增强|关注数据而不是模型:我是如何赢得吴恩达首届 Data-centric AI 竞赛的( 二 )
文章插图
训练数据集里的一个例子
考虑到最终提交的图像只能小于 10K,因此,参与者必须专注于在缺乏“大数据”的情况下获取“好数据”,这是因为 Andrew 觉得 “大数据” 在更传统的行业(如制造业、农业和医疗保健)的人工智能应用中非常常见。
为了简化这个工作流程,我编写了一个 Python 程序来评估给定的数据集(在将其输入固定模型和训练程序之后),并生成一个包含每个图像记录指标的电子表格。
该电子表格包含给定标签、预测标签(使用固定模型)和每个图像的损失,这对于分离不准确和边缘情况非常有用。下面举例。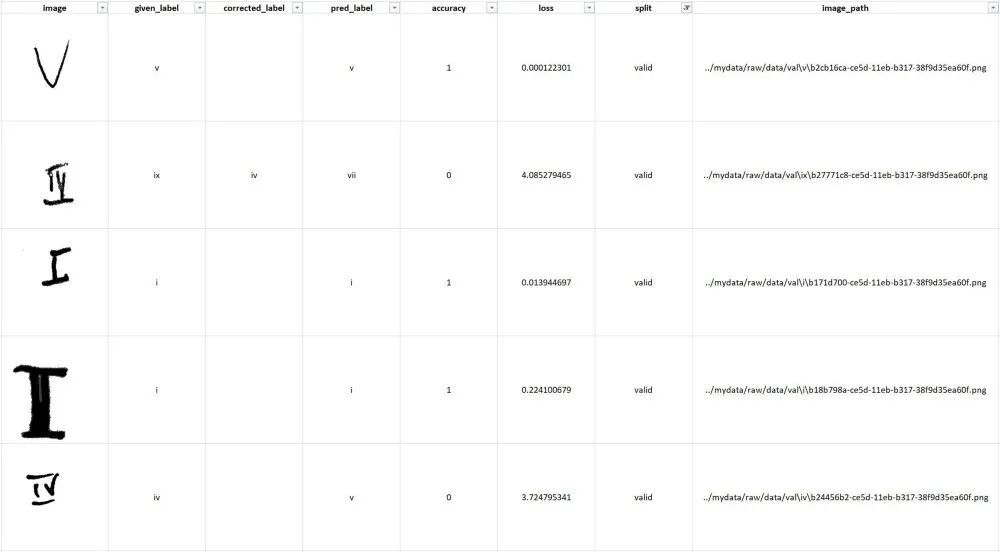
文章插图
由 Python 生成的数据评估电子表格示例,用于简化以数据为中心的 AI 工作流程。
我最初使用这个电子表格来识别标记错误的图像和明显不是罗马数字 1-10 的图像(例如,在原始训练集中就有一个心脏图像)。
现在我们来看看“数据增强”技术。以下是高级步骤:
- 从训练数据中生成一组非常大的随机增强图像(将这些视为“候选”来源)。
- 训练初始模型并预测验证集。
- 使用另一个预训练模型从验证图像和增强图像中提取特征(即嵌入)。
- 对于每个错误分类的验证图像,利用提取的特征从增强图像集中检索最近邻(基于余弦相似度)。将这些最近邻增强图像添加到训练集。我将这个过程称为“数据增强”。
- 使用添加的增强图像重新训练模型并预测验证集。
- 重复步骤 4-6,直到达到 10K 图像的限制。
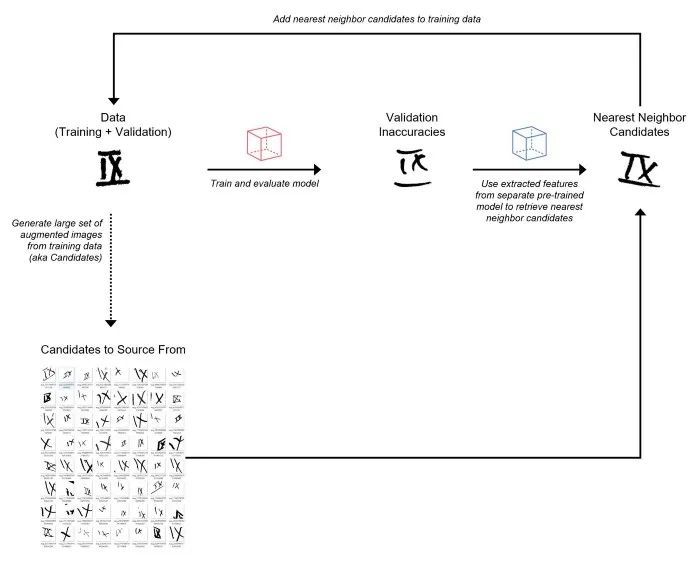
文章插图
将来自训练集的增强图像作为候选源的“数据增强”过程
在“数据增强”过程中需要注意的几点:
- -虽然我在这次竞赛中使用了增强图像,但在实践中我们可以使用任何大的图像集作为数据源。
