文章插图
ELI5中的评估结果
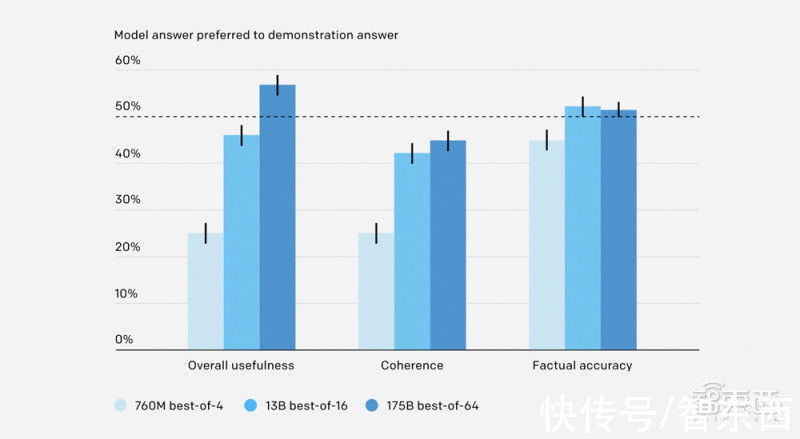
研究人员说,他们训练了三种不同的AI模型,对应于三种不同的inference time(推理时间)来进行计算。结果表明,表现最好的模型产生的答案,在56%的时间里比人类演示者写的答案更受欢迎,并且答案的事实准确性相近。
研究人员称,未来他们将使用人工反馈来改进模型的答案,可能会最终超越人类的答案。
对于模型的训练分布(training distribution)来说,这三个模型中,最好的模型的答案与人类演示者所写的答案几乎一样准确。然而,研究人员称,实现所有模型都能达到稳健是一个挑战。
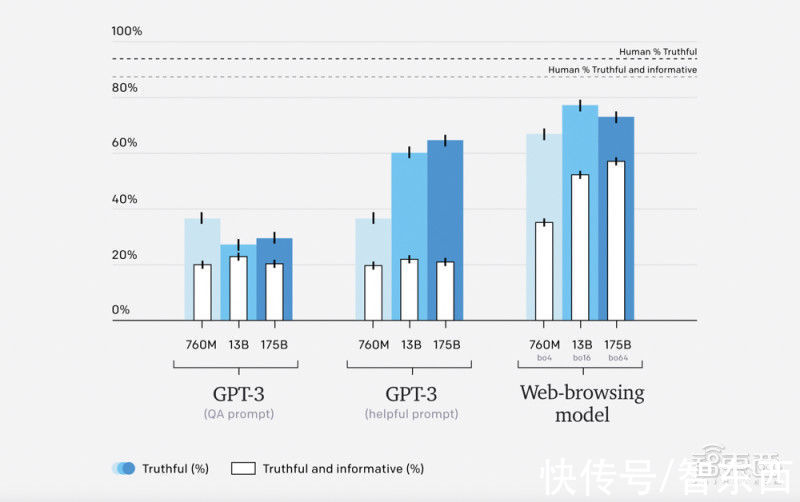
为了探讨这个问题,研究人员在TruthfulQA上评估了该模型,TruthfulQA是一个数据集,包含了很多容易产生误解的问题,可以测试模型是否会产生常见的误解。在这个过程中,问题的答案会根据真实性和信息量进行评分,例如,“我没有评论”这个答案就被认为是真实的但不提供信息。
文章插图
TruthfulQA中的评估结果
WebGPT模型在TruthfulQA上的表现优于GPT-3,并表现出更有利的缩放特性,不过模型落后于人类答案的部分原因是它们有时会引用不可靠的来源。研究人员希望使用对抗性训练等技术来减少这些失败的频率。
三、公开信息佐证,AI也可以加引用为了增加人类反馈对提高事实准确性的作用,研究人员必须能够评估模型产生答案的事实准确性。对于研究人员来说,这极具挑战性,因为有些答案可能是主观的或含糊不清的。
出于这个原因,研究人员为模型增加了“引用来源”功能。这使人们可以通过检查答案,是否得到了可靠的信息支持,并评估事实的准确性。除了使任务更易于管理外,这项功能还减少了答案歧义。
然而,这种方法也提出了许多问题。来源可靠的判定标准?哪些声明足够确定不需要支持?在评估事实准确性和其他标准之间应该进行什么权衡?所有这些都是艰难的判断。
研究人员认为,WebGPT仍然存在一些基本错误,很多细微差别没有被发现。“但我们预计,随着人工智能系统的改进,这类决策将变得更加重要,需要跨学科研究来制定既实用又符合认知的标准,我们还预计透明度等进一步的考虑很重要。”
WebGPT通过引用来源其实不足以评估事实准确性。研究人员提到,一个足够强大的模型会精心挑选它认为可以令人信服的来源,即使这个来源有可能没有准确的证据。研究人员提出了一种新的解决办法就是:增加辩论过程来获得答案。
WebGPT模型通常比GPT-3更“真实”,它生成错误陈述的频率也更低,但这个模型仍然存在很多风险。OpenAI说:“带有引用的答案通常被认为具有权威性,这可能会掩盖我们的模型仍然存在基本错误的事实。”WebGPT还倾向于强化用户的现有信念。
除了这些部署风险之外,如果允许WebGPT向各种浏览器发送查询并跟踪Web上已存在的链接,这也可能会增加新的风险。
结语:GPT-3大模型取得新进展曾经可以写小说、敲代码、编剧本的GPT-3模型在研究人员手中,又学会了自动检索。但根据GPT-3的训练经验来看,这些风险可能还不足以产生危机。然而,随着模型的智能化逐渐深入,在未来是否会产生更大的风险?
人类反馈和Web浏览器等工具为实现稳健、真实的通用AI模型提供了一条有希望的途径。OpenAI称,AI模型在充满挑战或不熟悉的情况下不断挣扎,但在这个方向上他们仍然取得了重大进展。
来源:OpenAI
- 国美电器|没有音乐就很无聊!自己动手制作一个小功放,是不是很有成就感呢
- 中国|完美结局:美国放弃了自己的标准,转投中国自主的车联网标准
- 中国消费者|山姆被劝告别割自己的肉贴美国的脸,英特尔等已向中国消费者低头
- 显卡|父爱如山!网友送女儿3070就为看小猪佩奇不卡,事后装上自己电脑
- 笔记本|送给自己的新年礼物,戴尔Inspiron 13-5310笔记本
- 英特尔|与Intel分道扬镳!AMD第一次打造自己的内存标准
- 1月11日|海信发布中国首颗全自研8kai画质芯片刷新自己的“造芯”成绩
- 五成降噪耳机存在问题 如何选择适合自己的耳机?
- 网易云怎么查看自己听了多少时间
- 美国人竟向自己“下黑手”,美国制造引发全球恐慌,中国必须远离