物体|无需任何标记数据,几张照片就能还原出3D物体结构,自监督学习还能这样用( 二 )
在监督学习所用到的参数上,可用的包括深度、关键点、边界框、多视图4类;而在测试部分,则包括2D转3D、语义和场景3种方式。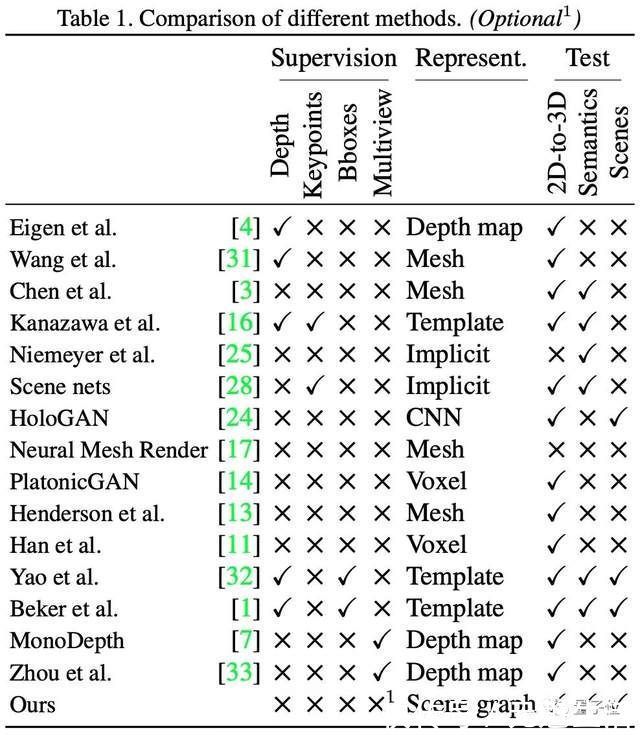
文章插图
可以看见,绝大多数网络都没办法同时实现2D转3D、在还原场景的同时还能包含清晰的语义。即使有两个网络也实现了3种方法,他们也采用了深度和边界框两种参数进行监督,而非完全通过自监督进行模型学习。
这一方法,让模型在不同的数据集上都取得了不错的效果。
无论是椅子、球体数据集,还是字母、光影数据集上,模型训练后生成的各视角照片都挺能打。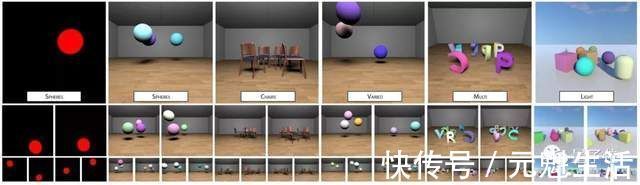
文章插图
甚至自监督的方式,还比加入5%监督(Super5)和10%监督(Super10)的效果都要更好,误差基本更低。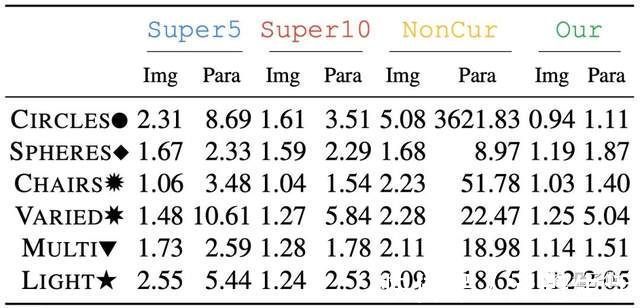
文章插图
而在真实场景上,模型也能还原出照片中的3D物体形状。例如给出一只兔子的照片,在进行自监督训练后,相比于真实照片,模型基本还原出了兔子的形状和颜色。
文章插图
不仅单个物体,场景中的多个3D物体也都能同时被还原出来。
文章插图
当然,这也离不开“好奇心驱动”这种方法的帮助。事实上,仅仅是增加“好奇心驱动”这一部分,就能降低不少参数错误率,原模型(NonCur)与加入好奇心驱动的模型(Our)在不同数据集上相比,错误率平均要高出10%以上。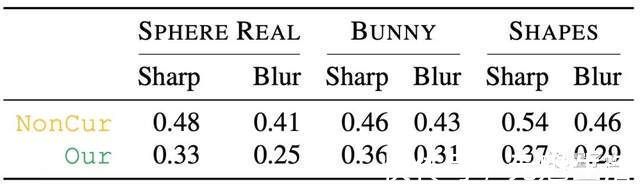
文章插图
不需要任何外部标记,这一模型利用几张照片,就能生成3D关系、还原场景。作者介绍
3位作者都来自伦敦大学学院。
文章插图
一作David Griffiths,目前在UCL读博,研究着眼于开发深度学习模型以了解3D场景,兴趣方向是计算机视觉、机器学习和摄影测量,以及这几个学科的交叉点。
文章插图
Jan Boehm,UCL副教授,主要研究方向是摄影测量、图像理解和机器人技术。Tobias Ritschel,UCL计算机图形学教授,研究方向主要是图像感知、非物理图形学、数据驱动图形学,以及交互式全局光照明算法。
有了这篇论文,设计师出门拍照的话,还能顺便完成3D作业?
- 联想|杨元庆10年薪酬达到了12.6亿,比任何一个国有企业都要牛
- 搜索引擎|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- 零售业|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- 不安装任何杀毒软件|ai如何识破恶意软件?
- NVIDIA|NVIDIA 511.23版驱动带来DLDSR画质技术:无需游戏优化
- 审查|德国监管机构:未发现任何证据表明小米手机具有“审查”功能
- 国外少年发现特斯拉漏洞:无需钥匙可开走 已入侵25辆
- 腾讯|NVIDIA宣布DLDSR AI超分辨率技术:驱动集成、无需游戏优化
- NVIDIA宣布DLDSR AI超分辨率技术:驱动集成、无需游戏优化
- NVIDIA|NVIDIA宣布DLDSR AI超分辨率技术:驱动集成、无需游戏优化