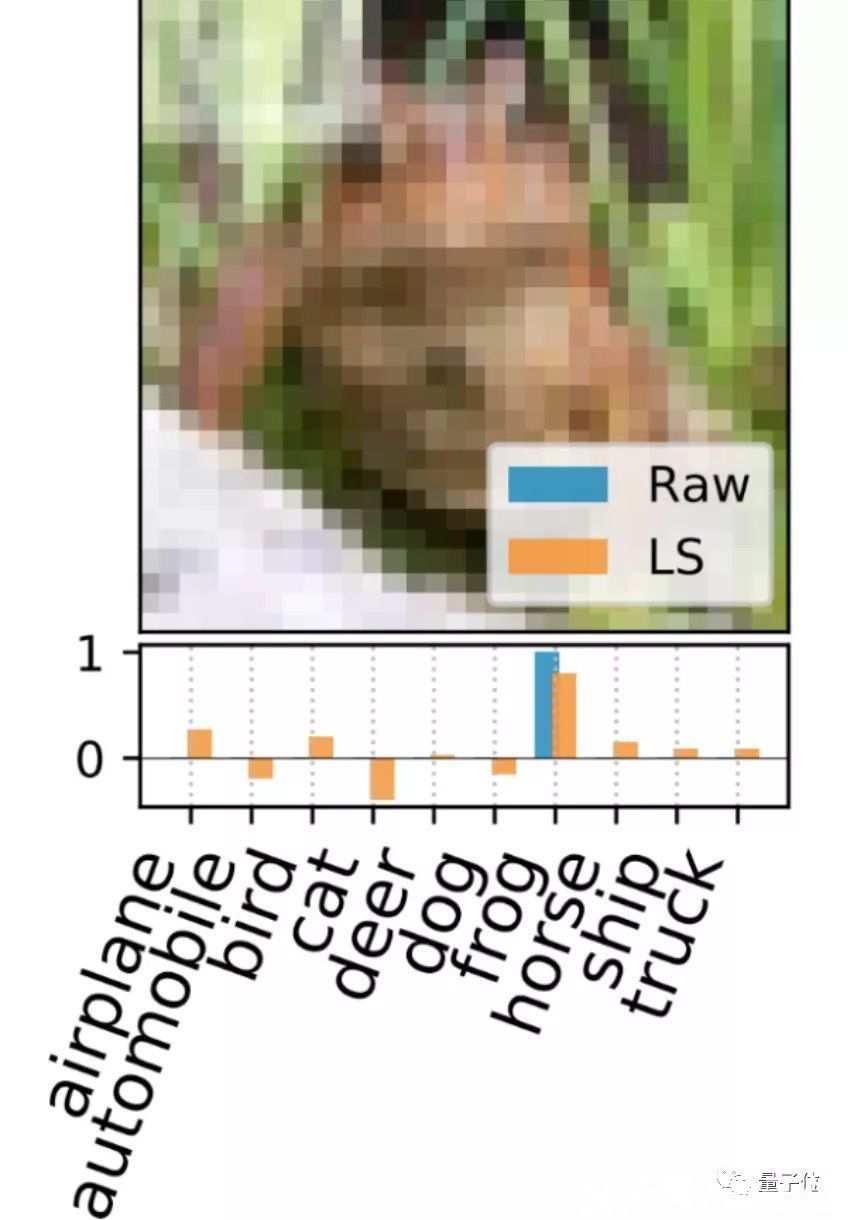
文章插图
△蓝:原始独热标注 橙:LS生成的密集标注
二、核归纳点 (KIP)
这种方法通过基于梯度的方法将KRR损失函数最小化,以此来优化图像和可能生成的数据。
以MNIST为例,下图中的上、中、下三张图分别为原始的MNIST数据集、固定标注的KIP蒸馏图像、优化标注的KIP蒸馏图像。
可以看出,在于对数据集进行蒸馏时,优化标注的效果最好:

文章插图
对比已有的DC(Dataset Condensation)方法和DSP(Dataset Condensation with Differentiable Siamese Augmentation)方法可以看到:
如果使用每类别只有一张图像,也就是最后只有10张图像的蒸馏数据集,KIP方法的测试集准确率整体高于DC和DSP方法。
在CIFAR-10分类任务中,LS也优于先前的方法,KIP甚至可以达到翻倍的效果。
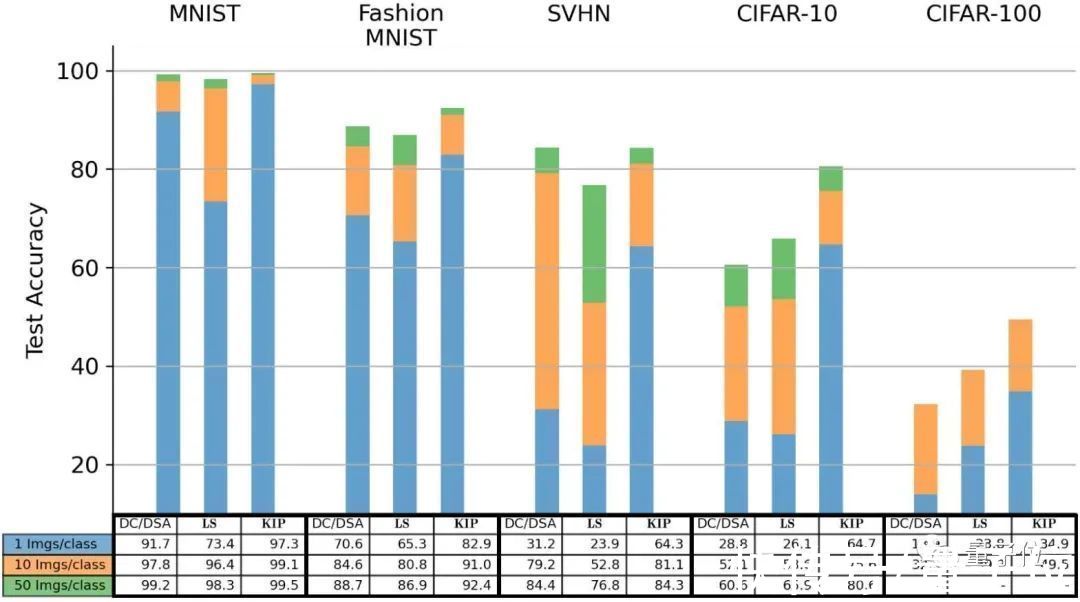
文章插图
对此,谷歌表示:
这证明了在某些情况下,我们的缩小100倍的“蒸馏数据集”要比原始数据集更好。
两位华人作者整个项目由萧乐超(Lechao Xiao)、Zhourong Chen、Roman Novak三人合作完成。
其中萧乐超为LS方法的论文作者之一,本科毕业于浙江大学的应用数学系,在美国伊利诺大学厄巴纳-香槟分校(UIUC)取得博士学位,现在是谷歌大脑团队的一名科学家。
他的主要研究方向是数学、机器学习和深度学习。

文章插图
另一位华人科学家Zhourong Chen则是KIP方法的论文作者之一,本科毕业于中山大学,并在香港科技大学取得了计算机科学与工程系的博士学位,现是Google Research的一名软件工程师。
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- OpenHarmony 项目群 12 月新增捐赠人美的集团、深圳开鸿
- 财智干货|数智化发展任重道远,财务中台提升数据服务价值 | 大数据
- 支付宝集五福活动 1 月 19 日正式开始,现可提前领福
- 美少女1985集
- 央媒表态后,联想关键数据出炉,柳传志这回要扳回一局?
- 电子封装技术、微电子、集成电路等,电子信息类专业,研究方向
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- 注册资本|美的集团投资成立汽车部件公司,注册资本 2 亿元