torch|英伟达PyTorch优化神器重磅更新!10亿参数模型运行,GPT加速21倍
编辑:好困 小咸鱼
【新智元导读】12月2日,英伟达发布了最新的TensorRT 8.2版本,对10亿级参数模型进行了优化,让实时运行NLP应用成为可能。与原始PyTorch模型相比,TensorRT可以将T5、GPT-2的延迟降低9到21倍。
众所周知,PyTorch和TensorFlow是两个非常受欢迎的深度学习框架。
12月2日,英伟达发布了最新的TensorRT 8.2版本,对10亿级参数的NLP模型进行了优化,其中就包括用于翻译和文本生成的T5和GPT-2。
而这一次,TensorRT让实时运行NLP应用程序成为可能。

文章插图
【 torch|英伟达PyTorch优化神器重磅更新!10亿参数模型运行,GPT加速21倍】Torch-TensorRT:6倍加速
TensorRT是一个高性能的深度学习推理优化器,让AI应用拥有低延迟、高吞吐量的推理能力。
新的TensorRT框架为PyTorch和TensorFlow提供了简单的API,带来强大的FP16和INT8优化功能。
只需一行代码,调用一个简单的API,模型在NVIDIA GPU上就能实现高达6倍的性能提升。

文章插图
Torch-TensorRT:工作原理
Torch-TensorRT编译器的架构由三个阶段组成:
简化TorchScript模块转换执行
简化TorchScript模块
Torch-TensorRT可以将常见操作直接映射到TensorRT上。值得注意的是,这种过程并不影响计算图本身的功能。
解析和转换TorchScript
转换
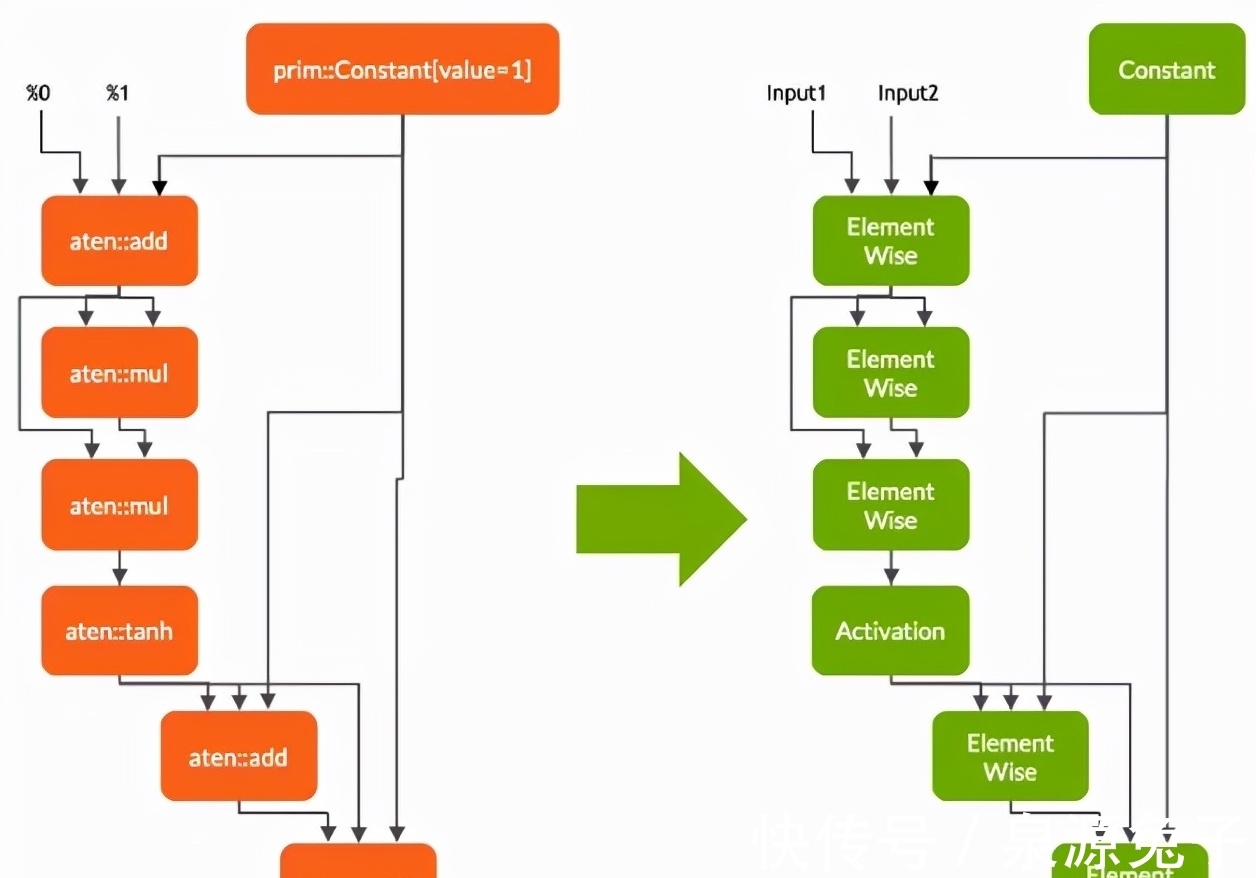
Torch-TensorRT自动识别与TensorRT兼容的子图,并将它们翻译成TensorRT操作:
具有静态值的节点被评估并映射到常数。描述张量计算的节点被转换为一个或多个TensorRT层。剩下的节点留在TorchScript中,形成一个混合图,并作为标准的TorchScript模块返回。
文章插图
将Torch的操作映射到TensorRT上
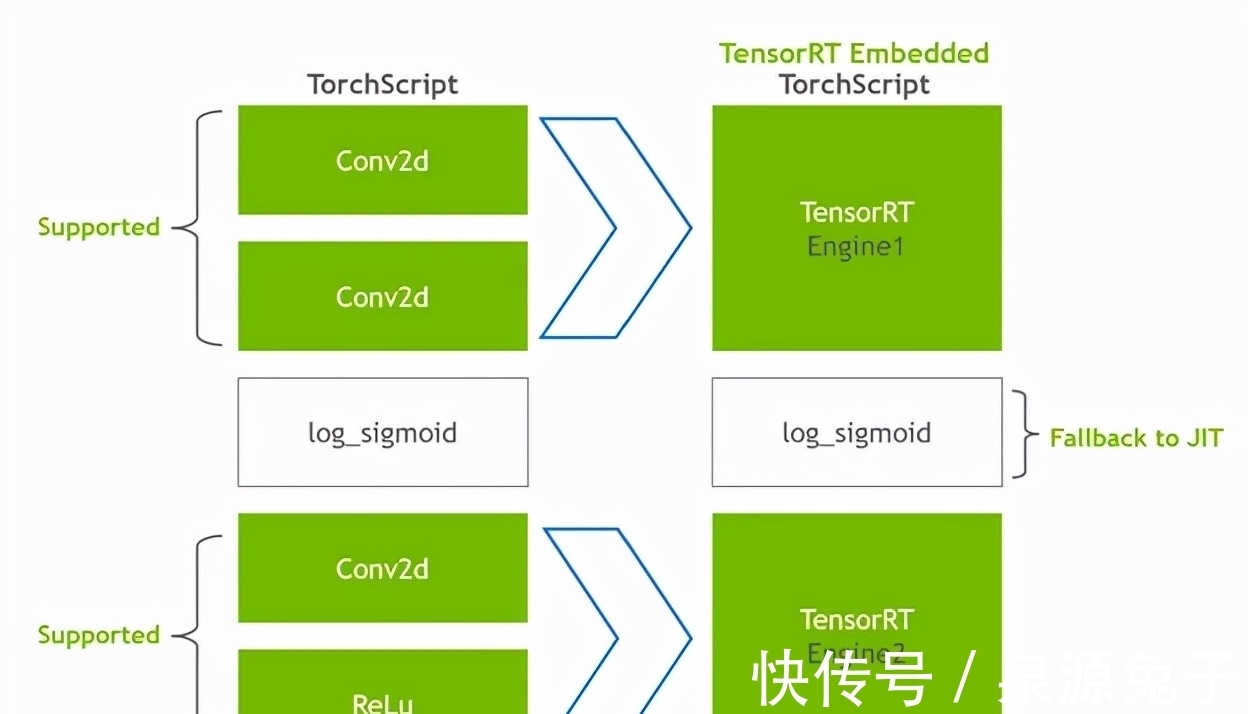
修改后的模块会在嵌入TensorRT引擎后返回,也就是说整个模型,包括PyTorch代码、模型权重和TensorRT引擎,都可以在一个包中进行移植。
文章插图
