ctr|推荐策略产品经理实操(三):推荐系统与搜索系统的区别——整体逻辑流程对比( 三 )
- 负样本 (曝光不点击):([**0,0,0,1,0,0,**0.12,0.13,0.05, …, ], 0)
- 正样本 (曝光点击):(**[0,0,1,0,0,0,**0.02,0.08,0.13, …, ], 1)
预测时,输入只有特征向量,模型输出一个 0~1 之间的数字,代表预估的 CTR 值,可以用来做排序。所以,建模之后,本质上 CTR 预估问题是一个二分类问题。
这就是其中一个模型的打分逻辑,有多模型打分融合的精排层,会将多个模型的分数进行打分,每个模型的重要性不一样,因此分数都会有权重,将每个模型的分数进行权重计算后相乘在一起,就是这个item的排序分数,每个item按照分数进行从高到底排序,就会得到精排打分列表。
3. 重排(混排/rerank)这一步是推荐的最后一步,每个公司的叫法可能存在差异,有的叫重排,有的叫混排,学术一点叫rerank;虽然也是排序,但重排和粗排或精排最大的区别还是在于这一步更贴近业务需求,产品经理发挥的空间也相对多一些。
做一些强插业务的时候,需要召回配合重排层做,例如做新内容冷启动时,需要给到没有数据的内容一个曝光的机会,这个时候就需要用到重排强插;或者做一些打散逻辑时,例如连续的7个内容中不能有相似内容,或连续的10个内容中最多有2个相似内容等等。
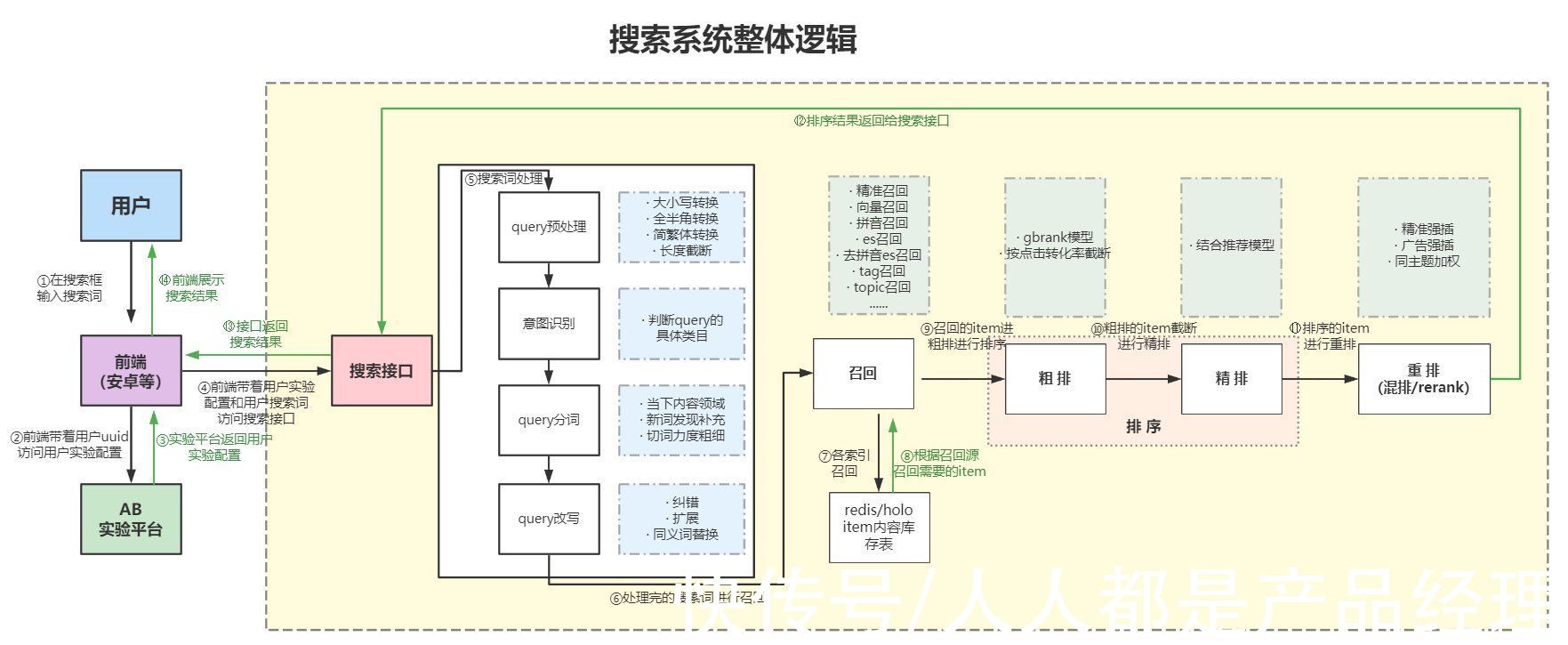
二、搜索系统逻辑当你在搜索框中输入一串搜索词后,页面展示出你想要的结果,但其中的逻辑却是很复杂,这里我认为搜索是比推荐相对复杂的业务:
文章插图
整个流程的重点逻辑也包含了召回、排序、重排,但更为重要的是query处理部分,因为上面详细讲了 召回——排序——重排部分,因此这里不过多讲解,只将重点放在query处理上。
query主要由query预处理、意图识别、query分词、query改写4个部分组成,各公司会依照搜索业务的复杂程度进行部分简化;(query:用户搜索词,例如用户在搜索框输入“秋冬连衣裙女”并点击搜索,那么用户query就是“秋冬连衣裙女”)。
