gpu|512张GPU炼出10万亿参数巨模型!这个模型今年双十一已经用上了
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
超大规模的预训练模型的参数量级又双叒被刷爆了!
100000亿!
(没错,是10万亿)
而且还是用512张GPU,训练了10天搞出来的!
文章插图
这就是达摩院最新推出的超大规模通用性人工智能大模型,M6-10T。
它在电商、制造业、文学艺术、科学研究等领域都有着多模态、多任务的能力,在各自现实场景的下游任务中也频频出现。
而且还能做到即开即用,你今年的双十一背后就有M6-10T的身影。
少量资源快速训练大模型不过剁手节的事可以先放一边,问题关键是:M6-10T到底是怎么使用少量资源完成对极限规模模型的训练的?
要知道,之前微软的DeepSpeed MoE模型,也是使用了512张A100才完成了3.5万亿参数的训练。
而自家在5个月前推出的万亿级参数的M6,则是用480块GPU训练的。
所以,512张GPU怎么就放下了10万亿参数?
这就要提到达摩院自研的分布式框架Whale。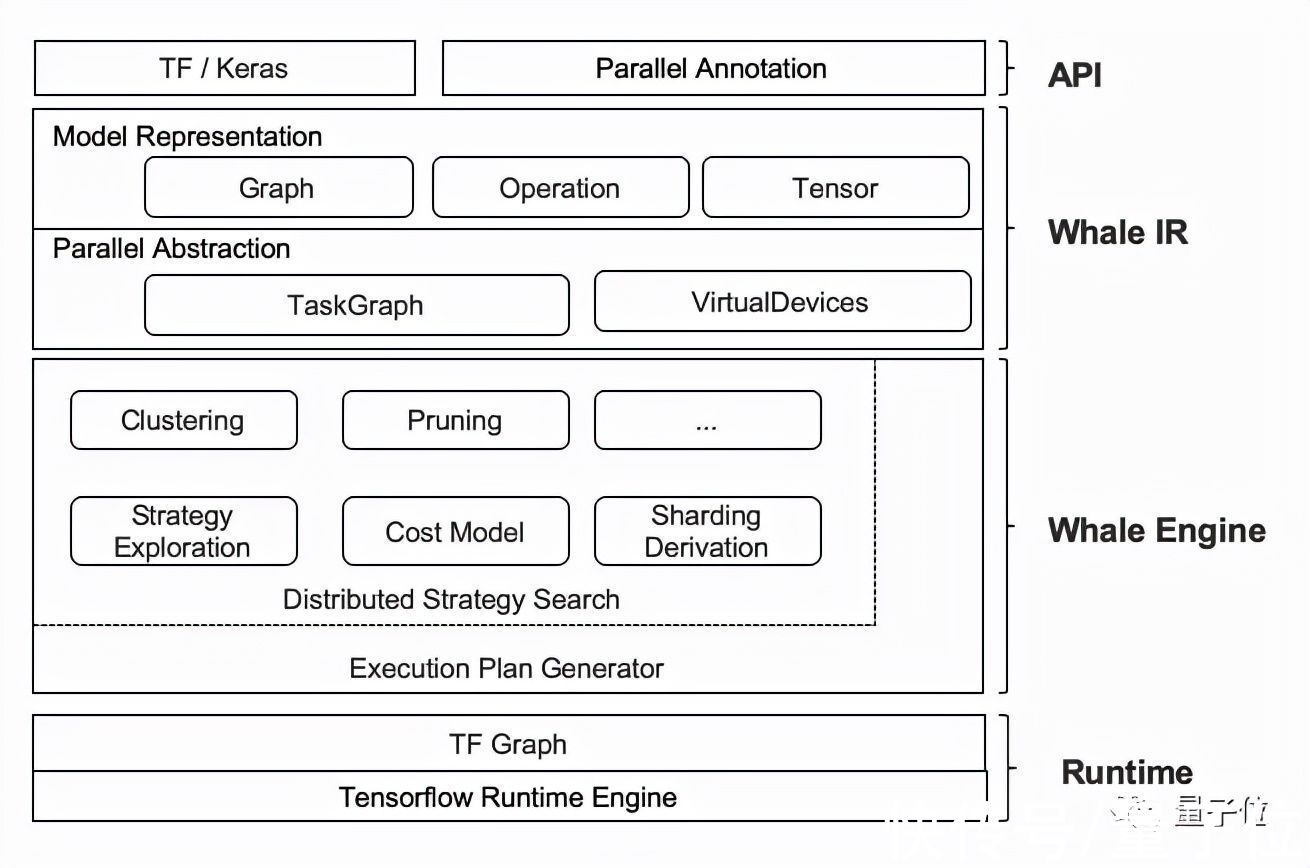
文章插图
基于这一框架,M6模型可以使用粒度可控的CPU offload方法,灵活地选择offload的模型层。
也就是说,可以不用将所有的权重offload到CPU memory中,而选择保留部分权重在GPU memory上进行计算,以进一步地提高GPU利用率。
放下了参数,下一步就是提高训练效率。
M6-10T模型采用了一种叫做共享解除(Pseudo-to-Real)的新的训练策略: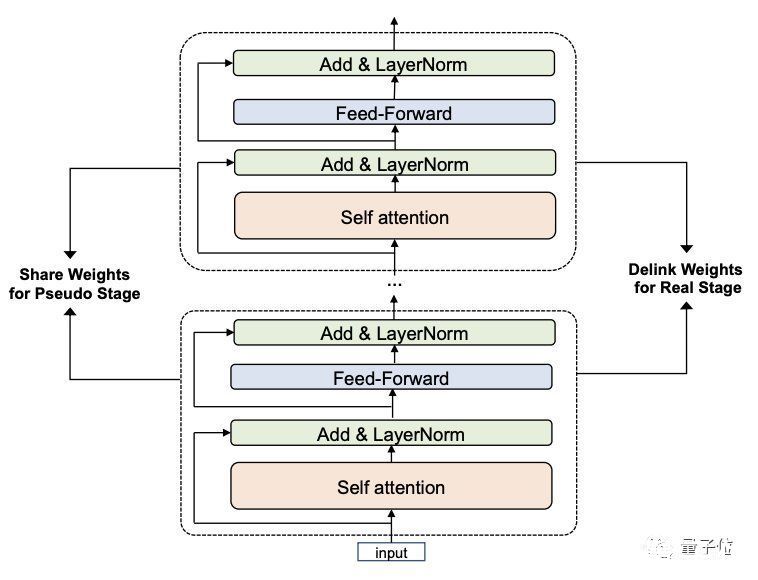
文章插图
这一策略分为两个阶段。
第一阶段,利用跨层参数共享机制快速构建并训练小模型Pseudo Giant。
参数少得多的Pseudo Giant不受内存的限制,因此可以用大批量训练来加速。
再配合上专家拆分和合并的机制,最终只需要使用256张GPU即可快速训练一个Pseudo Giant。
第二阶段则解除共享参数的联系,得到新的Real Giant模型。