- -我从训练集中生成了大约 1M 的随机增强图像作为候选来源。
- -数据评估电子表格用于跟踪不准确(错误分类的图像)并注释数据。另外,我还创建了一个带有PostgreSQL 后端的 Label Studio 实例,但由于不必要的开销,我决定不将其用于本次比赛。
- -对于预训练模型,我使用了在 ImageNet 上训练的 ResNet50。
- -我使用 Annoy 包来执行近似最近邻搜索。
- -每个错误分类的验证图像要检索的最近邻的数量是一个超参数。
Annoy 包链接:https://github.com/spotify/annoy
从图像中提取特征的一件很酷的事情是,我们可以使用 UMAP 在 2D 中将它们可视化,以更好地理解训练和验证集的特征空间。在下面的可视化中,我们可以看到,有趣的是,给定的训练数据分布与给定的验证数据不匹配。在特征空间的左下角有一个区域我们没有验证图像。这表明,在运行上面的“数据增强”过程之前,可以尝试重新调整训练和验证数据分割。
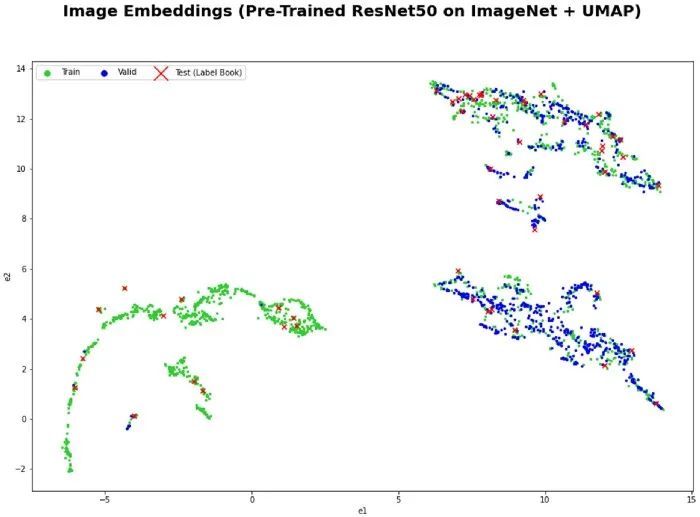
文章插图
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- 财智干货|数智化发展任重道远,财务中台提升数据服务价值 | 大数据
- 央媒表态后,联想关键数据出炉,柳传志这回要扳回一局?
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- 一加科技|父母用机怎么选?抛开价格不谈,最应该关注的应该是这三项配置
- 数据仓库|红米真我moto三款骁龙870手机对比:2000元以内,谁更值得买?
- 中文|爱数智慧CEO张晴晴:基于”情感“的人机交互,要从底层数据开始
- B费全场数据:2次射正打入2球,3次抢断、1次拦截
- iPhone|东芝NAS硬盘N300系列+ORICO硬盘柜=“数据保险柜”