1)query预处理
这一步主要是针对用户在搜索框中输入的搜索词,进行数据清洗。
搜索词基本上都会有长度限制,一种是输入框限制搜索词长度,一种是query预处理的时候进行搜索词截断,例如超过20个字长度的搜索词只截取前20个字。
因为用户输入搜索词的不规范,且不同的用户对同一种诉求的表达往往会存在地域、文化程度以及清晰度的差异,因此会对搜索词进行转化:大小写转换,例如“太空狼人杀3d版”转换为“太空狼人杀3D版”;简繁体转换,例如“太空狼人殺”转换为“太空狼人杀”;还有全半角转换,这里就不再展开过多说明。
query预处理这一步都是根据用户主动输入的搜索词,进行高频query查询检索出的常见问题,针对问题进行本质问题本质解。
2)意图识别
意图识别的本质就是分类问题,主要是根据业务需求进行用户意图分类,分为几个大类,收集每种意图类别下的常用词进行模型训练,模型准确率越高,意图识别效果越好。意图识别在搜索系统中是必不可少的,意图识别在很大程度上决定了用户搜索质量的好坏。
*意图识别的难点:
- 输入不规范;就像上面提到的,不同用户对同一个内容的认知存在差异,输入的搜索词也会存在不小的差异;
- 数据冷启动,用户行为较少数据较少,意图获取会相对没那么准;
- 多意图识别,无法定位精准意图,例如用户搜索“车”,无法知道是想要玩具车还是四轮真车,或者是摩托车;
- 物联网|?内容创作者:要明白文章首先是写给推荐系统看的!
- iPad|ipad平替电容笔推荐;2022最新性价比电容笔推荐
- oppo reno|打算年底前换手机?追求游戏、拍照,我只推荐这款国产手机
- 裁员潮|内容推荐系统:你的文章至少要先让它明白
- CPU|推荐4款千元机,2022年公认“值得买”,好评率95%
- 一加科技|过年回家换新手机推荐哪款?三个理由说服你入手一加10 Pro
- 蓝牙耳机|什么蓝牙运动耳机好? 高性价比蓝牙耳机推荐
- 短视频|互联网广告没有“葬礼”,只是投放策略该变了
- 高通骁龙|千元机最适合的是哪款 目前最值得入手的千元机 我就推荐这四款
- 「1月行情」老旗舰送背刺,599到12999元手机推荐