“共享”阶段训练好的模型层的参数会为Real Giant的每一层提供初始化,大模型即可在训练好的小模型的基础上继续优化。
在下游评估中可以看到,从头开始训练Real Giant模型非常耗时,而Pseudo Giant训练的收敛速度比Real Giant训练有5倍左右的优势:
文章插图
△在48个NVIDIA V100 GPU设备上训练这一机制不仅能够使M6-10T在样本量的维度上具有更快的收敛速度,也能将模型的训练速度提升7倍以上。
而相对于之前的M6-MoE和M6-T,采用了新的训练策略的M60-10T迷惑度(perplexity)更低,模型更优越: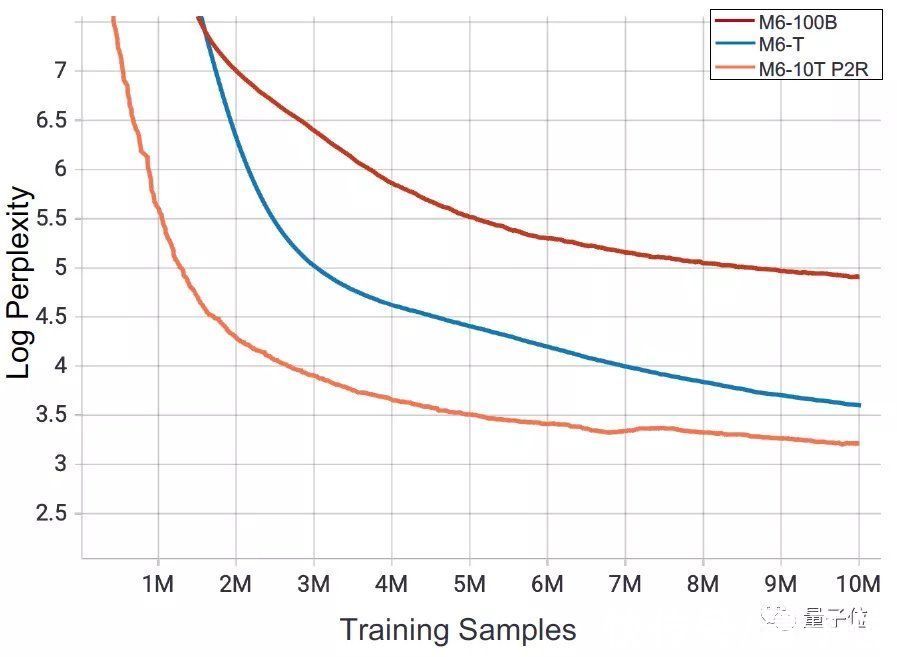
文章插图
可以说,之前使用480GPU的万亿参数模型M6,如果采用现在的方法,那就只需要64张GPU就能完成训练。
双十一背后的模型而除了算法层面的价值,M6-10T一经推出就能够投入使用。
比如说即将来临的双十一中,你或许就能发现这些AI设计款的衣服上架。
文章插图
△基于M6设计生成的服装款式
这就是大模型带来的创造力。
在结合了StyleGAN后,M6能够在少样本情况下自动生成图像,且保持良好的细节质量和可编辑性。
而且与传统的设计款式图不同,M6生成的还是更接近实物的照片效果。
在手机淘宝和支付宝中,也会有基于M6智能生成的内容文案:
文章插图
同时,大模型的多模态特征提取能力,也能进行商品属性标签补充,用于进行认知召回。
- GPU|天玑8000新机快了,相机的配置看上去挺不错,准备冲吗?
- 三星|三星手机Soc搭载AMD Radeon GPU曝光,运行频率超过苹果A15
- gpu|登临科技完成新一轮战略融资,高通创投、光远资本等产业基金持续加持
- GPU|AI计算平台公司“登临科技”完成新一轮战略融资
- gpu|国产 GPU 公司摩尔线程与同方达成合作
- gpu|借鸡生蛋孵化新一代芯片,消息称台积电将为英特尔设3nm专线
- ssd|PCIe 6.0 即将面向未来快速的 SSD 和 GPU
- NVIDIA|14nm显卡性能追上GTX 1050 国产GPU公司景嘉微发2021年财报预告
- 高通新骁龙8加持,GPU性能提升超预期,手机游戏或迎来“次时代”
- AMD|AMD英特尔豪赌GPU 它们真能威胁Nvidia吗?