meta|Meta:训练AR眼镜的智能助手,需要用第一人称视频
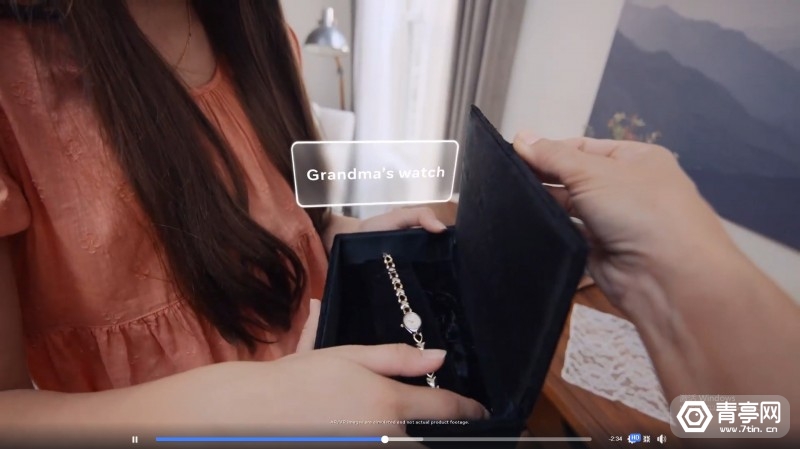
文章图片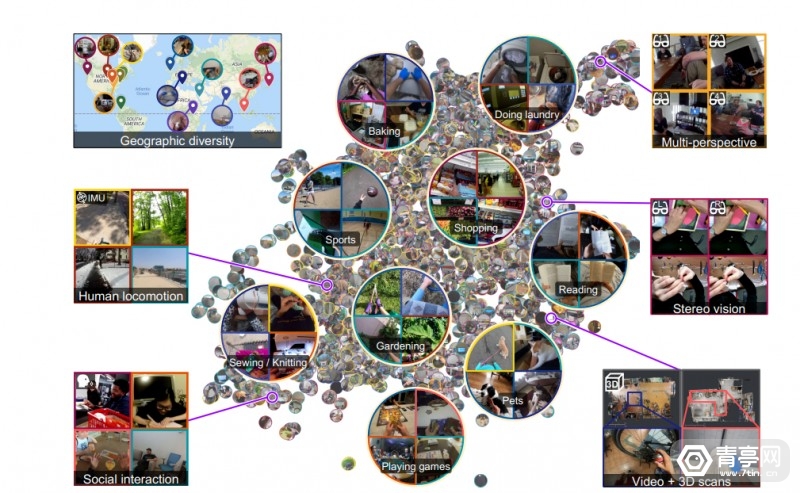
文章图片
文章图片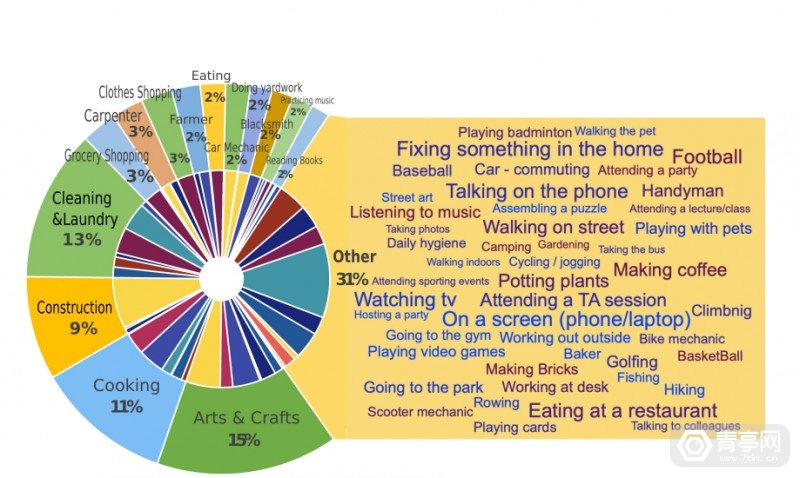
文章图片
文章图片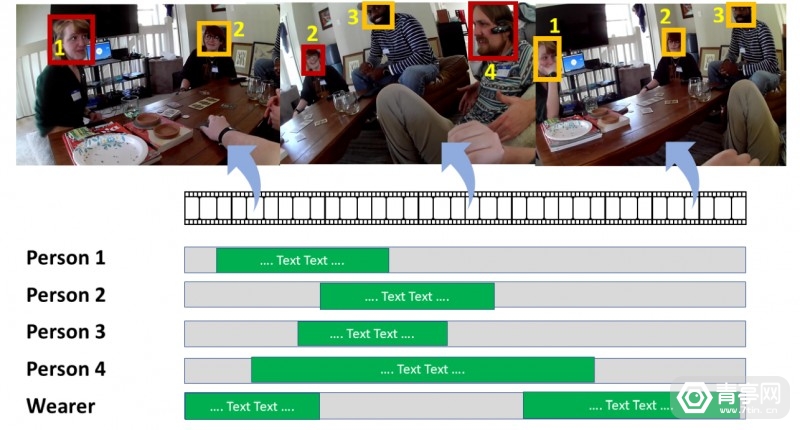
在大多数人印象中 , AR眼镜的主要特征是提供虚实融合的视觉辅助效果 。 实际上 , 与同样基于虚拟技术的VR相比 , AR不仅仅能够看到真实环境 , 它的应用场景和VR也不同 , 因为它可以通过一系列智慧的功能来辅助日常生活、工作和学习 。
此前Meta就曾提出 , AR眼镜将采用支持场景感知的AI算法 , 推算使用者在场景中需要获取的信息 , 以及需要执行的下一步动作 , 接着使用者可以用EMG腕带来进行确认 。 的确 , 穿戴式AR眼镜与智能AI助手结合是必然的结果 , 市面上大多数非AR的智能眼镜已经配备语音助手 , 相比之下AR眼镜需要的不只是语音助手 , 它应该可以通过摄像头来提供智能的视觉辅助 , 就像是科幻电影描述的那样 。
近年来 , 计算机视觉技术已经得到长足发展 , 相关算法可以识别不同类型的物体 , 或是用于手势识别、人脸识别等场景 。 不过 , 目前计算机视觉算法面临的最大难题是 , 它主要是基于第三人称视角的照片和视频训练的 , 因此AI相当于以旁观者的角度去识别周围环境和活动 , 如果将它应用于家用机器人或AR眼镜 , 则需要识别第一人称图像 , 这对基于第三人称数据训练的AI并不友好 。
为了解决上述问题 , Meta近期开源了市面上最大的第一人称视频数据集Ego4D , 视频时长累计3205小时 , 号称是其他同类数据集规模的20多倍 。 据悉 , 该数据集是Meta与全球13所大学合作的成果 , 共耗时2年时间完成 。 另外 , Ego4D数据基于室内和室外场景 , 来源也分布在世界多个国家 , 比如:自沙特阿拉伯、东京、洛杉矶和哥伦比亚等等 。
