met微软亚洲研究院发布高性能MoE库Tutel
IT之家 11 月 27 日消息,据微软亚洲研究院发布,作为目前唯一被证明能够将深度学习模型扩展到万亿以上参数的方法,MoE 能让模型学习更多信息,并为计算机视觉、语音识别、自然语言处理和机器翻译系统等提供支持。近期,微软亚洲研究院发布了一个高性能 MoE 库 ——Tutel,并在 8x 80GB NVIDIA A100 和 8x 200Gbps 的 InfiniBand 网络的 Azure NDm A100 v4 节点上进行了实验。让我们来看一看,这个用于促进大规模 DNN 模型开发的高性能 MoE 库有哪些优势?其表现又如何?
混合专家(Mixture-of-Experts,简称 MoE)是一种深度学习模型架构,其计算成本与参数的数量呈次线性关系,因此更容易扩展。MoE 是目前唯一被证明能够将深度学习模型扩展到万亿以上参数的方法,它能让模型学习更多信息,并为计算机视觉、语音识别、自然语言处理和机器翻译系统等提供支持,从而以全新的方式为人类社会提供帮助。
近日,微软亚洲研究院发布了一个用于促进大规模 DNN 模型开发的高性能 MoE 库 ——Tutel,并针对已普遍使用的新 Azure NDm A100 v4 系列进行了高度优化。借助 Tutel 多样化和灵活的 MoE 算法支持,AI 领域的开发人员可以更轻松、高效地执行 MoE。与最先进的 MoE 实现方式,如 fairseq(Meta 的 Facebook AI 研究院基于 PyTorch 的 Sequence to Sequence 工具包)相比,对于单个 MoE 层,Tutel 在具有 8 个 GPU 的单个 NDm A100 v4 节点上实现了 8.49 倍的加速,在具有 512 个 A100 GPU 的 64 个 NDm A100 v4 节点上实现了 2.75 倍的加速。在端到端性能方面,得益于 all-to-all 通信优化,Tutel 在 Meta(原 Facebook 公司)的 1.1 万亿参数的 MoE 语言模型中使用 64 个 NDm A100 v4 节点实现了 40% 以上的加速。
Tutel 具有良好的兼容性和丰富的功能,确保了其在 Azure NDm A100 v4 群集上运行时可以发挥出色的性能。目前,Tutel 已开源,并已集成到 fairseq 中。
Tutel GitHub 链接:https://github.com/microsoft/tutel
Tutel MoE 的三大优势作为 fairseq、FastMoE 等其他高水平 MoE 解决方案的补充,Tutel 主要专注于优化面向 MoE 的计算和 all-to-all 通信,以及其他多样化和灵活的 MoE 算法支持。Tutel 具有简洁的接口,可以轻松集成到其他 MoE 解决方案中。当然,开发人员也可以从头开始,利用 Tutel 的接口将独立的 MoE 层合并到他们自己的 DNN 模型中,直接从高度优化的、最先进的 MoE 功能中受益。
【 met微软亚洲研究院发布高性能MoE库Tutel】与现有的 MoE 解决方案相比,Tutel 具有以下三个主要优势:
优化面向 MoE 的计算。由于缺乏高效的实现方法,目前基于 MoE 的 DNN 模型依赖于深度学习框架(如 PyTorch、TensorFlow 等)提供的多个现成 DNN 运算符的拼接来组成 MoE 计算。由于需要冗余计算,这种做法会导致显著的性能开销。Tutel 设计并实现了多个高度优化的 GPU 内核,为面向 MoE 的计算提供了运算符。例如,Tute l 将调度“输出选通(gating output)”的时间复杂度从 O (N^3) 降低到 O (N^2),显著提高了数据调度的效率。Tutel 还实现了快速 cumsum-minus-one 运算符(fast cumsum-minus-one operator),与 fairseq 实现方式相比,达到了 24 倍的加速。此外,Tutel 还利用 NVRTC(CUDA C++ 的运行时编译库)进一步实时优化了定制的 MoE 内核。
图 1 对比了 Tutel 与 faireseq 在 Azure NDm A100 v4 平台上的运行结果,如前所述,使用 Tutel 的单个 MoE 层在 8 个 A100 GPU 上实现了 8.49 倍的加速,在 512 个 A100 GPU 上实现了 2.75 倍的加速。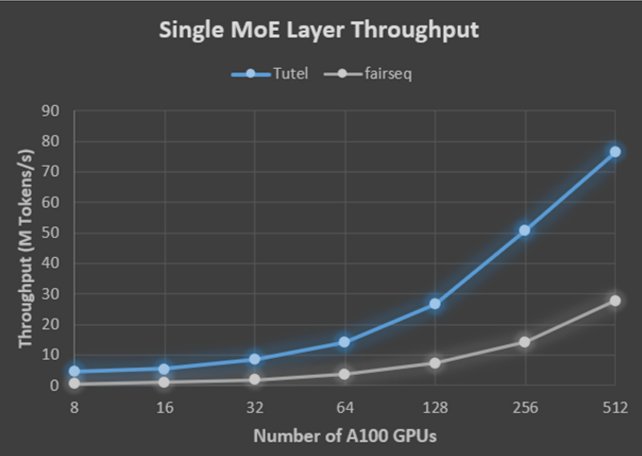
文章插图
图 1:与 fairseq 相比,对于单个 MoE 层,Tutel 在具有 8 个 GPU 的单个 NDm A100 v4 节点上实现了 8.49 倍的加速,在具有 512 个 A100 GPU 的 64 个 NDm A100 v4 节点上实现了 2.75 倍的加速。详细设置为:batch_size = 32, sequence_length = 1,024, Top_K = 2, model_dim = 2,048, ands hidden_size = 2,048
- m都是大片!微软 Skype 支持将必应 Bing 图片设为通话虚拟背景
- 打脸!华为在美国,用专利把英特尔、苹果、微软、高通打败了
- meta|陈根:Meta或将发布新专利,为元宇宙助力
- meta|一个24小时就会自毁的网站,在网友的接力下存活了两年
- Windows|如果美国让微软断供中国windows系统,不会出现什么影响
- 微软 Win11 你的手机 App 更新:圆角外观,界面更简洁
- Oculus|Meta旗下虚拟现实公司Oculus遭反垄断调查
- meta|阿里云到底有多强大?一起来盘点一下它骄人的战绩
- intel公司|苹果芯片总监刚被Intel挖走,技术大咖又跳槽微软
- meta|运用好Facebook组群可以带来哪些好处呢?