领域|IEEE Fellow梅涛:视觉计算的前沿进展与挑战( 二 )
这说明深度学习领域在飞速发展,而且进入这个领域的人越来越多。一方面不仅深度学习网络在不断“更新换代”,图像、视频等数据集也在不断增长,甚至有些数据集规模已经过亿。
其中,深度学习的一个趋势是“跨界”。在2019年,Transformer在自然语言处理领域的性能被证明“一枝独秀”,现在已经有大量学者开始研究如何将其纳入视觉领域,例如微软亚洲研究院swin transformer相关工作获得了ICCV的最佳论文奖。
文章插图
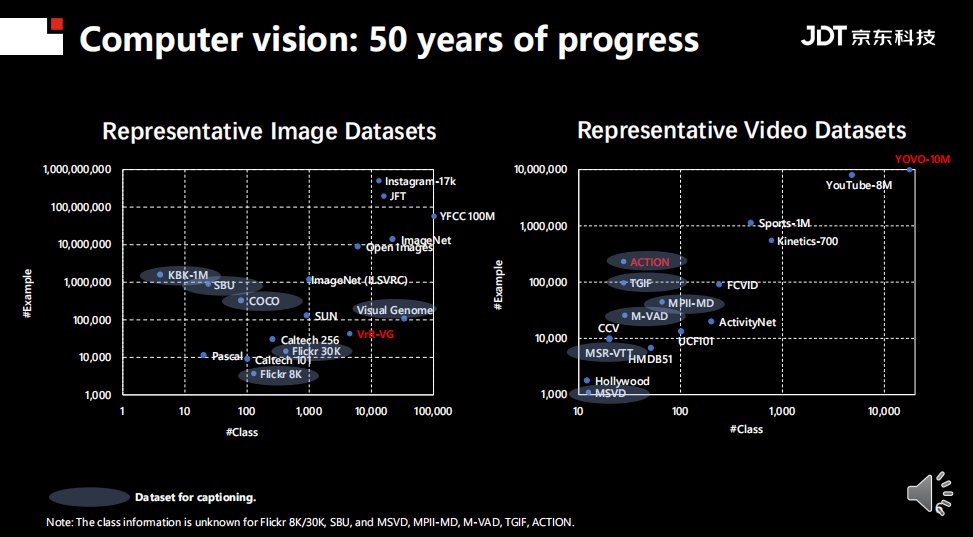
上图展示了随着研究范式的变化,数据集的变化趋势。无论是数据集的类别还是数据集的规模都在不断增大,有些数据集更是超过了10亿级别。目前类别最多的是UCF101数据集,其中包括101个类。同时,大规模也带来了一个弊端:一些高校和小型实验室无法进行模型训练。
文章插图
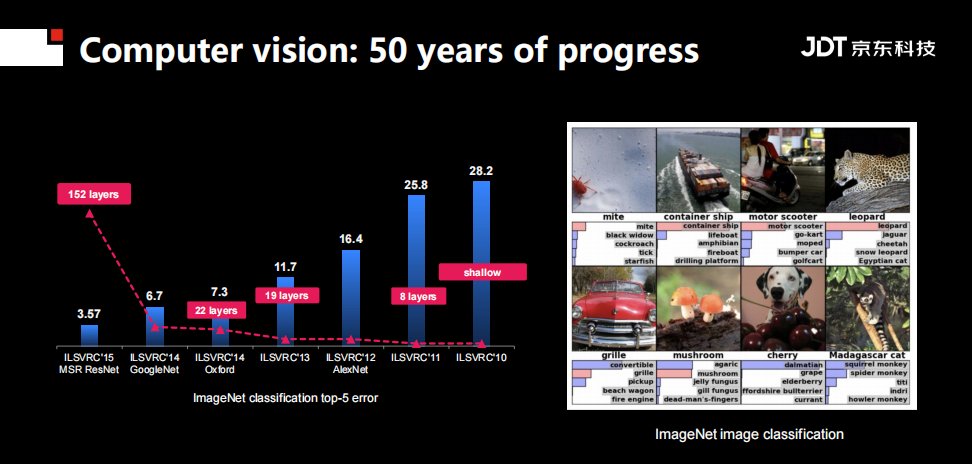
特定领域进展如何?在图像识别领域,最广为人知莫过于ImageNet竞赛。其任务是给定一张图,预测出五个相关的标签。随着深度学习网络的层数越来越深,识别的错误率越来越低,到2015年, ResNet已经它达到了152层,并且已经超过了人类识别图像的能力。
文章插图
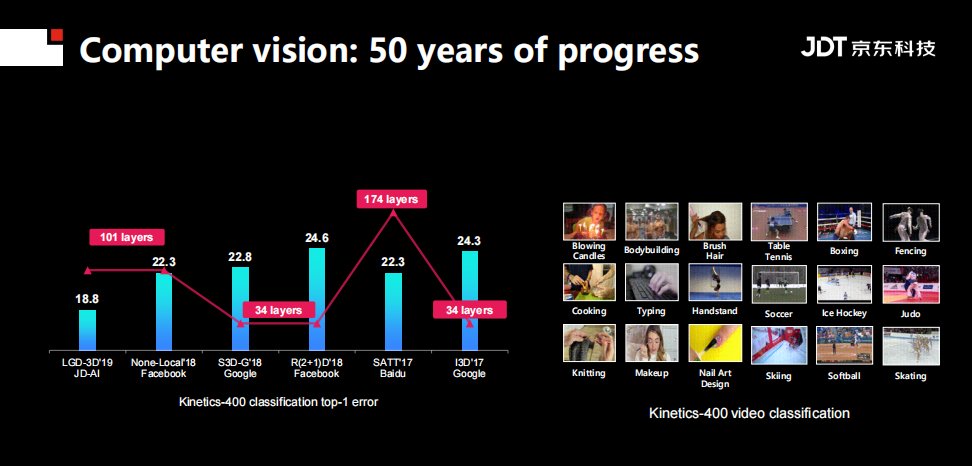
在视频分析领域。Kinetics-400 视频分析任务反应了该领域的进展,从2017年和2019年出现了各种适合视频任务的神经网络,其网络大小、深度并不一致,而且从准确率、识别精度上看,也没有一致的结果。换句话说,该领域存在大量的潜力(open question)。至于原因,个人认为有两种:
1.视频内容非常多样化,而且是时空连续的数据。
2.同样的语义,在视频中会有不同的含义。例如不同语气和不同表情下对同一个词的输出。

文章插图
过去10~20年,视觉感知领域存在很多主题。如上图所示,从最小力度的像素级别到视频级别,基本上可以归为几大研究领域:语义分隔、物体检测、视频动作行为识别、图像分类、Vision and language。其中,Vision and language最近五年比较火热,其要求不仅从图视频内容里面生成文字描述,并且也可以反过来从文字描述生成视频或者图片的内容。