将Conv2d层转化为TensorRT引擎,而log_sigmoid则回到TorchScript JIT中
执行
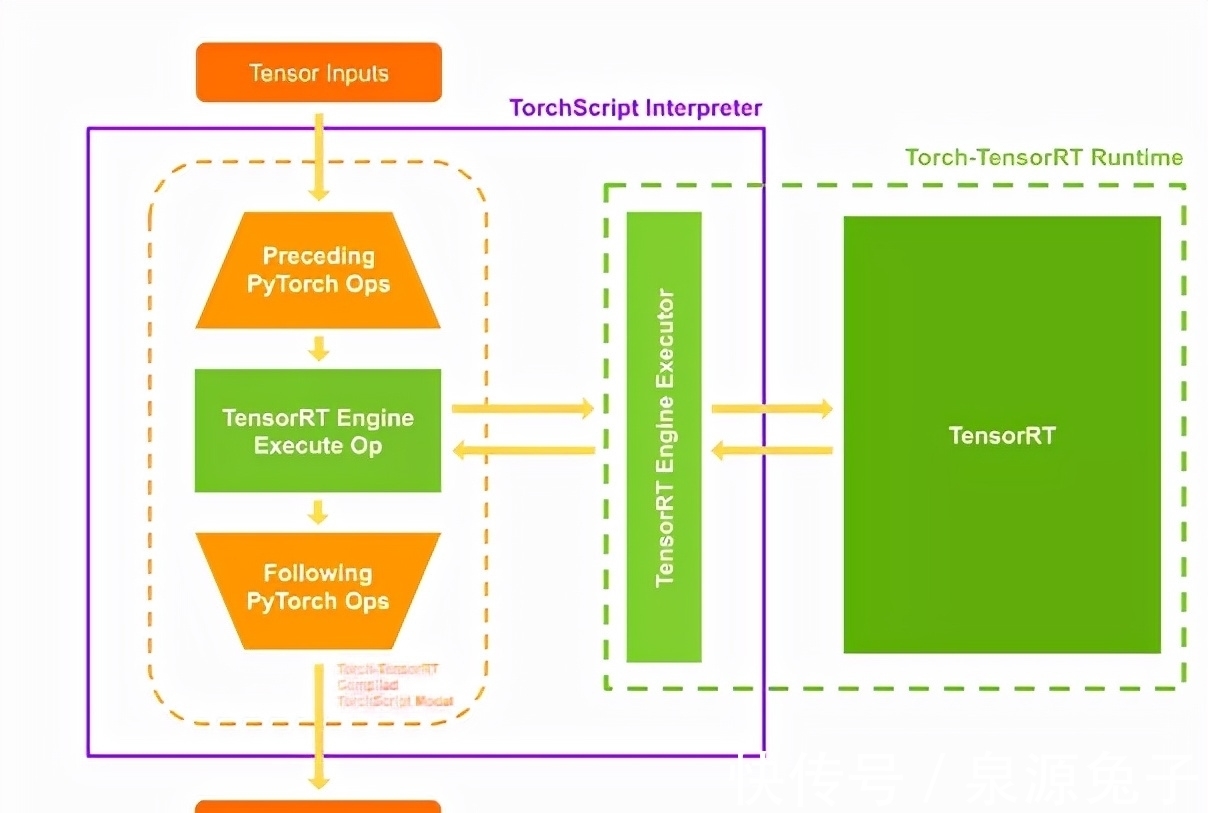
当执行编译模块时,TorchScript解释器会调用TensorRT引擎并传递所有输入。之后,TensorRT会将结果推送回解释器,整个流程和使用普通的TorchScript模块别无二致。
文章插图
PyTorch和TensorRT操作的运行时执行
Torch-TensorRT:特点
对INT8的支持
Torch-TensorRT通过两种技术增强了对低精度推理的支持:
训练后量化(PTQ)量化感知训练(QAT)
对于PTQ来说,TensorRT用目标领域的样本数据训练模型,同时跟踪FP32精度下的权重激活,以校准FP32到INT8的映射,使FP32和INT8推理之间的信息损失最小。
稀疏性
英伟达的安培架构在A100 GPU上引入了第三代张量核心,可以在网络权重中增加细粒度的稀疏性。
因此,A100在提供最大吞吐量的同时,也不会牺牲深度学习核心的矩阵乘法累积工作的准确性。
TensorRT支持在Tensor Core上执行深度学习模型的稀疏层,而Torch-TensorRT将这种稀疏支持扩展到卷积和全连接层。