为何收集第一人称视频
收集了这么多第一人称视角的视频 , 它和第三人称视频有什么区别呢?简单来讲 , 就像是在过山车上看景色 , 和从地面看过山车之间的区别 。
人的大脑可以轻易将第一人称和第三人称视角联系起来 , 而现有的AI技术不支持这样灵活的分析能力 , 因此如果让计算机视觉算法理解过山车上的景色 , 它可能并不能看懂 , 因为训练算法的数据一般是地面上拍摄的第三人称视频 。
【meta|Meta:训练AR眼镜的智能助手,需要用第一人称视频】
AI科研人员Kristen Grauman表示:为了让AI像人一样与周围的环境交互 , 它需要具备第一人称感知能力 , 像人眼一样感知实时运动、交互和多感官视觉 。
而和许多视频数据不同 , Ego4D视频通过头戴摄像头来拍摄 , 因此可以模拟第一人称视角 , 而且它们是一系列动态的活动 , 而不只是一张一张图片 。 因此 , Ego4D的出现有望为第一人称计算机视觉打开新的场景 , 用于穿戴式摄像头、家用机器人助手等设备 , 这些设备将通过第一人称摄像头来理解周围的环境 。
- meta|陈根:Meta或将发布新专利,为元宇宙助力
- meta|一个24小时就会自毁的网站,在网友的接力下存活了两年
- Oculus|Meta旗下虚拟现实公司Oculus遭反垄断调查
- meta|阿里云到底有多强大?一起来盘点一下它骄人的战绩
- meta|运用好Facebook组群可以带来哪些好处呢?
- F被指收集 4400 万用户数据,Facebook 母公司 Meta 面临 32 亿美元索赔
- Meta Quest|旨在提供更佳Quest体验:Valve发布SteamVR Beta 1.21.5
- meta|搞Java怎么玩深度学习,生产环境用DL4J啊
- meta|关键数据出炉,京东比阿里差远了
- meta|Facebook广告投放时,你遇到过这些问题吗?