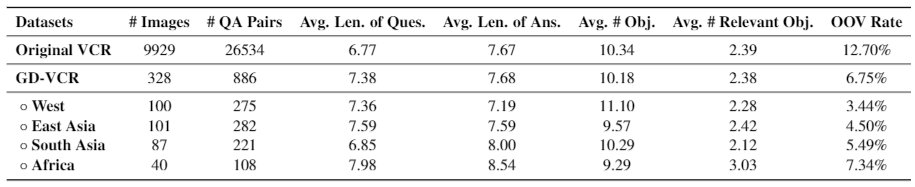
拓展你的视野!UCLEMNLP 2021Or ucla( 二 )
文章插图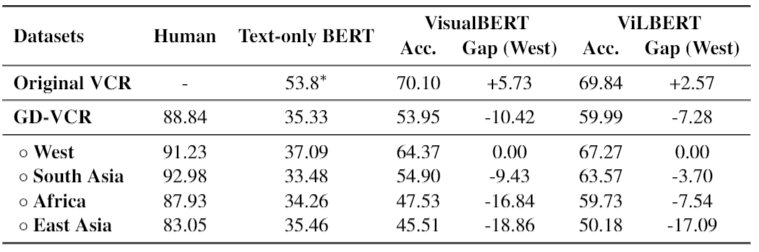
文章插图
我们后面从两个方面分析了产生这种表现差异的原因:
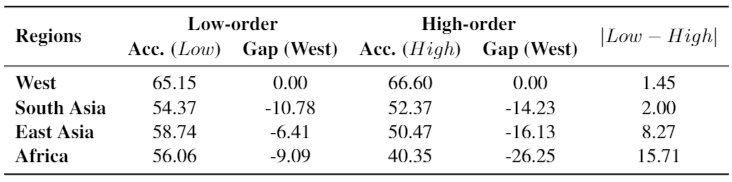
- 具有地区特征的场景:我们在 GD-VCR 中标注了图像的场景标签,所以我们可以借助标签将不同地区同一个场景的图片放在一起进行比较。我们观察到,对于经常涉及地区特征的场景(例如婚礼,节日等),性能差距要大得多,约为8%-24%。但是,对于一些世界上普遍存在且比较相似的场景,模型的性能差距仅为0.4-1.3%。

文章插图
(具有地区特征的场景与其他场景上模型表现差异对比。字体越大表示模型表现差异越大。红色场景差异大于8%,蓝色场景差异小于8%。)
- QA pair 的推理层次:在介绍推理层次之前,我们可以先思考模型什么时候会失败。我们认为可能有2种情景。“情景1”是,模型在早期甚至无法识别非西方图像的基本信息。“情景2”是,模型在基本视觉信息的识别上效果不错,但最终由于缺乏特定区域的常识而最终失败。
文章插图
- 电池|vivoY55s,能有效解决你的续航焦虑!
- 为了你的iPhone能磁吸充电,苹果又花了5亿买材料
- |既能打造你的品牌又能促进销售的广告宣传方法?
- 【e汽车】做更懂你的智能出行伙伴 魏牌举办用户粉丝节
- 王中林院士的拓展麦克斯韦方程,这项成果究竟有多大?
- 微软 Win11 你的手机 App 更新:圆角外观,界面更简洁
- 网易|拼夕夕针对砍价案做出了回应,之所以你砍不中,主要是由于你的手机屏幕太小
- MIUI|MIUI13公测版来了,6大新增功能,让你的手机焕然一新!
- 裁员潮|内容推荐系统:你的文章至少要先让它明白
- 「今日优选」叮咚|「今日优选」叮咚,你的周末零食礼盒已上线