举个例子
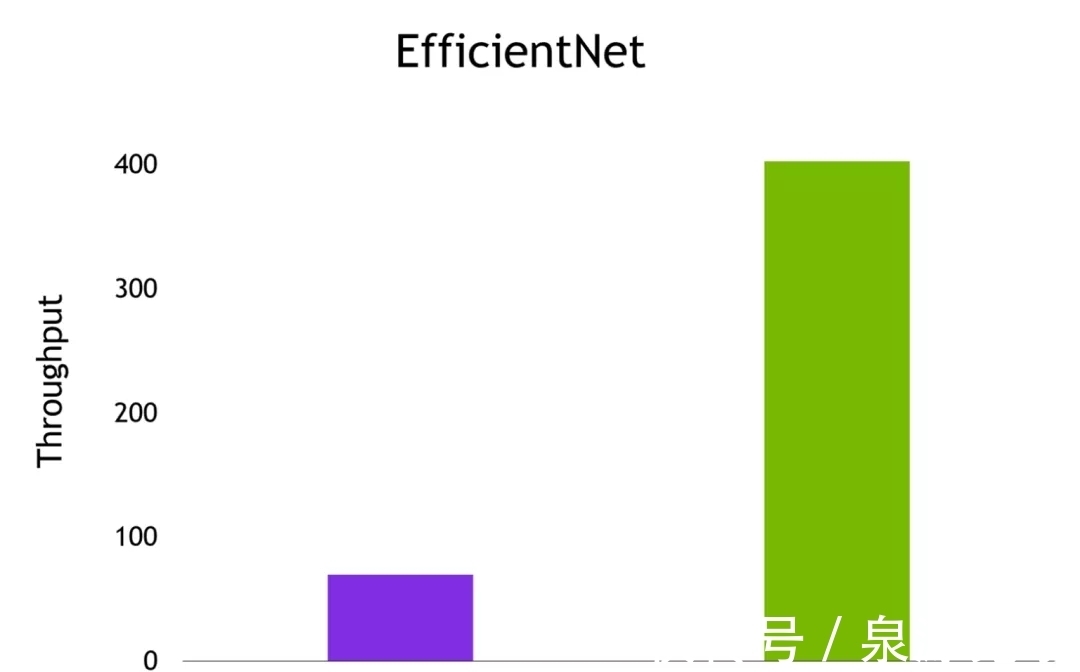
比如,用EfficientNet图像分类模型进行推理,并计算PyTorch模型和经过Torch-TensorRT优化的模型的吞吐量。
以下是在NVIDIA A100 GPU上取得的结果,batch size为1。
- 知乎|电商达人迎来补税大潮,知乎带货第一人,被通知补税34万!
- 央视|央视曝光直播电商以次充好乱象!有平台抽样不合格率达50%
- 能量密度达500Wh/kg!日本开发出新款锂空气电池
- 百度|传英伟达加大GeForce RTX 3050供应力度,大量供货将在春节后到来
- 400亿芯片交易接近尾声,英伟达、ARM表明态度,禁止收购后
- 文和友|泡泡玛特与飞书达成合作 新消费代表企业加速迁移飞书
- 入场券|元宇宙世界的“入场券”?市场规模将达2700亿元!这类人才太紧缺→
- 宋嘉吉|元宇宙世界的“入场券”?市场规模将达2700亿元!这类人才太紧缺
- 军工|中国版“英伟达”诞生,核心技术完全自研,国产替代即将崛起
- 英伟达 RTX 3090 Ti 经销商定价曝光,约 2.2 万元起