总结起来,目前视觉研究的主要方向还是进行RGB视频和图像研究,在不远的将来,成像的方式会发生变化,那时研究的数据将不仅是2D,更会过渡3D,甚至更多的多模态的数据。
在视觉理解领域,通用的视觉理解非常简单:例如区分猫和狗,区分车和人。但在自然界里,要真正的做到对世界的理解,其实要做到非常精细的粒度的图像识别。一个直观的例子是鸟类识别,理想中的机器需要识别10万种鸟类,才能达到人类对“理解世界”的要求。如果再精细一些,需要达到商品SKU细粒度识别。
注:一瓶200毫升和300毫升的矿泉水就是不同粒度的SKU。
过去几年,京东在这方面做了一些探索。探索路径包括:detection的方式,detection结合attention的方式,以及自监督的方式。涉及论文包括CVPR2019 的“Destruction and Construction Learning ”以及CVPR 2020的“Self-supervised”相关工作。

文章插图
论文地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Destruction_and_Construction_Learning_for_Fine-Grained_Image_Recognition_CVPR_2019_paper.pdf
- ios|华为迎来新里程碑,在新领域旗开得胜!
- Google|全球游戏领域的标杆,MSI&AMD把事情做得很漂亮
- 6g|港媒:中国又在这一领域让美国寝食难安
- 齐鲁壹点|36氪首发 | 「艾灵网络」获数千万元Pre-A+轮投资,为工业领域搭建最后一公里ICT基础设施
- 营收|富士康多领域逢劲敌,比亚迪已夺下4次销冠,苹果订单也被抢走3%
- Apple Watch|Surface Go 3评测:轻量办公领域一骑绝尘
- 1月10日|lg新能源ceo喊话行业巨头宁德时代在中国动力电池领域的霸主
- 读特客户端?深圳新闻网2022年1月14日讯(记者 罗瑜 实习生 韦秋颜 )1月6日|易星标技术荣获集成电路领域“创芯新锐奖”
- 2021年IT影响中国:云米获得“人工智能领域影响力企业”荣誉
- 进步奖|招标股份董秘回复:公司研发的生态环境数字孪生平台在下游应用领域更多基于客户自身需求